Distinct metamodels of Smart Cities have been developed in order to solve the problems of cities in relation to different socioeconomic indicators. In view of the foregoing, information security plays an important role in guaranteeing human rights in contemporary society. From an infection by malware (malicious + software), a person or institution can suffer irrecoverable losses. As for a person, bank passwords, social networks, intimate photos or videos can be shared across the world wide web, which will affect finances, dignity and mental health. On the other side, an institution may have its vital data inaccessible and/or information from its respective customers and employees stolen. In synthesis, the theft of intimate information can lead to cases of depression, suicide and other mental disorders.
The proposed work investigates 86 commercial antiviruses. About 17% of the antiviruses did not recognize the existence of the malicious samples analyzed. Commercial antiviruses, which, even with billionaire revenue, have low effectiveness and have been criticized by incident researchers for more than a decade. Commercial antiviruses performance is based on signatures when the suspect executable is compared to a blacklist made from previous reports (and this requires that there have already had victims). Blacklists are assumed to be effectively null by the current worldwide rate of creation of virtual pests, that is 8 (eight) new malwares per second. We concluded that malwares have the ability to deceive antiviruses and other cyber-surveillance mechanisms
In order to overcome the limitations of commercial antiviruses, this project creates a core processor-based antivirus able to identify the modus operandi of a malware application before it is even executed by the user. So, our goal is to propose an antivirus, endowed with artificial intelligence, able to identify malwares through models based on fast training and high-performance neural networks. Our core processor-based antivirus is equipped with an authorial Extreme Learning Machine.
Our processor achieves an average accuracy of 99.80% in the discrimination between benign and malware executables. Preliminary results indicate that the authorial Coprocessor, built on FPGA, can speed up the response time of the proposed antivirus by about 4765 times compared to the CPU implementation employing the same FPGA. Thus, the malicious intent of the malware is preemptively detected even when executed on a slow (low processing power) device. Our antivirus enables high performance, large capacity of parallelism, and simple, low-power architecture with low power consumption. We concluded that our solution assists the main requirements for the proper operation and confection of an antivirus in hardware.
Demo Video
Project Proposal
1. High-level project introduction and performance expectation
Distinct metamodels of Smart Cities have been developed in order to solve the problems of cities in relation to different socioeconomic indicators. In order to guarantee human rights, information security plays an important role in contemporary society. From an infection by malware (malicious + software), a person or institution can suffer irrecoverable losses. As for a person, bank passwords, social networks, intimate photos or videos can be shared across the world wide web, which will affect finances, dignity and mental health. On the other side, an institution may have its vital data inaccessible and/or information from its respective customers and employees stolen. In synthesis, the theft of intimate information can lead to cases of depression, suicide and other mental disorders.
Increasingly, companies have been investing in digital security as new technologies in antivirus, firewall and biometrics devices in order to avoid cyber-attacks [1]. Despite the efforts and investments, cyber-attacks have been causing billions of damages and in increasing order [1]. One of the reasons for the failure of commercial antiviruses is that cyber-attacks commonly add Social Engineering. In computational fields, Social Engineering has as its strategy the propagation of false identities, usually as misuse of personal or organizational information of trustworthy entities. In addition, Social Engineering is able to manipulate the victim's feelings to the point of disabling/ignoring the antivirus's work.
Beyond vulnerability in relation to Social Engineering, the modus operandi of commercial antivirus is extremely backward because it is based on blacklists. In synthesis, the suspect executable is compared to a blacklist made from previous reports (and this requires that there have already had victims). Blacklists are assumed to be effectively null by the current worldwide rate of creation of virtual pests, which is 8 (eight) new malware per second [2]. The proposed work investigates 86 commercial antiviruses [3]. About 17% of the antiviruses did not recognize the existence of the analyzed malicious samples. It should be noted that malware, belonging to our database, are in the public domain, widely used in malicious activities and with their actions widely disseminated in forums, blogs and other online content. Even so, 17% of the evaluated commercial antiviruses do not recognize their existence [3].
Limited mechanisms by digital surveillance can be suppressed by artificial intelligence techniques based on neural networks. The suspect applicative goes through a disassembly process in order to extract features from its file. So, the suspect app can be studied, and it's possible to search for malicious intentions on the file. The goal is to cluster the executables into two classes: benign and malware. As a side effect, the antivirus based on neural networks can use a long response time. And worse, conventional neural networks have a low capacity for parallelism because their processing layers are sequential. Therefore, a layer can only be executed after the immediately preceding layer is finished.
The absence of data processing parallelism can be an obstacle in solutions that need a fast response time in order to prevent irreversible damage, such as antivirus. The conventional constraints networks can be overcome by our authorial network: the morphological extreme neural network. It has a single hidden layer and isn't iterative. Our coprocessor-based antivirus implements our authorial neural network and it is prototyped on Intel/Altera FPGA. Preliminary results indicate that our antivirus is faster than a blink of an eye due to the multiprocessing of data. Our antivirus is able to identify the modus operandi of a malware application before it is even executed by the user.
Our coprocessor-based antivirus achieves an average performance of 99.76% in the discrimination between benign and malware executables. In addition, there is no way for the user to disable/bypass the work of our coprocessor-based antivirus, unlike desktop application-level antivirus. Being developed in a hardware architecture-level abstraction layer, our coprocessor-based antivirus is insensitive to Social Engineering attacks and/or Operating System corruption.
[1] Microsoft Computing Safety Index (MCSI) Worldwide Results Summary.
[2] INTEL. McAfee Labs: Threat Report. Available in: https://www.mcafee.com/ca/resources/reports/rp-quarterly-threats-mar-2018.pdf. Accessed in February 2018.
[3] REWEMA: Retrieval Applied to Malware Analysis. Available in: https://github.com/rewema/. Accessed on February 2022.
2. Block Diagram
Information Security is a challenge due to the volume of malicious applications. Any commercial antivirus has its respective blacklist containing millions of samples. The modus operandi of querying for suspect applications in blacklists can be prohibitive as it could cost days, perhaps months. It should be noted that the comparison between suspect application and the antivirus blacklist may become impractical because millions of malware are created annually. Thus, artificial intelligence is capable of overcoming the limitations of commercial antiviruses both in terms of accuracy and response time. Unlike blacklist, our malware detection is done by auditing suspicious behavior previously cataloged during the learning process (training).
Our malware detection is based on artificial intelligence, specifically, artificial neural networks. Our authorial neural network has a single hidden layer, not recurrent, and it is prototyped on Intel/Altera FPGA. Our neural network processes the data based on the morphological image processing operators of Erosion and Dilation. Mathematical Morphology concerns the study of body shapes present in images by using the theory of intersection and union of sets implemented through mathematical calculations of minima and maxima. Thus, morphological operations naturally deal with the detection of the shapes of the bodies present in the images. By interpreting the decision boundary of a neural network as an n-dimensional image, where n refers to the number of extracted features, it can be stated that our coprocessor-based antivirus is able to naturally detect and model the n-dimensional regions mapped to the distinct classes (benign and malware).
