COMPUTED tomography (CT) is a commonly used methodology that produces 3D images of patients. It allows doctors to non-invasively diagnose various medical problems such as tumors, internal bleeding, and complex fractures. However, high radiation exposure from CT scans raises serious concerns about safety. This has triggered the development of low-dose compressive sensing-based CT algorithms. Instead of traditional algorithms such as the filtered back projection (FBP) , iterative algorithms such as expectation maximization (EM) are used to obtain a quality image with considerably less radiation exposure.
In this proposed work we present a complete and working CT reconstruction system implemented on a server-class node with FPGA coprocessors. It incorporates several FPGA-friendly techniques for acceleration. The contributions of the proposed work includes:
• Ray-driven voxel-tile parallel approach: This approach exploits the computational simplicity of the ray-driven approach, while taking advantage of both ray and voxel data reuse. Both the race condition and the bank conflict problems are completely removed. Also easily increase the degree of parallelism with adjustment of tile shape.
• Variable throughput matching optimization: Strategies to increase the performance for designs that have a variable and disproportionate throughput rate between processing elements. In particular, the logic consumption is reduced by exploiting the low complexity of frequently computed parts of the ray-driven approach. The logic usage is further reduced by using small granularity PEs and module reuse.
• Offline memory analysis for irregular access patterns in the ray-driven approach: To efficiently tile the voxel for irregular memory access, an offline memory analysis technique is proposed. It exploits the input data independence property of the CT machine and also a compact storage format is presented.
• Customized PE architecture:
We present a design that achieves high throughput and logic reuse for each PE.
• Design flow for rapid hardware-software design:
A flow is presented to generate hardware and software for various CT parameters. In this work we adapt the parallelization scheme, offline memory analysis technique, variable throughput optimization, and the automated design flow. Hence the new optimization would be expected to be much faster than earlier model with same dataset.
Project Proposal
1. High-level project introduction and performance expectation
Introduction :
Reducing radiation doses is one of the key concerns in computed tomography (CT) based 3D reconstruction. Although iterative method such as the expectation maximization (EM) algorithm can be used to address this issue. Our goal is to decrease this long execution time to an order of a few minutes, so that low-dose 3D reconstruction can be performed even in time critical events. Hence a novel parallel scheme that takes advantage of numerous block RAMs on field-programmable gate arrays (FPGAs) and a customized processing engine based on the FPGA is presented to increase overall through put while reducing the logic consumption. Finally, a hardware and software flow is proposed to quickly construct a design for various CT machines.
In a CT scan, radiation from the source penetrates the patient’s body and gets measured by an array of detectors. The source and the detector array proceed in a helical fashion, where the pair move in a circular direction in the x-y plane and in a lateral direction along the z-axis.
Application : Aim is to construct an automatic lung cancer screening system
The proposed work will be implemented and the Intel FPGA platform is selected because of the high coprocessor memory bandwidth and efficient scatter-gather memory access capability of the coprocessor memory controller. Also FPGA supports a feature of cache-coherent shared memory space which eases development.
