
The project aims to provide real time counting and monitoring of poultry or livestock which are freed to graze on the farm's grass. Using FPGAs parallel execution, the system will be able to automate the farm operations. With image processing, the farm will also identify and alarm for any predators coming inside the farm such as snakes, lizards or wolves. The system will connect to Microsoft Azure where it sends those head count for real time information to the owner. The system will also connect to cloud services to get the weather conditions and keep the farm animals safe.
Project Proposal
1. High-level project introduction and performance expectation
The main purpose of the project is to provide real time tracking, efficient farm environment conditioning and efficient food and water consumption. The application scope is limited to poulty products where a small interchangeable area is sufficient. The project proposes a method to efficiently reduce the use of resources, area and energy to help minimize the overall environmental impact while providing farmers a sustainable and reliable livelihood. Local farmers and medium scale breeders are the targeted users for this project.
FPGA is the main component used in the project because of the high speed and parallel execution capability of FPGAs which can provide multitasking. With the integration of FPGA in the system, most of the processor extensive tasks such as image processing can be allocated to the processor while maintaining low latency and parallel execution of performance critical subsystems keeping the overall system reliable. Intel FPGA is the preferred choice of hardware because Intel is very popular together with it's Quartus software and tools which are free and easy to use. Intel also provides tantamount of online resources and reference designs for a beginner to accelerate his learning.
2. Block Diagram
I. Refer to attachment on the top level block diagram.
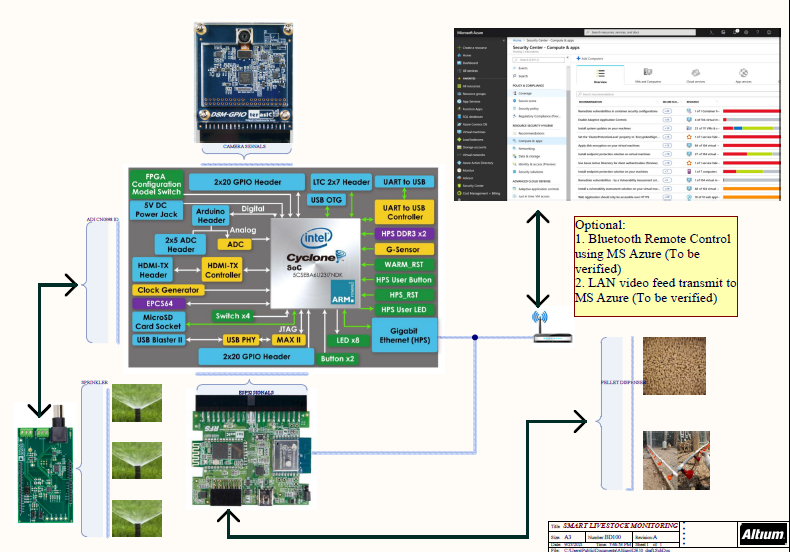
3. Expected sustainability results, projected resource savings
The design have several advantages over the traditional way of breeding. The advantages include but are not limited to: live tracking and status measurement, productive feeder system, efficient use of area and automated dispensing of vitamins/immunization which will result to reduced sickness and diseases.
The use of an FPGA makes possible for the high speed automation with parallel execution of the critical subsystems in the design. With the pin assignment flexibility of FPGAs, the design implementation and configuration is much faster compared to ASICS or microcontrollers. FPGAs comes with softcore IPs which are readily available and makes implementation much faster.
I. LIVE TRACKING SYSTEM
- The system will monitor and identify the quantity of the livestock inside the area. This live monitoring ensures there are no missing or dead flock. Any missing or dead flocks maybe due to predation, disease, starvation or escaping from the farm due to broken fences. Each of these needs to be addressed right away to avoid or minimize losses. Traditional system losses 10% to 20% in predation, 50% or more to disease if uncontrolled and 10% to getting out from the farm due to broken fences. This new system will avoid or reduce these losses.
II. PRODUCTIVE FEEDER SYSTEM
- With the efficient use of feeder system, a diet system can be realized and livestock growth can be optimized while avoid wastages. Traditional system has a 10% to 20% of the pellets ending becoming wasted due to overdispensing and 10% to 20% missed scheduled food dispensing leading to impoverished and slow growth. This system will eliminate these wastage.
III. EFFICIENT USE OF AREA AND SCHEDULING
- The area will be much more effectively used compared to traditional system as the system will be able to condition the environment for the right temperature and moisture, provide enough space for feeding and drinking with automated dispensing and a time for the grass to grow and cultivate.
IV. AUTOMATED DISPENSING OF VITAMINS AND IMMUNIZATION
- With PID controls, the right amount of feeds will be administered together with a planned vitamins or boosters ensuring the livestock will be kept strong and healthy.
V. REDUCED LABOR AND MAINTENANCE
- With most of the functions automated by the system, 90% of the labor is reduced.