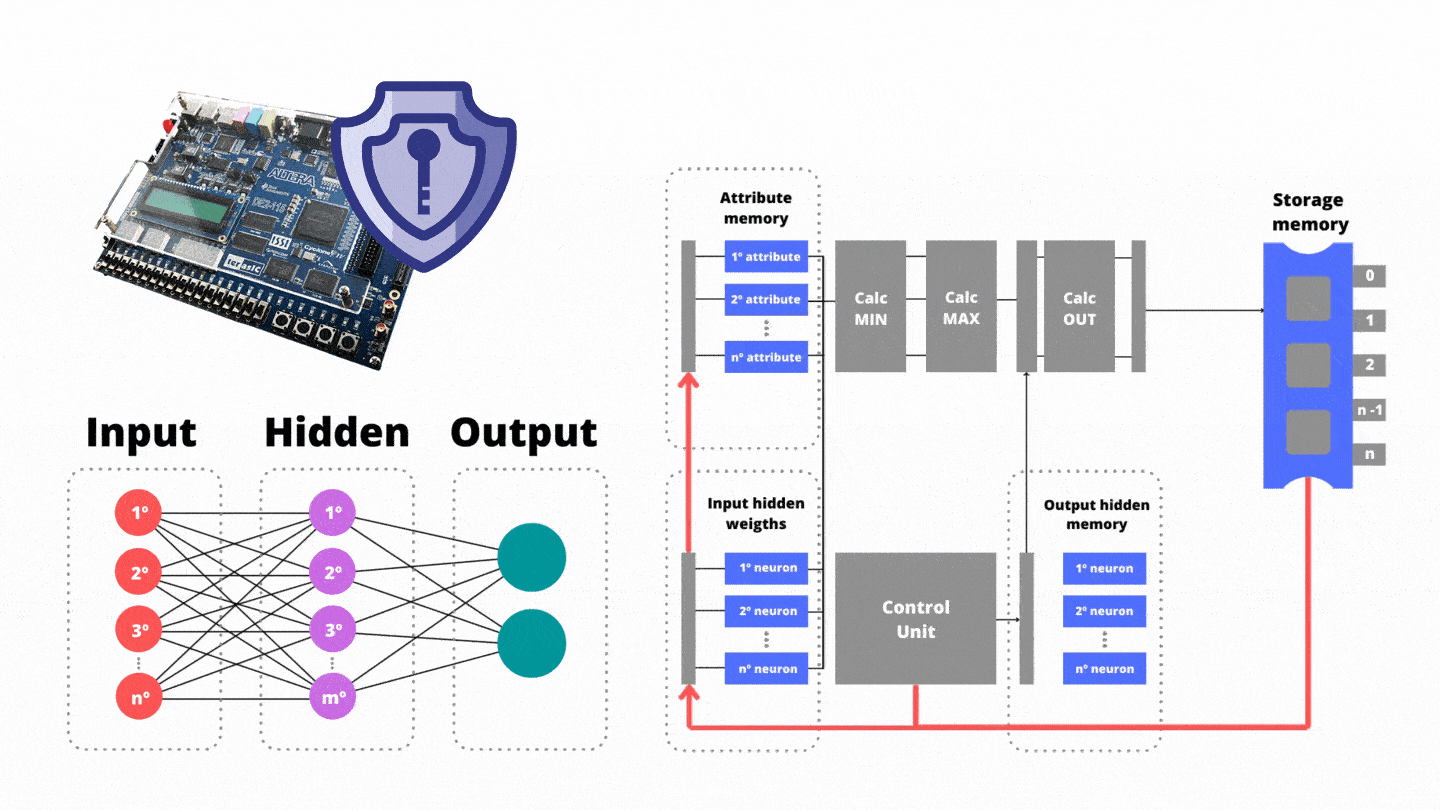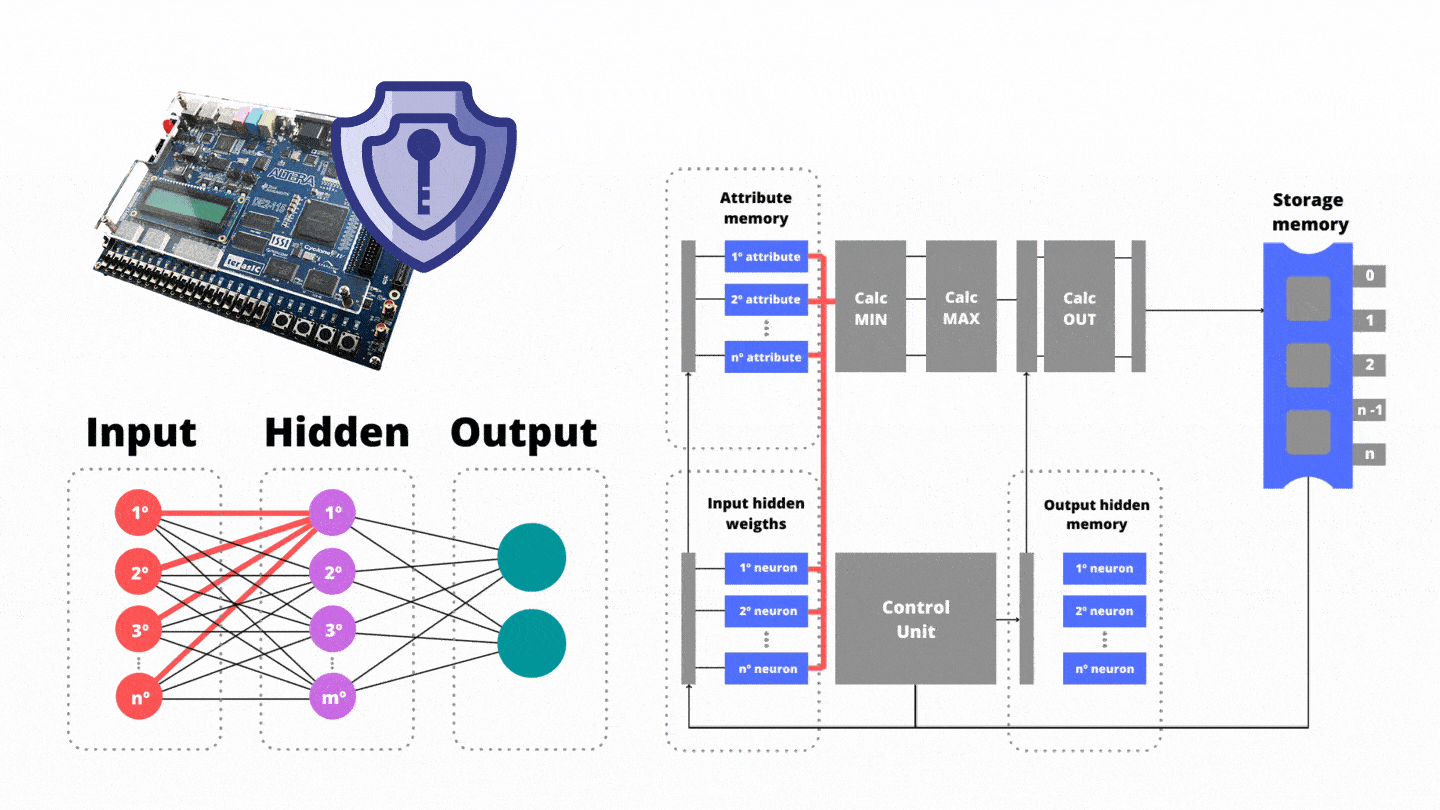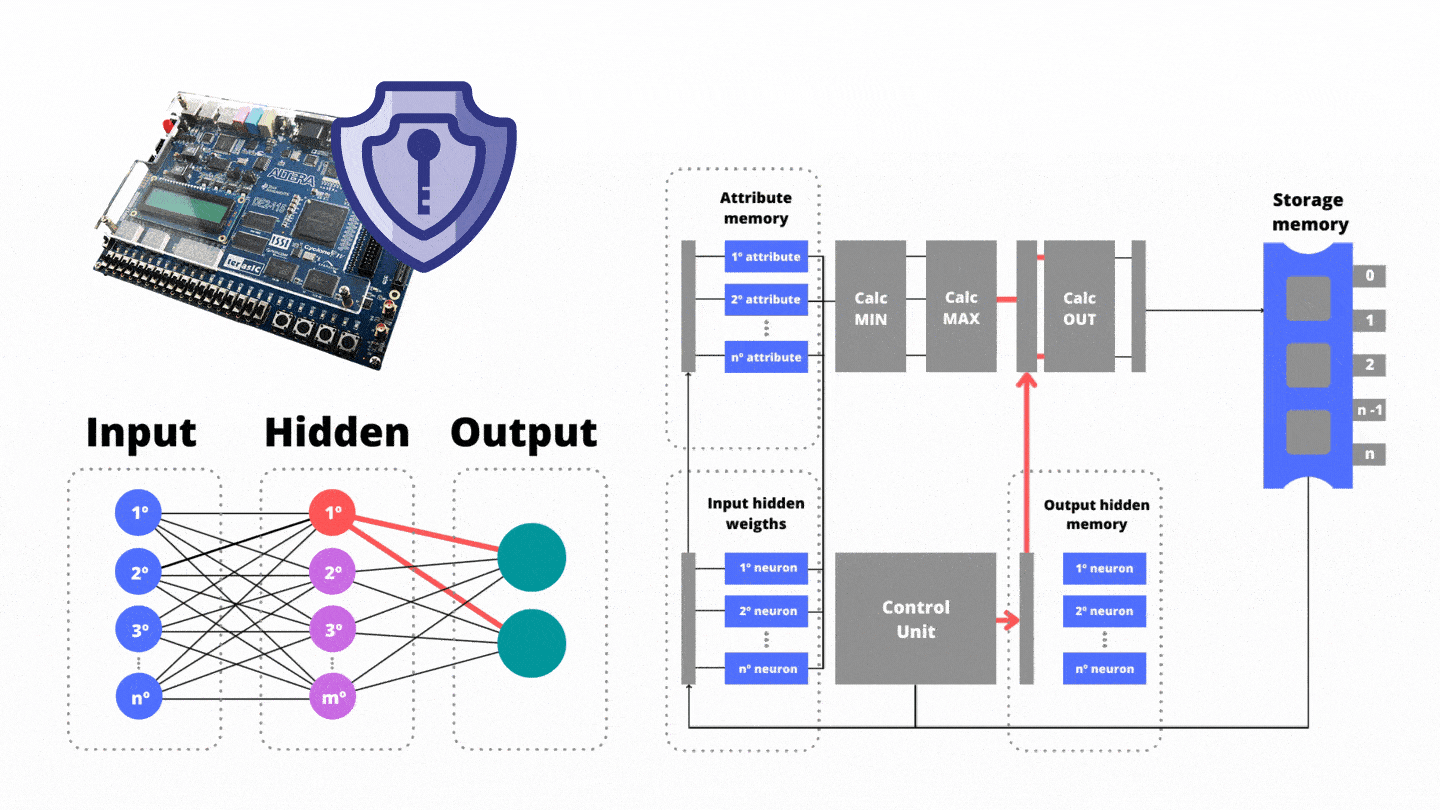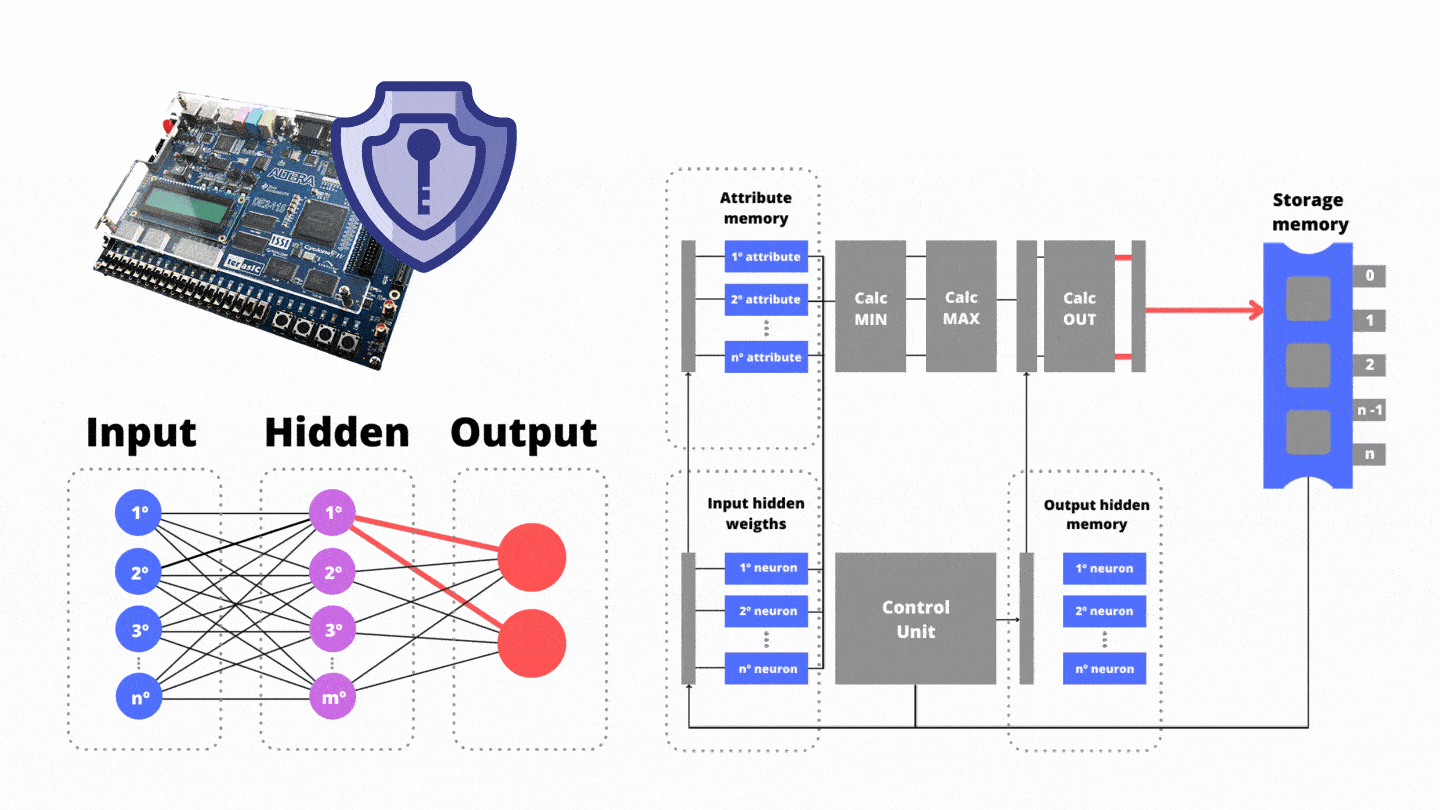
Our coprocessor-based antivirus achieves an average performance of 99.76% in the discrimination between benign and malware executables. Fig. 1 shows the block diagram of the coprocessor-based antivirus. There are three memory units; (i) the attribute memory, (ii) the bias and weight memory between the input and hidden layer, and finally (iii) the weight memory between the hidden and output layer. The attribute memory is responsible for storing the features extracted from the suspect application. The weights memory stores the synaptic connections coming from the network after its learning (training) period.