2. Block Diagram
Block diagram of proposed system is as shown in figure 1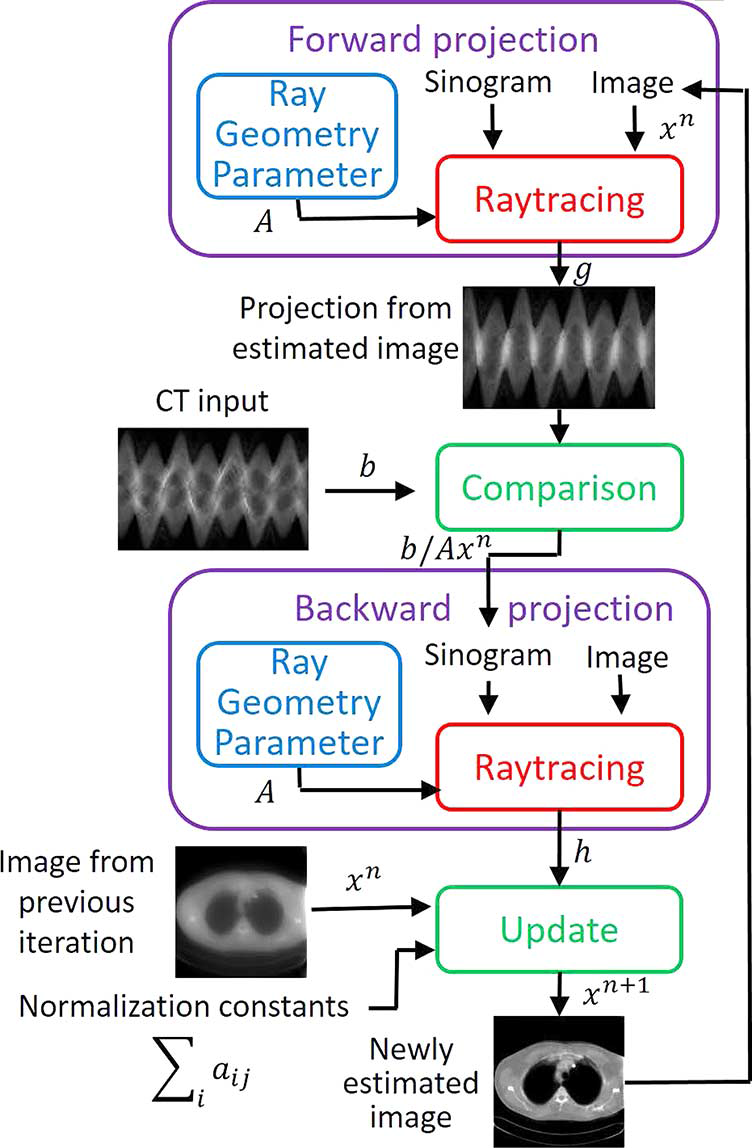
3. Expected sustainability results, projected resource savings
Expected results:
1.Performance to be measured on an actual execution,DRAM bandwidth
2) Effect of the Proposed Parallel Approach
3)Scalability Test:
4)Performance With Various CT Parameters
5)Resource and Power Consumption
6)Accuracy in terms of quantization error on subsequent detection algorithm.
4. Design Introduction
Design Introduction
Many diagnostic imaging techniques, including ultrasound imaging, magnetic resonance (MR) and computed tomography (CT), have gained widespread acceptance in several fields of medicine. In spite of the concern related to the patient dose, CT imaging has become a “cannot-do-without tool” in many branches of medicine.
COMPUTED tomography (CT) is a commonly used methodology that produces 3D images of patients. It allows doctors to non-invasively diagnose various medical problems such as tumors, internal bleeding, and complex fractures. However, high radiation exposure from CT scans raises serious concerns about safety. This has triggered the development of low-dose compressive sensing-based CT algorithms. Instead of traditional algorithms such as the filtered back projection (FBP) , iterative algorithms such as expectation maximization (EM) are used to obtain a quality image with considerably less radiation exposure.
In this proposed work we present a complete and working CT reconstruction system implemented on a server-class node with FPGA coprocessors. It incorporates several FPGA-friendly techniques for acceleration. The contributions of the proposed work includes:
• Ray-driven voxel-tile parallel approach: This approach exploits the computational simplicity of the ray-driven approach, while taking advantage of both ray and voxel data reuse. Both the race condition and the bank conflict problems are completely removed. Also easily increase the degree of parallelism with adjustment of tile shape.
• Variable throughput matching optimization: Strategies to increase the performance for designs that have a variable and disproportionate throughput rate between processing elements. In particular, the logic consumption is reduced by exploiting the low complexity of frequently computed parts of the ray-driven approach. The logic usage is further reduced by using small granularity PEs and module reuse.
• Offline memory analysis for irregular access patterns in the ray-driven approach: To efficiently tile the voxel for irregular memory access, an offline memory analysis technique is proposed. It exploits the input data independence property of the CT machine and also a compact storage format is presented.
