Digital circuits design methods are considered as a fundamental knowledge base in Informatics, Engineering and Computer Science related study programs. This is because digital circuits constitute the basis of all the digital systems used these days. Knowledge of digital circuits is a basic requirement for the successful study and implementation of the complex technologies and systems, which are built around them. In courses devoted to the design of digital circuits, it is important that students are provided with the capability of verifying their designs with the corresponding experiments. This is particularly useful in teaching introductory engineering courses because the use of hands-on labs in the early years of the study suffers from restricted laboratory capacity and requires student training on the use of laboratory equipment and now due to this covid-19 pandemic it is not possible to visit physical library. Based on the above, the use of educational software tool Logisim together with cloud support provides significant advantages for the teaching of digital circuits, design concepts and computer architecture.
Project Proposal
1. High-level project introduction and performance expectation
Project Name: Logisim 2.0
1. Project Idea :
- Our project is based on digital electronic software. This project is a redesign of old logisim software. So, our idea is that to improve logisim software and make it easy for users. This software is mainly focused on students and some industrial companies.
2. Why we choose this project :
- The older version of logisim software is so simple in design and its UI is very simple in looks so, it feels boring when working on it. Also, sometimes there is confusion happened in its tools(circuit components). So that we decided to redesign this software.
3. Purpose and users of this project :
- This software is useful for designing and simulating the different types of digital logic circuits. So that, user can understand that how the actual circuit will work. This software is mainly useful for students of higher education to understand and gain knowledge of the different types of logic components and circuits. Also, it will help some industrial companies to research logic circuits and making basic blueprints of circuits.
4. Benefits :
- The main benefit of this software is that we can make digital circuits on our computers so that all e-waste of digital circuits (like diodes, plexers, gates, memory components, etc.) will produce less.
5. What we will do :
- In the redesigning of this software, we will make its UI screen with the latest designing method, so that it looks attractive users can easily interact with this software. We will add some interesting features like co-editing, sharing of their work online, notification option, music player so that they can listen to music when they feel bored.
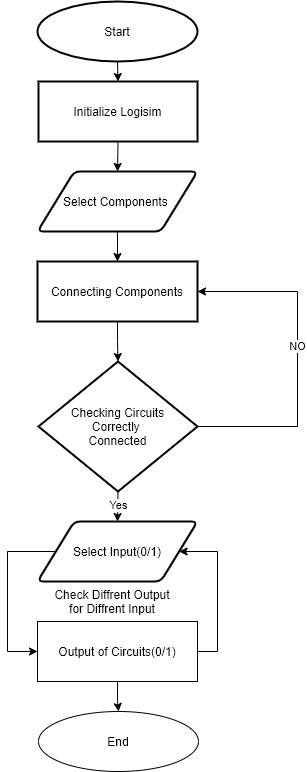
2. Block Diagram
3. Expected sustainability results, projected resource savings
Logisim 2.0
Redesigned new UI with Neomorphism
Changes in UI :
1) New Tool & Help UI
2) Change Menu Experience
.png)
0 Comments
Please login to post a comment.