In total, our coprocessor-based antivirus extracts 630 attributes of each suspect applicative when disassembled. The functional groups extracted from the studied executable files are related to: histogram of instructions, number of subroutines that call TLS (Transport Layer Security), number of subroutines that export data (exports), APIs (Application Programming Interface), network traffic, features associated with Windows Registry and utility applications programs.
The Control Unit is the highest hierarchy program. Its function is to monitor the count of machine clock cycles in order to manage each step of the authorial pipeline, so that there is no producer/consumer paradigm. The reading would not occur by the consumer while the data is still being processed by the producer. Otherwise, the consumer could access data that is outdated and therefore incorrect.
In the first step of the authorial pipeline, they are reading (i) the attribute memory and (ii) the memory responsible for storing the bias vector and the weights between the input and hidden layer. In the second stage of the pipeline, the input neurons are decomposed into processing threads in order to have parallelism. The min functional unit is responsible for calculating minima between the attributes extracted from the suspect application and the weights that connect the input layer to the hidden one. The min functional unit invokes n processing threads in parallel where n refers to the amount of neurons in the input layer.
After that, our coprocessor employs the maximum theory over minimums. Then, the third stage of the pipeline triggers the max functional unit which is responsible for calculating the set theory of maxima. In the max unit , there are the maxima operations employing all n input minimums. As a product, there is the output of a single variable, added to the bias promoting the reduction of data dimensionality. The resultant of the unit is the processing of the first neuron of the hidden layer.