• Customized PE architecture:
We present a design that achieves high throughput and logic reuse for each PE.
• Design flow for rapid hardware-software design:
A flow is presented to generate hardware and software for various CT parameters. In this work we adapt the parallelization scheme, offline memory analysis technique, variable throughput optimization, and the automated design flow. Hence the new optimization would be expected to be much faster than earlier model with same dataset.
5. Functional description and implementation
Function Description :
A novel parallel scheme that takes advantage of numerous block RAMs on field-programmable gate arrays (FPGAs)and an external memory bandwidth reduction strategy is presented to reuse both the sinogram and the voxel intensity. A customized processing engine based on the FPGA is considered in this work to increase overall throughput while reducing the logic consumption. Finally, a hardware and software flow is proposed to quickly construct a design for various CT machines.
The complete reconstruction system is implemented on an FPGA based server-class node with FPGA coprocessors.Several FPGA-friendly techniques for acceleration are considered here.
The contributions of the proposed work includes:
• Ray-driven voxel-tile parallel approach: This approach exploits the computational simplicity of the ray-driven approach, while taking advantage of both ray and voxel data reuse. Both the race condition and the bank conflict problems are completely removed. Also easily increase the degree of parallelism with adjustment of tile shape.
• Variable throughput matching optimization: Strategies to increase the performance for designs that have a variable and disproportionate throughput rate between processing elements. In particular, the logic consumption is reduced by exploiting the low complexity of frequently computed parts of the ray-driven approach. The logic usage is further reduced by using small granularity PEs and module reuse.
• Offline memory analysis for irregular access patterns in the ray-driven approach: To efficiently tile the voxel for irregular memory access, an offline memory analysis technique is proposed. It exploits the input data independence property of the CT machine and also a compact storage format is presented.
• Customized PE architecture:
We present a design that achieves high throughput and logic reuse for each PE.
• Design flow for rapid hardware-software design:
A flow is presented to generate hardware and software for various CT parameters. In this work we adapt the parallelization scheme, offline memory analysis technique, variable throughput optimization, and the automated design flow. Hence the new optimization would be expected to be much faster than earlier model with same dataset.
Figure 2 Block diagram of the Proposed System Architecture
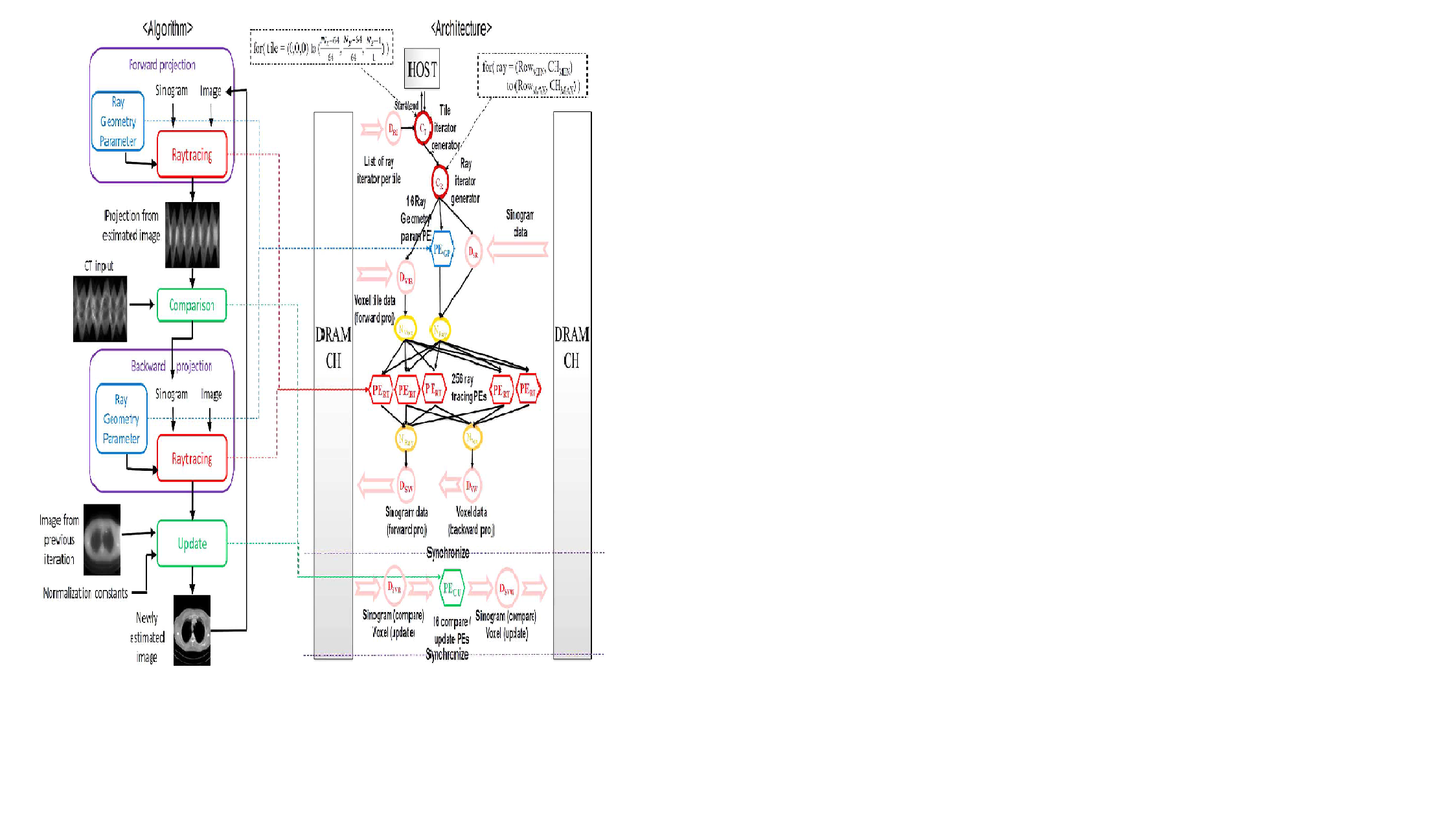
6. Performance metrics, performance to expectation
Performance:
1)The acceleration of the EM algorithm is acheived on the FPGA platform.
2)Parallelizing ray-driven voxel tiles can solve the access conflict problem and
Increase memory bandwidth.
3)Reusing sinogram and voxel can largely reduce external memory access.
4)Optimization based on offline analysis can be performed to exploit the fact that
memory access is independent of the input patient data.
5)A customized PE architecture and optimization strategies to be used increase the system throughput.
6)The combination of an efficient local data transfer scheme and task pipelining can lead to a large speedup in FPGA-based design.
The proposed system can outperform other parallel platforms and achieve a desired speedup.
7. Sustainability results, resource savings achieved
Overall Design Flow
1)Proposed design is based on an assumption that even though the patient changes, the CT scan parameter will not vary much which helps engineers to optimize the design offline.
2)A possible usage scenario is that the CT machine will provide some limited number of FPGA-acceleration settings that are most frequently used.
3)Radiologists can choose one of these settings and quickly obtain the reconstructed result.
4)The overall design flow is shown in Fig. 7. The software analyser will record the memory access pattern into a file and provide guidelines on the hardware architecture.
5)The hardware design, written in C, is then fed into the HLS tool to generate an RTL design.
6)The RTL files are then combined with the host and the DRAM interface RTL. Next, the bitstream is created tool.
7)The host software performs necessary pre- and post-processing such as reading the ray list information or reading and writing the image file.
The Block diagram of Software and hardware design flow ,for the proposed system architecture is as shown below in figure 3.
Figure 3 :Block diagram of Software and hardware design flow

8. Conclusion
0 Comments
Please login to post a comment.