4. Design Introduction
The design is centered into automating the livestock farm making it an autonomous and sustainable system. The farm is intended to function on its own while providing the optimum growth to the livestock minimizing the resources while optiming returns.
The targeted users are local farmers, medium to large breeders who utilize grass grazing or small area to grow their livestock..
Intel FPGA devices are used in the design because of the popularity of intel, the easily accessible and available deisgn resources online and a good customer support.
Below is the top level block diagram of the design.
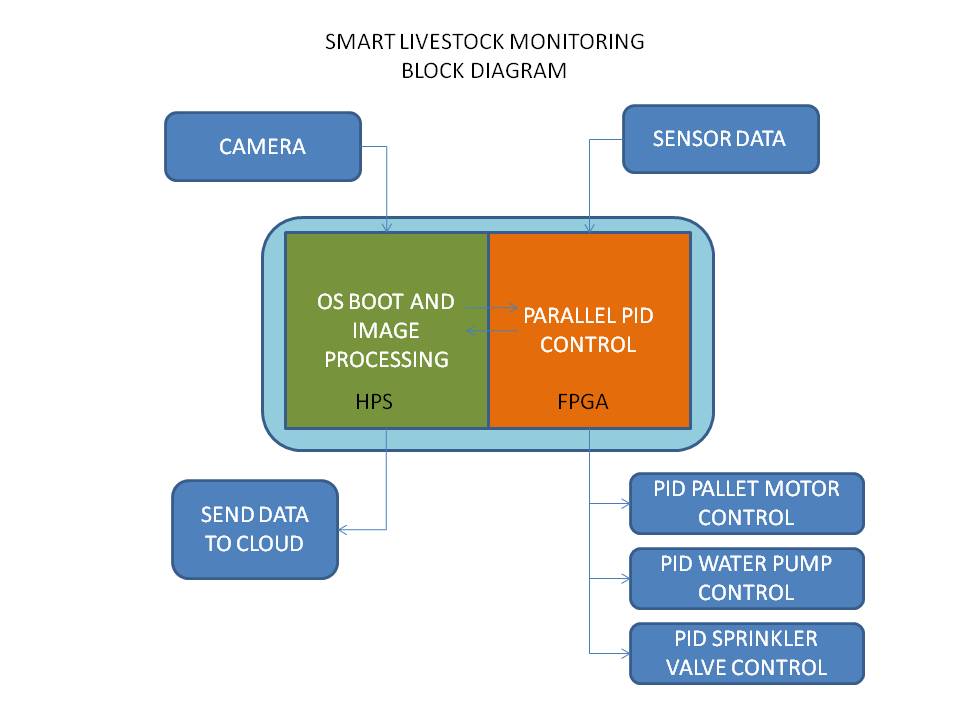
5. Functional description and implementation
The design will function as an automated system capable of providing each and every need of efficiently and economically growing livestock. This autonomous system will be implemented with the use of an FPGA for critical subsystem implementation and a Cortex A9 processor for live tracking.
The critical subsystem is composed of the pellet dispenser system, sprinkler system and water dispensing system and area scheduler. Each of this subsystem is vital to the growth of the livestock. Sensors and actuators will also be used together for the implementation of the control system.
The camera is selected for image processing with opencv. The processor will be boot via linux.
An ADI CN0398 daughter board will be used to collect soil ph and moisture data for area conditioning and scheduling. The 6 available IO on the daughter card will be used for sprinker control.
An RFS ESP-WROOM-02 is also used for sending sensor data into the microsoft azure cloud for monitoring, analysis and future improvements. The 2x6 GPIO will be used for pellet dispensing and water feeder. The pellet dispensing will utilize a 3-axis servo motor with strain gauge for the accurate pellet quantity. The water feeder system will use a pressure sensor and a peristaltic pump to keep the pressure optimum at all times.
An interface power supply distribution board will be prepared to power the different sub-systems.
The draft design implementation is done below.
6. Performance metrics, performance to expectation
The performance parameters that the design is intended to achieve are the following:
I. LIVE TRACKING SYSTEM
- 90% reduction in livestock losses due to predation, sickness, malnutrition and or missing.
II. PRODUCTIVE FEEDER SYSTEM AND DISPENSING
- 30% cost reduction in resources such as pellets, vitamins, boosters, immunization and de-worming.
III. EFFICIENT USE OF AREA AND SCHEDULING
- 50% improvement in area utilization by providing flock area scheduling and area conditioning.
IV. REDUCTION IN LABOR AND MAINTENANCE
- 75% of the labor will be removed because it is now being converted into automation. The system will also benefit from avoiding human error.
7. Sustainability results, resource savings achieved
I. DESIGN SCHEME
-
IMAGE PROCESSING CONCEPT
-
Images will be captured using Terasic's D8M camera which is compatible to DE10 board. The camera will be located in the farm yard where it will be able to view the whole 25sqm lot. This camera's 1408 x 792 resolution at 60 fps together with focus control will provide sufficient image clarity for object identification. The ARM Cortex A9 processor will be boot with Linux and image processing will be using OpenCV.