While the functional unit is running, in parallel the Control Unit manages the reading of (iii) the weights between the hidden layer and the output layer stored in the network memory. Thanks to the synchronism provided by the Control Unit, there are no bubbles in the pipeline progress. Also in the third stage, the Control Unit reads from the storage memory the weights between the input layer and the next neuron of the hidden layer. In the fourth pipeline step the resulting variable from the functional unit is weighted (multiplied) by the weights between the hidden layer and the output layer. As a result, on the fifth pipeline step, the temporary results for the output neurons are saved: benign or malware trend.
The authorial pipeline allows a work batch to use one functional unit of the hardware while others use another functional unit(s). Our pipeline aims to improve performance by increasing the throughput of the batches, i.e. by increasing the number of batches executed in the time unit, and not by decreasing the execution time of an individual functional unit. For example, while the unit performs the maxima computation referring to the first neuron of the hidden layer, the unit performs the minima computation connected to the second neuron of the hidden layer. We conclude that our coprocessor is a cost-effective solution, conducive to miniaturization and with a low number of Control Unit encodings.
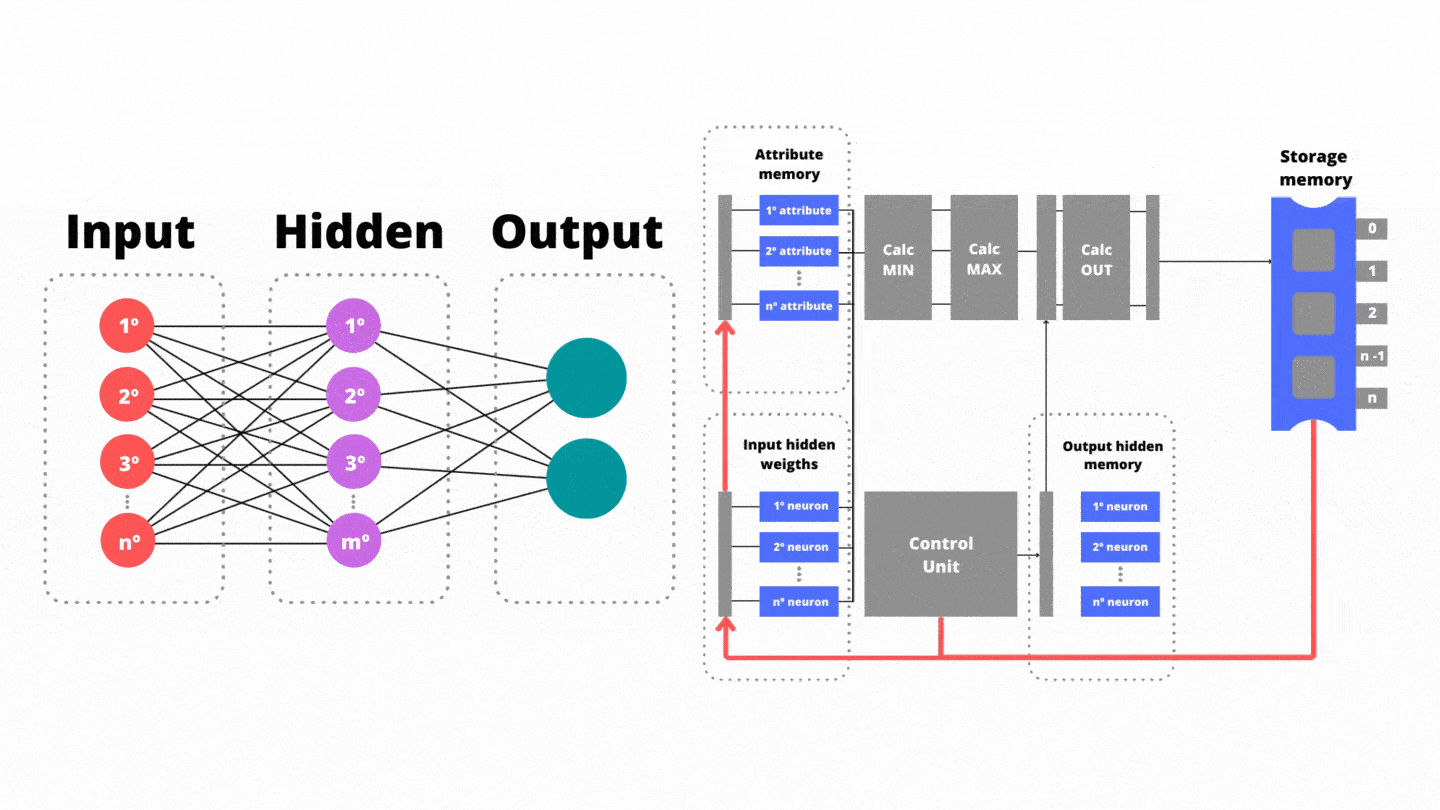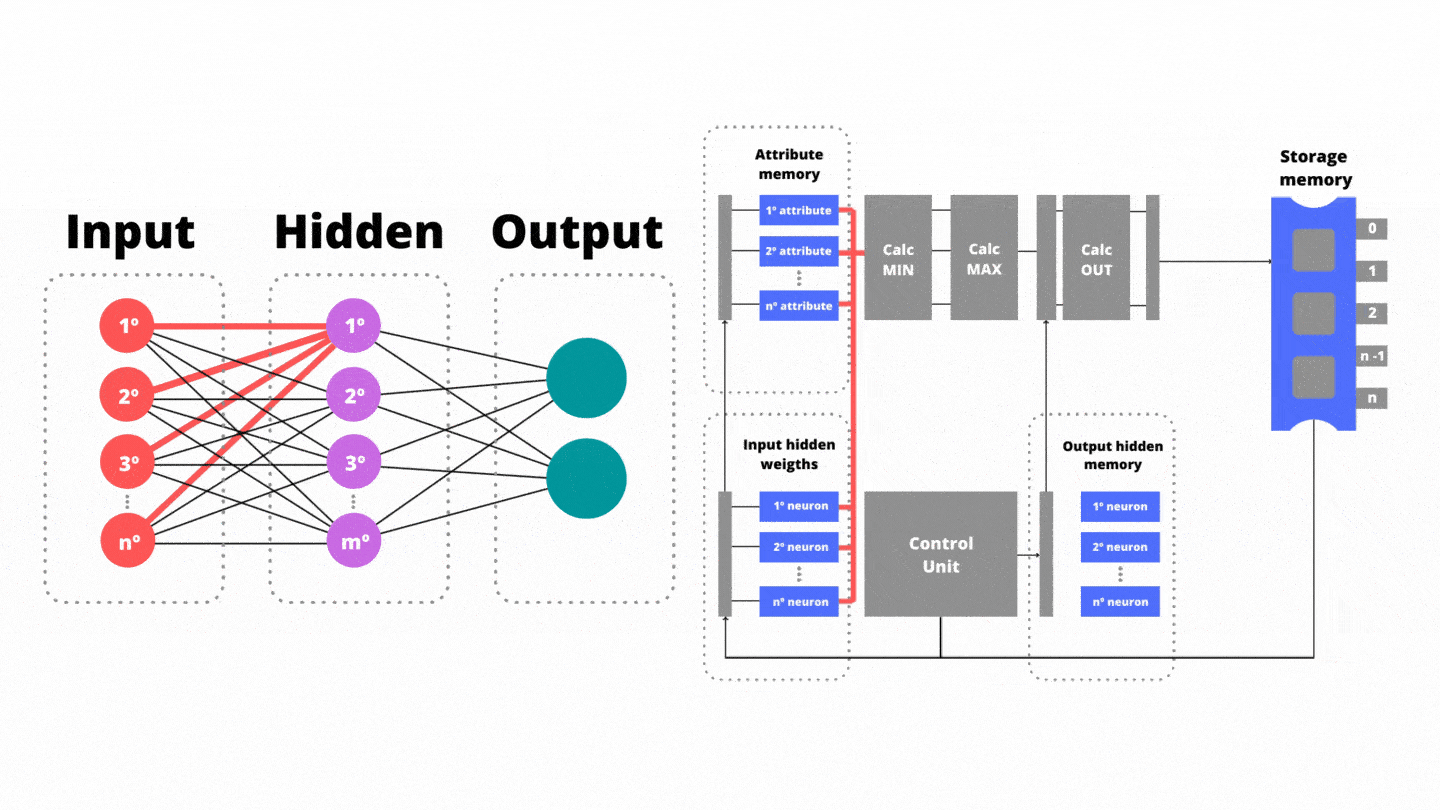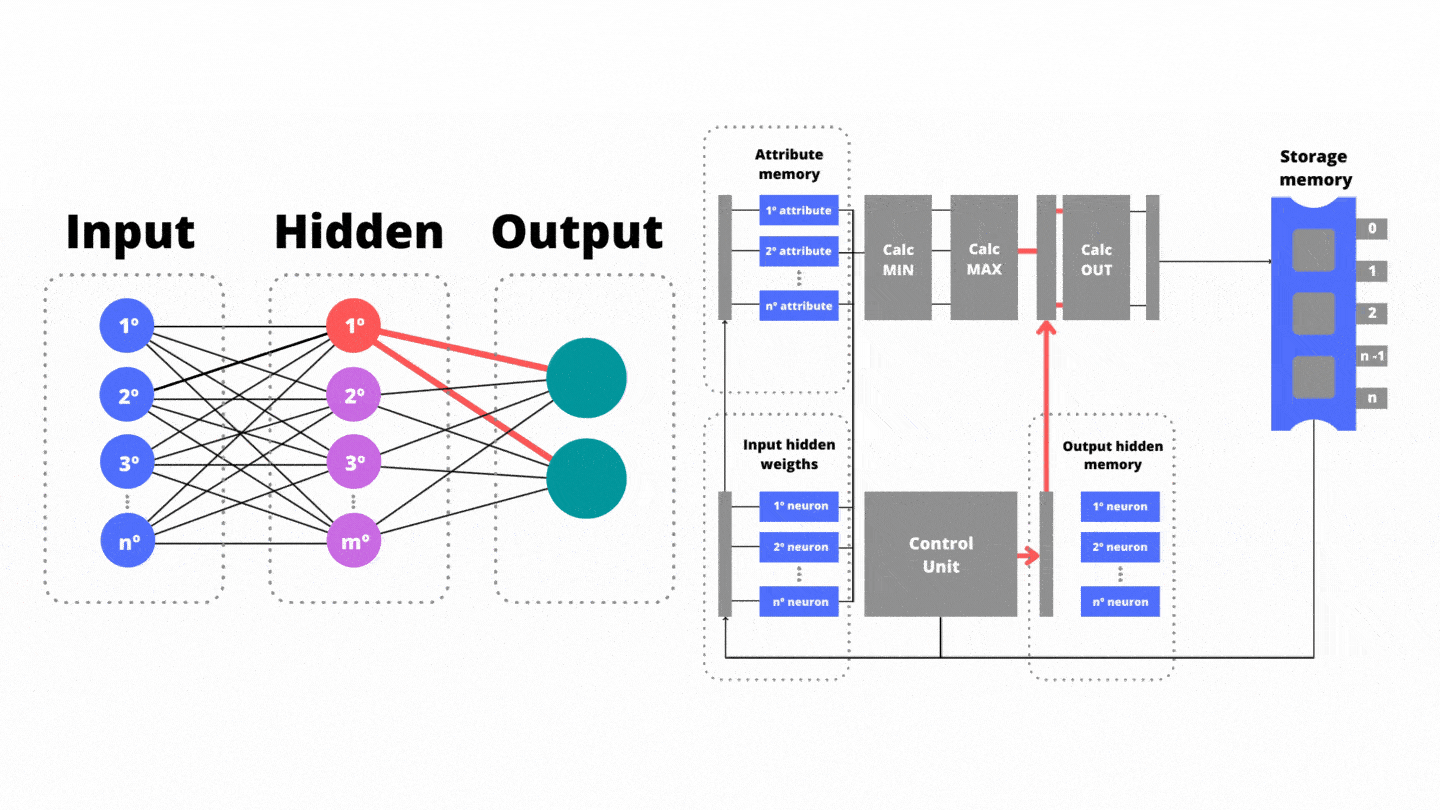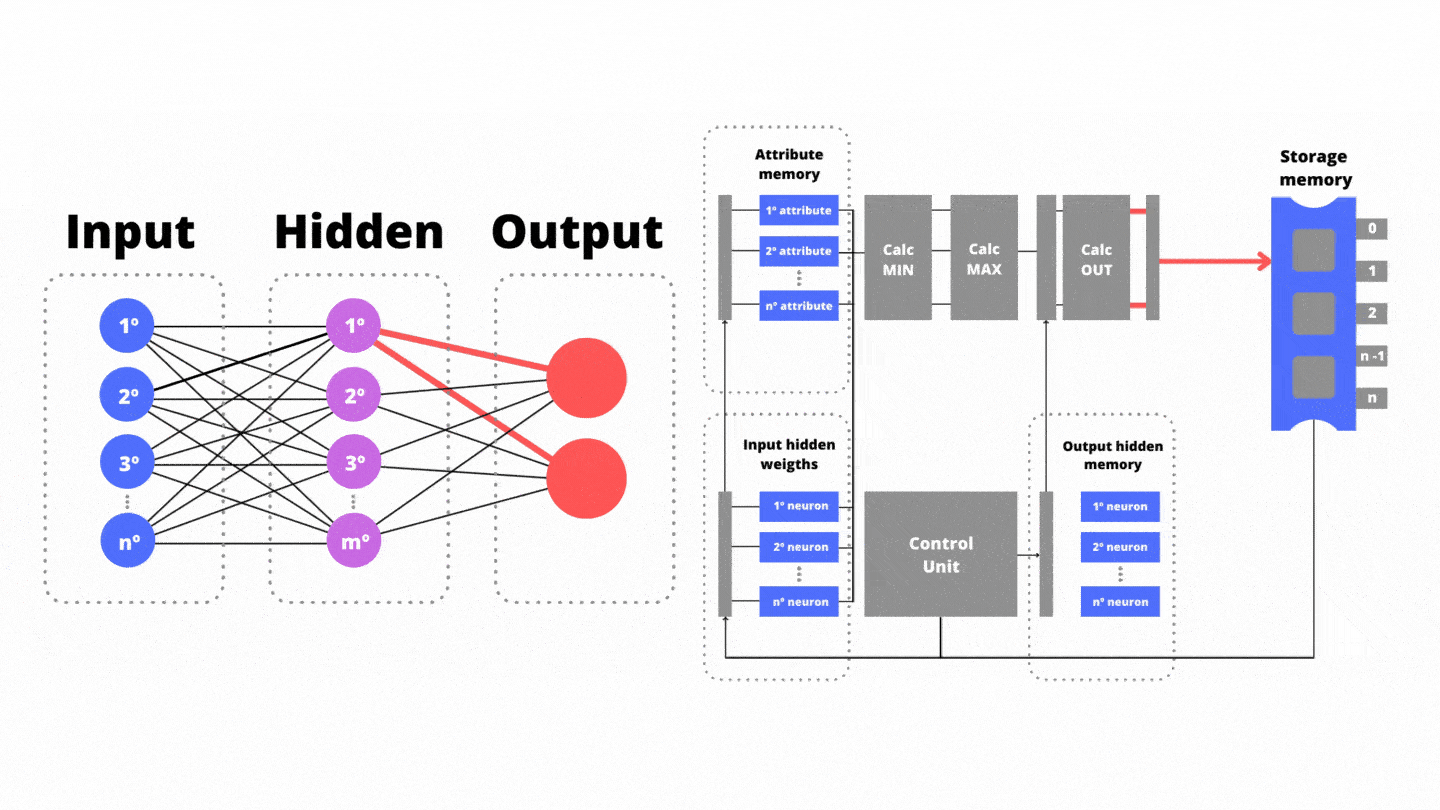 Fig. 1 Block diagram of the coprocessor-based antivirus.
Fig. 1 Block diagram of the coprocessor-based antivirus.
3. Expected sustainability results, projected resource savings
Commercial Antiviruses Limitation
Despite being criticized for more than a decade, the antiviruses modus operandi is still based on signatures when searching for suspicious samples in a database named blacklist [1]. As a result, signature-based antiviruses have null effectiveness when subjected to variants of the same malware or unprecedented malicious applications [1]. Currently, organizations seek to identify patterns of malware actions through advanced data science, machine learning, and neural networks [1].
Given the limitations of commercial antiviruses, it is not a difficult task to develop and distribute variants of malicious applications. To do this, it is enough to make small alterations in the original malware with routines that, effectively, do not have any usefulness, such as repetition loops and conditional branches without instructions in their scopes. These alterations without usefulness, however, turn the hash of the modified malware from the hash of the original malware. Consequently, malware augmented with null routines is not recognized by the antivirus that recognizes the initial malware. It should be emphasized that the existence of exploits responsible for creating and distributing, in automated form, variants of the same original malware. It is concluded that antiviruses, based on signatures, have null effectiveness when submitted to variants of the same software [1][2].
Through the VirusTotal platform, this proposed work explores 86 commercial antiviruses with their respective results presented in Table 1. We utilized 3,146 malware obtained from the REWEMA dataset [3]. The objective of the work is to verify the number of malicious samples cataloged by antiviruses. The motivation is that the acquisition of new malware is primordial to combat malicious activities.
The larger the dataset, named the blacklist, the better it tends to be the defense given by the antivirus. First, the malware is sent to the server belonging to the VirusTotal platform. At this point, the malicious files were analyzed by VirusTotal’s 86 commercial antiviruses. Then, the antiviruses give their diagnostics for the samples submitted to the server. VirusTotal allows three different types of diagnostics to be issued: benign, malware, and omission.
For the first VirusTotal possibility, the antivirus detects the maliciousness of the suspicious file. Within the proposed experimental environment, all submitted samples are malware documented by incident responders. The antivirus hits when it recognizes the malignancy of the investigated file. Malware detection shows that the antivirus offers robust support against digital invasions. In the second possibility, the antivirus certifies the benignity of the defined file. Then, in the proposed study, when the antivirus claims the file is benign, it is a false negative, as all the samples sent are malicious. In other words, the investigated file is malware; however, the antivirus mistakenly attests to it being benign. Within the third possibility, the antivirus does not give an analysis of the suspect application. The omission shows that the investigated file was never evaluated by the antivirus, so cannot be evaluated in real time. The omission of diagnosis by antivirus points to its limitation on large-scale services.
Table 1 shows the results of the 86 antivirus products evaluated. The McAfee-GW-Edition antivirus achieved the best performance by detecting 99.11% of the investigated malware. One of the largest adversities in combining malicious applications is the fact that antivirus manufacturers do not share their malware blacklists due to commercial disputes. Through the analysis in Table 1, the proposed work points to an aggravating factor of this advantage: the same antivirus manufacturer does not share their databases among their different antiviruses. Observe, for example, that McAfee-GW-Edition and McAfee antiviruses belong to the same company. Their blacklists, although robust, are not shared between themselves. Therefore, the commercial strategies of the same company disturb the confrontation against malware, which demonstrates that antiviral manufacturers are not necessarily concerned with avoiding cyber invasions but with optimizing their business incomes.
Malware identification ranged from 0% to 99.11%, depending on the antivirus. Overall, the 86 antiviruses identified 54.84% of the examined malware, with a standard deviation of 39.67%. The elevated standard deviation shows that recognizing malicious files can change abruptly depending on the chosen antivirus. The protection against digital intrusions is in the function of choosing a vigorous antivirus with an expansive and upgraded blacklist. Overall, antiviruses certified false negatives in 14.34% of the cases, with a standard deviation of 21.67%. Attention to the benignity of malware can be implicated in unrecoverable damages. A person or institution, for instance, may begin to trust a certain malicious application when, in fact, it is malware. Nevertheless, as an unfavorable aspect, approximately 17% of antiviruses did not express an opinion on any of the 3,136 malicious samples. On average, the antiviruses were omitted in 30.82% of the cases, with a standard deviation of 40.97%. The omission of the diagnosis focuses on the constraint of antivirus in recognizing malware in real time.
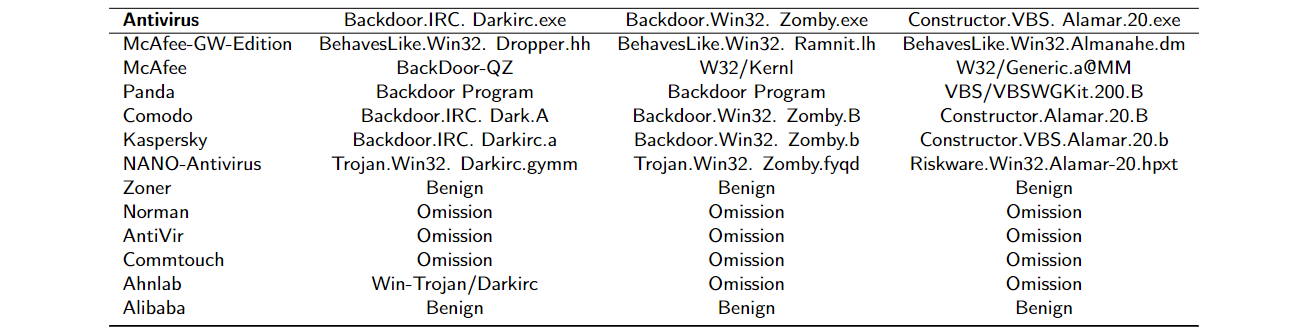
Due to difficulty in combating malicious applications, commercial antiviruses do not have a pattern in the classification of malware, as found in Table 2. We have chosen 3 of the 998 3,136 malware to exemplify the miscellaneous classifications given by commercial antiviral activities. As there is no pattern, the antiviruses use the names that they want; for example, a company can identify a malware as "Malware.1" and a second company can identify it as "Malware12310". Therefore, the lack of a pattern disturbs the cybersecurity strategies since each category of malware must have different treatments (vaccines). It is concluded that it is impracticable for supervised machine learning to adopt pattern recognition for malware categories. Due to this confusing tangle of multiclass classification provided by specialists (antiviruses), as seen in Table 2, it is statistically improbable that any machine learning technique will acquire generalization capability.
As a general rule, malware categories provided by commercial antiviruses are not defined in the portals of their respective manufacturers (as seen in video). After cyber-invasion, infected customers are conditioned to report the contagion in blogs, usually without any official response made by the manufacturer. With the exception of very few antiviruses, there is no description of the malware categories on manufacturer portals. Legally, antiviruses could not provide insufficient or inappropriate information regarding the risks of the service purchased. For example, it is not known the risks of quarantining an application classified as a malware with a confusing and unclear name, like the presented in Table 2. In addition, there is no technical description of these malware classes either in the academic literature or on the manufacturers' portal.
Table 1. Result of the submission of three malware to VirusTotal. Expanded results of 86 worldwide commercial antiviruses are in the authorial repository [3].
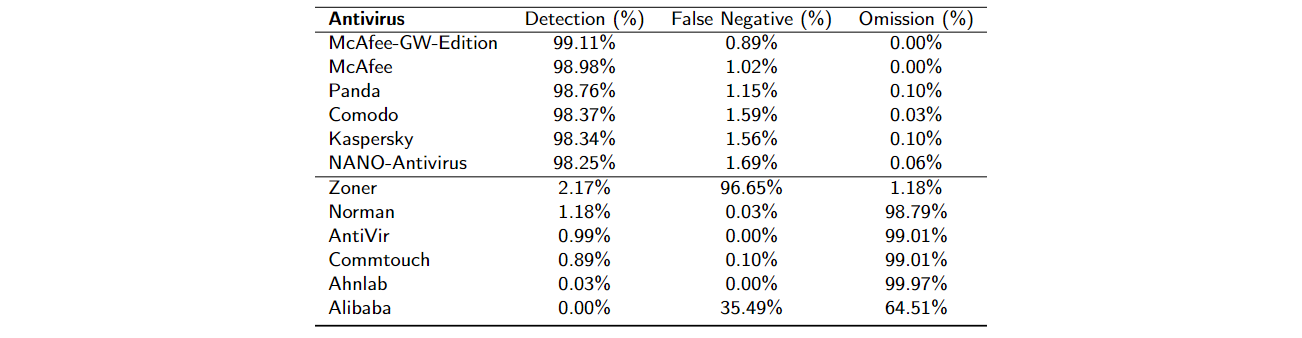
Table 2. Miscellaneous classifications of commercial antiviruses. Expanded results of 86 worldwide commercial antiviruses are in the authorial repository [3].
Artificial Intelligence-based Antivirus
The constraints of digital surveillance mechanisms can be overcome by artificial intelligence technology based on neural networks. Artificial intelligence is able to automate many jobs, analyzing thousands of data, extracting features and classifying them. Then, the artificial intelligence can recognize in real time the statistical patterns of the behaviors previously classified as suspects.
The state-of-the-art antivirus recommends extracting features of the suspect file, preventively, before executing it [2]. The executable file is submitted to the disassembly process. Then, the assembly code associated with the executable file can be analyzed, so the malicious intent of the suspicious application can be verified. The features from suspicious applications are used as input attributes of the artificial neural networks employed as the classifier. Neural network-based antivirus achieves an average performance of more than 90% in the discrimination between benign and malware executables [2].