-
SENSOR DATA ACQUISITION AND MOTOR CONTROL
- The design will use EVAL-CN0398-ARDZ which will measure soil PH, moisture and temperature of the yard for sprinkler FPGA PID control. This will provide the farm with just the right temperature whole day keeping the area moist and cool. Sprinklers will be actuated using 12V solenoid valves which is driven using FR1205 (4 channel relay modules with optocoupler) from FPGA through the P3 connector of EVAL-CN0398-ARDZ.
- The design will use strain gauge to measure the pellet dispensing for FPGA PID control. A 3 axis stepper system using allegro A4988 will drive the stepper motors to rotate a cone shaped dispenser, a cup pellet dropper and a pipe distributor. This system will mantain sufficient food dispensing in a regular schedule optimizing flock growth.
- The design will use water pressure sensor to measure the water inside the feeder tubes for FPGA PID control. This water feeder system will use a peristaltic pump to maintain optimum pressure for best dispensing response.
- All of the FPGA PID control will use finite state machine design and will work independently with the processor.
- MICROSOFT AZURE IOT HUB
- The design will utilize Microsoft Azure IOT Hub to collect and display farm status in real time. Microsoft Azure will also be used for later improvement such as pellet consumption calculation and heat conditions.
II. HARDWARE DESIGN BLOCK DIAGRAM - please refer to Figure 1.
III. SOFTWARE FLOW - please refer to Figure 2.
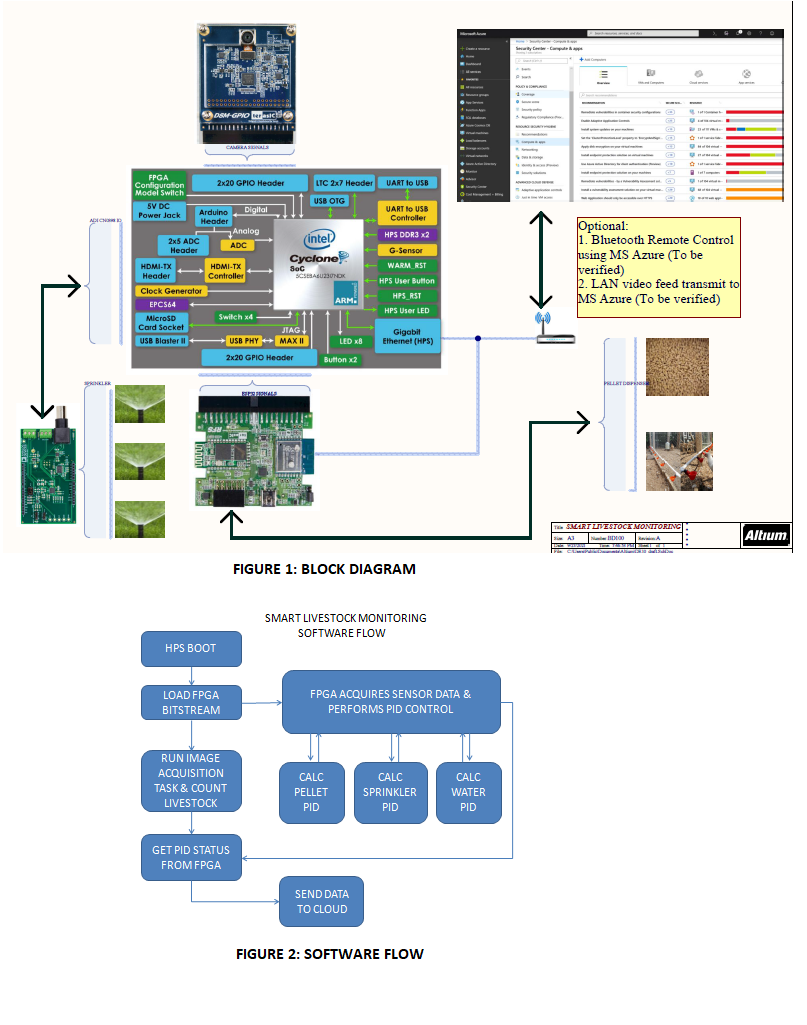
8. Conclusion
Conclusion
Livestock as one of the most important source of food in the world has become affected with the changing climate and temperature. Frequent change of sudden heavy rains causing temperatures to go low or too hot causing humidity to go high has a great impact to fowl and livestock health as well as the environment they are being raised.
To provide solution to these problems a monitoring system was developed to provide heating, cooling and or ventilation during such events. The use of an FPGA was very important as it makes the system efficient and complete operating only from this board and not needing a PC.
Microsoft Azure usage was also found to have provided the cloud data monitoring required to manage several farm operations.
I thank Terasic and all it's partners for this opportunity to be involved into the contest.
0 Comments
Please login to post a comment.