Despite their extremely high accuracy, the latest neural networks engines, especially the deep nets, may take several days to complete the training phase even on a supercomputer. As an aggravating factor, deep networks have lower parallel capabilities because these layers are sequential. Therefore, this layer can only be executed after the upper layer has completed its work. In applications that require frequent training (learning) of antivirus software, this fact may be an obstacle because, on average, 8 (eight) new malware samples are created every second [4]. In syntheses, there should be no difference in the antivirus software learning time compared with the rate of new malware generation worldwide.
Due to the excellent results obtained by deep learning techniques, common sense has been created that deep learning can provide the best accuracy in any application type; in fact, this consideration is untrue. Deep neural networks, specifically convolutional networks, are based on linear filter convolution. Although it has a fundamental role in computer applications, filter convolution is limited to applications when a vector flow gradient is formed.
Consider, for example, biomedical images from mammography devices. The images are full of noise that hinders breast lesion recognition [5]. Therefore, convolution of filters is essential to eliminate noise and, therefore, discard small irregularities in the finding corresponding to potential cancer. Convolutional techniques, such as Gaussian filters, are essential to reducing noise in biomedical images [5].
As a counterexample, consider features completely disconnected from each other despite belonging to the same neighborhood. An application suspected of attempting to determine whether Wi-Fi data has no correlation with accessing the victim’s image gallery or browser. Then, when applying the linear convolution of filters in the repository, accessing the browser, containing the value 0, is treated as noise. The explanation is that its neighborhood has positive values. In synthesis, the suspect application is accused of accessing the victim’s browser, even the extraction of features having audited the inverse. Convolutional techniques suffer a disadvantage when applied to malware pattern recognition.
To prove our theoretical background, the authorial antivirus employs shallow morphological neural networks instead of deep convolutional networks. As expected, the authorial antivirus has accuracy compared to next-generation antiviruses based on both shallow and deep neural networks. Our antivirus can combine high precision with reduced learning time. To avoid unfair comparisons, the feature extraction stage is standardized by monitoring 630 behaviors that the suspicious file can perform when executed. Our antivirus enables high performance, large capacity of parallelism, and simple, low-power architecture with low power consumption. We concluded that our solution assists the main requirements for the proper operation and confection of an antivirus in hardware.
[1] LIMA, S., 2020. Limitation of COTS antiviruses: issues, controversies, and problems of COTS antiviruses. In: Cruz-Cunha, M.M., Mateus-Coelho, N.R. (eds.) Handbook of Research on CyberCrime and Information Privacy, vol. 1, 1st edn. IGI Global, Hershey. doi: http://dx.doi.org/10.4018/978-1-7998-5728-0.ch020.
[2] LIMA, S.M.L., SILVA, H.K.D.L., LUZ, J.H.d.S. et al. Artificial intelligence-based antivirus in order to detect malware preventively. Progress in Artificial Intelligence 10, 1–22 (2021). https://doi.org/10.1007/s13748-020-00220-4.
[3] REWEMA: Retrieval Applied to Malware Analysis. Available in: https://github.com/rewema/. Accessed on February 2022.
[4] INTEL. McAfee Labs: Threat Report. Available in: https://www.mcafee.com/ca/resources/reports/rp-quarterly-threats-mar-2018.pdf. Accessed in February 2018.
[5] LIMA, S., SILVA-FILHO, A.G., SANTOS, W.P., 2016. Detection and classification of masses in mammographic images in a multi-kernel approach. Computer Methods and Programs in Biomedicine 134, 11–29. doi:https://doi.org/10.1016/j.cmpb.2016.04.029
4. Design Introduction
Neural network is a computational intelligence model used to solve classification problems. Its main feature refers to generalization ability in front of the dataset not provided in the learning stage. In several neural networks, such as MLP (Multilayer Perceptron) [1], knowledge of network parameters is required in order to optimize performance when solving problems. In MLP, a common problem is to avoid maintaining local minimums, which is necessary to add net control strategies to induce freedom of these areas [2]. In this kind of neural network, another common feature is the high training time demanded to enable the neural network to perform classification correctly.
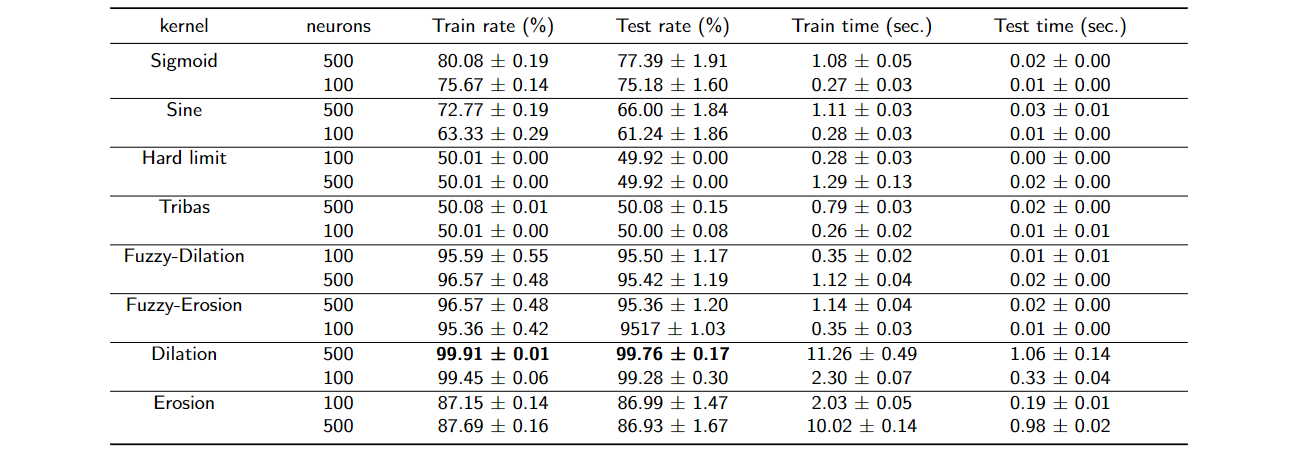
ELMs (Extreme Learning Machines) are learning machines based on flexible kernels [3]. Compared with other classifiers, the main feature of ELM (Extreme Learning Machine) neural network is the speed of training [2][3]. The learning of the ELM neural network is performed in batch mode. All data is presented to the network before adjusting the weights related to the synaptic connections between the neurons. It only needs one iteration, conventionally the training is faster than conventional methods. Then, since the algorithm is not recurrent, it is not necessary to decide the maximum amount of iterations. In addition, because it is not based on the gradient descent method, the ELM neural network will not suffer from the problem of local minimum, so there is no need to define control methods as learning rate parameter.
Mathematically, in ELM neural network the input attributes xti correspond to the set {xit ∈ R; t ∈ N*, t=1,..v; i ∈ N*, i=1,…,n}. Therefore, there are n features extracted from the application and v training data vectors. The hidden layer hj, consisting of m neurons, is represented by the set {hj ∈ R; j ∈ N*, j=1,…,m}. The ELM training process is very fast because it consists of only a few steps. Initially, the input weights wji and bias bias bjt are defined in a random generation.
Given the activation function f:R→R, the training process is divided into three steps:
-
Random generation of weight wji, corresponding to the weights between the input and the hidden layers, and bias bjt.
-
Calculate the matrix H, which is the output of the intermediary layer.
-
Calculate the matrix of the output weights β=H†Y, where H† is the generalized Moore-Penrose inverse matrix of matrix H, and Y corresponds to the matrix of expected outputs s.
The output of the hidden layer neurons, corresponding to the matrix H, is computed by the kernel φ, dataset inputs and weights between the input and the hidden layers as shown in Eq. (1).
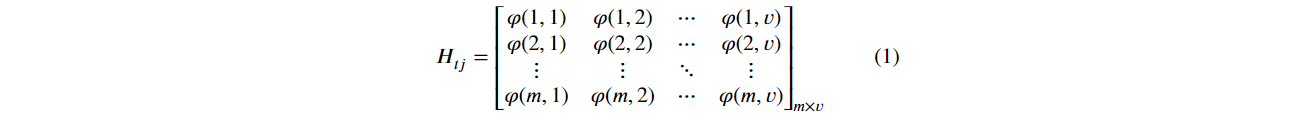
After training the ELM network, the test patterns are presented together with the desired output. The network will not make further alterations and will only calculate the results obtained for each new test set. By comparing the expected and obtained patterns, the accuracy of the ELM is calculated.Unlike backpropagation networks, in ELM networks, there is no need to define stopping criteria for training or to make strategies in order to ensure the neural network does not lose the generalization capacity. The reason is that the ELM provides only one iteration. Then, there is no need to separate data sets in training, validation, and testing. It is enough to divide the dataset into training and testing. Compared with neural networks based on backpropagation, these two sets can provide more samples.
The learning of ELMs networks is based on kernels. The kernels are mathematical functions used as learning method of ELMs neural networks. Kernel-based learning offers the possibility of creating a non-linear mapping of data without the need to increase the number of adjustable parameters such as the learning rate commonly used in neural networks based on backpropagation. Eq. (2) describes a Sine kernel φ of an ELM network with the results shown in the Figure 2 (a).
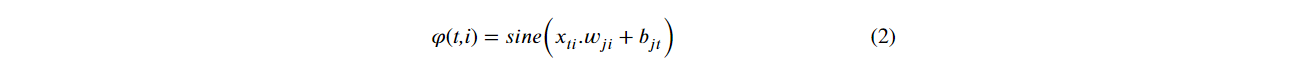
The authorial antivirus with ELM neural networks aims at pattern recognition of malware. Instead of conventional kernels, the work creates authoring kernels for ELMs. In the present work, mELMs (morphological ELMs) are proposed, ELM with hidden layer inspired by morphological operators of Erosion and Dilation image processing.
There are 2(two) crucial morphological operations: Erosion and Dilation [4]. Formally, Erosion and Dilation are described in Eq. (3) and Eq. (4), respectively [4]:
where f: S→[0,1] and g: S→[0,1] are normalized images in matrix form with the specification S, where S ∈ N2. The pixel is defined by the Cartesian pair (u, f(u)), where u is the position relative to the value f(u). v is the matrix of f(u), covered by g. The operators ∪ and ∨ are related with the maximum operation, while ∩ and ⋀ are related with the minimum operation. g is the structuring element for both Dilation and Erosion [4]. g is the negation of g.
Our mELMs are inspired by Mathematical Morphology based on the non-linear Erosion and Dilation operators. Take into account Eq. (3), alluding to Erosion image operator, then, our mELM Erosion kernel can be defined as shown in the Eq. (5), where {i ∈N*, i=1,…,n; j ∈ N*, j=1,…,m,; t ∈N*, t=1,..v}. Then, the input layer has n neurons (without bias), the hidden layer has m neurons, and v training data vectors.
Similarly to the mELM Erosion kernel, Eq, (6) defines the mELM Dilation kernel inspired by Eq. (4), associated with the morphological Dilation operator. By mathematical precedence, at first, it occurs the operations of minimum ⋀ denoted by xit ∨ wji. Then, the results of the minimum operations are added to bias bjt. Finally, H1t = Kε(ti) obtains the maximum value among the minimums, through the operator $∪$. The matrix H is specified in Eq. (1). By analogy between the image processing operation and our mELM kernel, the active region of the image f(v) is associated with the input attributes x1t, x2t, …, xnt. The structuring element negated g is associated with the weights wji of the synaptic connections between the input and hidden layers.
One of the most challenges in artificial neural networks is to determine a kernel in order to optimize the boundary decision between the classes of an application. In ELM neural networks, a Linear kernel, for illustration, is able to solve a linearly separable problem, as shown in Figure 2 (a). According to the same thinking, Sigmoid, Radbas (Radial Basis Function) and Sine kernels are able to solve problems separable by Sigmoid, Radial Basis and Sine functions, seen in Figure 2 (b), Figure 2 (c) and Figure 2 (d), respectively. The accuracies of the classifications are 96.43%, 100%, 100% and 100% of the kernels shown in Figure 2 (a), Figure 2 (b), Figure 2 (c) and Figure 2 (d), respectively.
Then, a major generalization ability of the neural network may depend on an adjusted kernel selection. The best kernel may obey the problem to be solved. The side effect is that the study of different kernels is usually time-consuming, involving cross-validation and different random initial conditions. However, different kernels may need to be studied, otherwise a neural network composed of untuned kernels may produce unsatisfactory results. As a counterexample, consider a Linear kernel applied to Sigmoid and Sine distributions shown in Figure 3 (a) and Figure 3 (b), respectively. The accuracies of the classifications shown in Figure 3 (a) and Figure 3 (b) are 78.71% and 73.00%, respectively. Visually, it can be observed that the Linear kernel does not correctly map the boundary decision of the Sigmoid and Sine distributions.
Figure 4 (a), Figure 4 (b), Figure 4 (c) and Figure 4 (d) show the performance of our mELM Erosion kernel in Linear, Sigmoid, Radial Basis and Sine distributions with accuracies of 100%, 93.07%, 98.18% and 99.50%, respectively. Figure 5 (a), Figure 5 (b), Figure 5 (c) and Figure 5 (d) show the performance of our mELM Dilation kernel in Linear, Sigmoid, Radial and Sine distributions with accuracies of of 100%, 95.05%, 98.18% and 99.50%, respectively. Visually, it can be observed that our mELMs can map different distributions in a satisfactory manner, involving different applications. It should be noted that feature 1, feature 2 and weights are normalized within the same upper and lower limits.
The successful of our mELM kernel involves their ability to model any boundary decision, because their mapping does not obey conventional geometric regions such as ellipses or hyperbolas. The boundary decision mapping performed by our mELM kernel uses coordinates in the n-dimensional space of the samples reserved for training, where n is the number of extracted features. Our mELM can use mathematical morphology to normally identify and model n-dimensional regions related to different classes, which can naturally detect the body shape present in the image [4].
Our authorial antivirus employs input data containing attributes that are completely disconnected from each other. Our morphological kernels have an important relationship with the aforementioned repository. The justification is that Mathematical Morphology is able to detect and segment the boundaries of target objects preserving the relationships of bodies through the use of the mathematical theory of intersection, union, and difference of sets [4]. Our morphological kernels are able to process fully segregated regions preserving their boundaries. By regions, we denote an area containing continuously congruent values.
On the other side, linear convolution of filters, conventionally employed by deep networks, generate weighted averages of the regions of interest discarding (blurring) small irregularities. As a consequence, a suspicious application could be accused of committing an illegal activity even when feature extraction had audited the reverse as explained in section 3. For this, it is enough that the monitored feature belongs to a neighborhood region containing positive values.
Fig 2. Successful performances of kernels compatible with datasets.
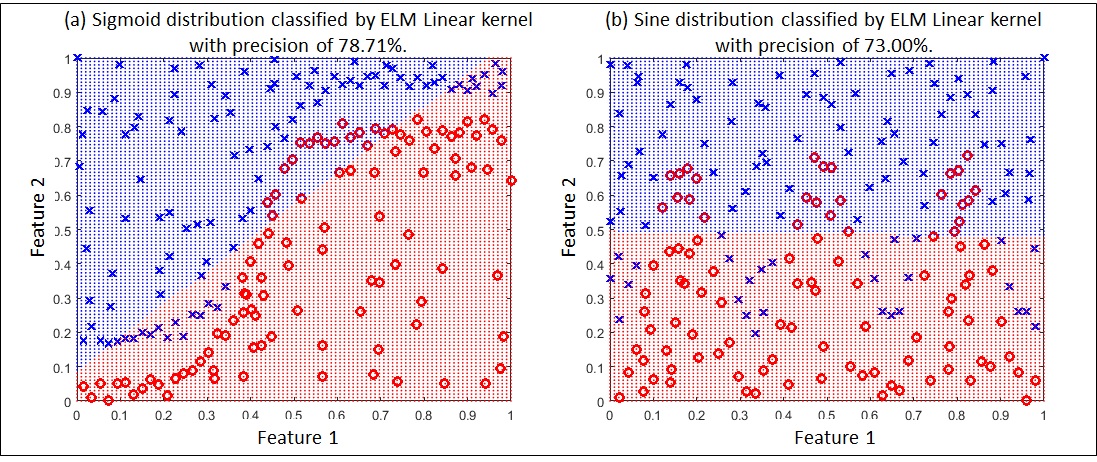
Fig 3. The performance of linear kernels in nonlinear separable data sets is poor.
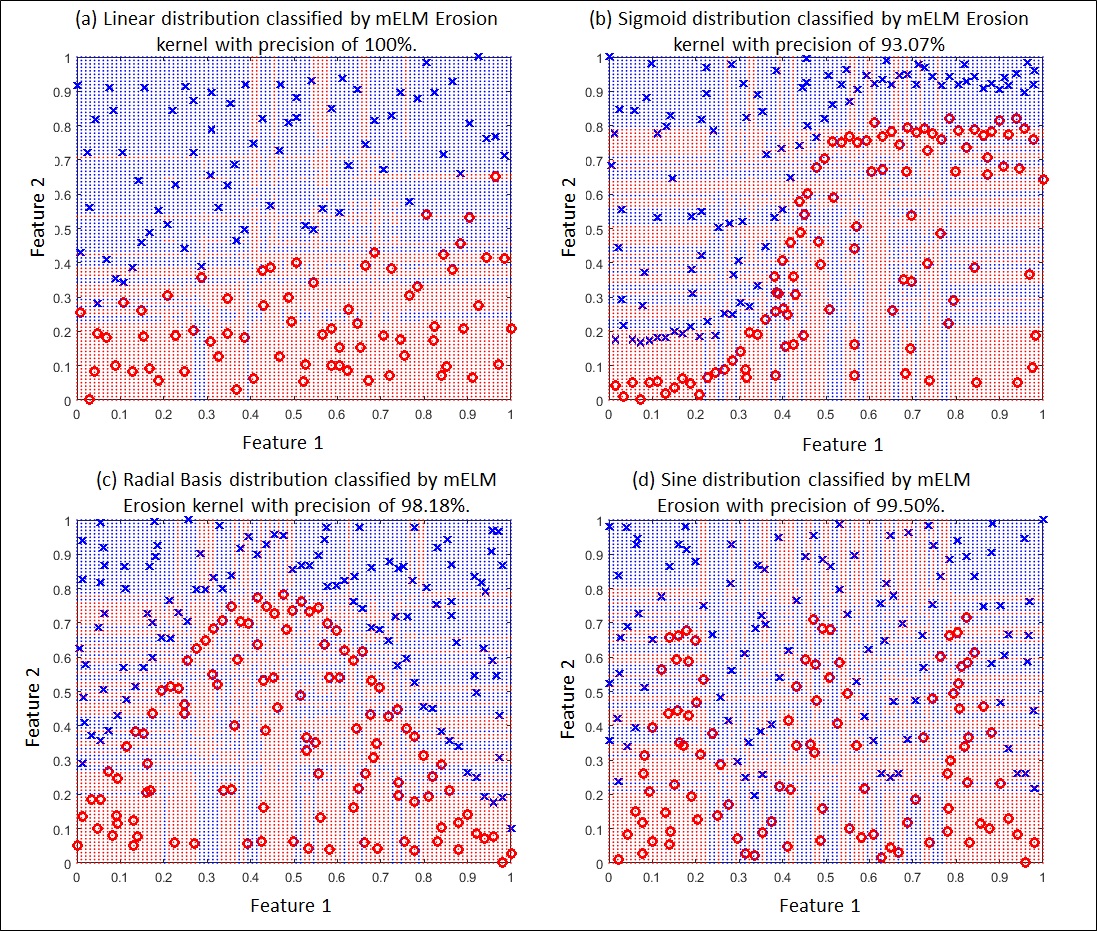
Fig 4. Successful performances of the mELM Erosion kernel in multiple datasets.
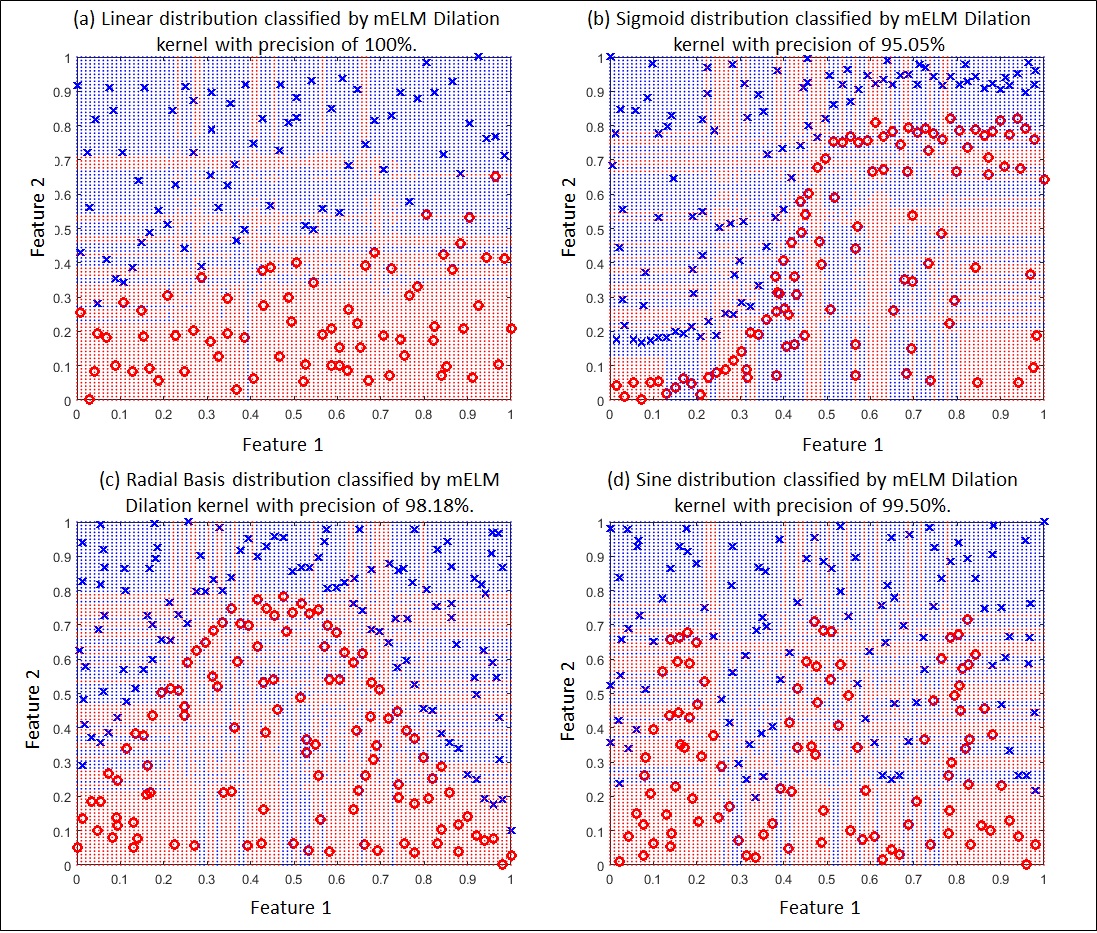
Fig 5. Successful performances of the mELM Dilation kernel in multiple datasets.
[1] XIANG, C.; DING, S. Q.; LEE, T. H. Geometrical interpretation and architecture selection of MLP. The IEEE Transactions on Neural Networks and Learning Systems. 2005 Jan;16(1):84-96., 2005.
[2] HUANG, G. B. et al. Extreme Learning Machine for Regression and MultiClass Classification. IEEE Transactions on Systems, Man, and Cybernetics. 42(2), (2012) 513-519., 2012.
[3] AZEVEDO, WASHINGTON W. ; SANTANA, M. A. ; DA SILVA-FILHO, ABEL G. ; LIMA, S. M. L. ; SANTOS, W. P. . Morphological Extreme Learning Machines applied to the detection and classification of mammary lesions.. In: Tapan K Gandhi; Siddhartha Bhattacharyya; Sourav De; Debanjan Konar; Sandip Dey.. (Org.). Advanced Machine Vision Paradigms for Medical Image Analysis.. 1ed.Londres: Elsevier Science, 2020, v. , p. 1-300.
[4] SANTOS, W. P. Mathematical Morphology In Digital Document Analysis and Processing, New York: Nova Science. Chapter 8, (2011) 159-192., 2011.
5. Functional description and implementation
Information Security is a great challenge due to the volume of malicious applications. Every commercial antivirus has its respective blacklist containing millions of samples. The modus operandi of querying for suspect applications in blacklists can be prohibitive as it could cost days, perhaps months. It should be noted that the comparison between suspect application and the antivirus blacklist may become impractical because millions of malware are created annually. Thus, artificial intelligence is capable of overcoming the limitations of commercial antiviruses both in terms of accuracy and response time. Unlike blacklist, malware detection is done by auditing suspicious behavior previously cataloged during the learning process (training).
Our extreme neural network has a single hidden layer, not recurrent, and it is prototyped on Intel/Altera FPGA. Our coprocessor-based antivirus achieves an average performance of 99.76% in the discrimination between benign and malware executables. There are three memory units; (i) the attribute memory, (ii) the bias and weight memory between the input and hidden layer, and finally (iii) the weight memory between the hidden and output layer. The attribute memory is responsible for storing the features extracted from the suspect application. The weights memory stores the synaptic connections coming from the network after its learning (training) period.
The Control Unit is the highest hierarchy program. Its function is to monitor the count of machine clock cycles in order to manage each step of the authorial pipeline, then, there is no producer/consumer paradigm. The reading would not occur by the consumer while the data is still being processed by the producer. Otherwise, the consumer could access data that is outdated and therefore incorrect.
In the first step of the authorial pipeline, they are reading (i) the attribute memory and (ii) the memory responsible for storing the bias vector and the weights between the input and hidden layer. In the second stage of the pipeline, the input neurons are decomposed into processing threads in order to have parallelism. The min functional unit is responsible for calculating minima between the attributes extracted from the suspect application and the weights that connect the input layer to the hidden one. The functional unit invokes n processing threads in parallel where n refers to the amount of neurons in the input layer.
After that, our coprocessor employs the maximum theory over minimums. Then, the third stage of the pipeline triggers the max functional unit which is responsible for calculating the set theory of maxima. In the unit , there are the maxima operations employing all n input minimums. As a product, there is the output of a single variable, added to the bias promoting the reduction of data dimensionality. The resultant of the unit is the processing of the first neuron of the hidden layer.
While the functional unit is running, in parallel the Control Unit manages the reading of (iii) the weights between the hidden layer and the output layer stored in the network memory. Thanks to the synchronism provided by the Control Unit, there are no bubbles in the pipeline progress. In the fourth pipeline step the resulting variable from the functional unit is weighted (multiplied) by the weights between the hidden layer and the output layer. As a result, the temporary results for the output neurons are saved: benign and malware.
The authorial pipeline allows a work batch to use one functional unit of the hardware while others use another functional unit(s). The authoring pipeline aims to improve performance by increasing the throughput of the batches, i.e. by increasing the number of batches executed in the time unit, and not by decreasing the execution time of an individual functional unit. For example, while the unit performs the maxima computation referring to the first neuron of the hidden layer, the unit performs the minima computation connected to the second neuron of the hidden layer. We conclude that our coprocessor is a cost-effective solution, conducive to miniaturization and with a low number of Control Unit encodings.
6. Performance metrics, performance to expectation
Our objective is to create a computationally high-performance antivirus with large parallelism capacity even when running on slow devices (hardware with low processing and storage capacity). Our coprocessor-based antivirus adopts parallelism in order to increase the performance of the architecture through data multiprocessing. The motivation for creating an antivirus at the hardware architecture-level abstraction layer is related to decreasing the response time of the solution. In addition, our coprocessor-based antivirus is able to unburden the CPU since cyber-surveillance mechanisms often demand a lot of processing.
In relation to high-performance, the limitations presented by the CPU can be supplied by coprocessors. In synthesis, the processing provided by the CPU considerably degrades the response time of a given application. The explanation is that the ULA (Logical and Arithmetic Unit), related to CPU, processes only one operation at a time. On the other hand, coprocessors process the necessary operations in a single unit of time due to use of parallelism techniques. Coprocessors are capable of accelerating the performance of many computing applications. Coprocessors have been widely applied in the most diverse areas. Coprocessors can greatly contribute to the advancement of information security in devices.
Our authoring coprocessor is compared to application-level antivirus replica. Rather than employing a general-purpose computer, software-level antivirus replication occurs on the same embedded platform employed by the authorial coprocessor. The intention is to show the advantages of creating a hardware architecture-level abstraction layer for an antivirus. By architecture, we denote input and output devices, control units and functional processing and storage units.
In order to avoid compatibility issues, the replication of the software-level antivirus replication occurs on the same platform where the coprocessor was prototyped. The application-level antivirus replica runs on the NIOS II processor, to the detriment of other CPUs such as MIPS, POWERPC, and 8056. The motivation is that NIOS II is an intellectual property belonging to the same manufacturer as the hardware platform (Altera FPGA) where the prototyping of the authorial coprocessor was performed.
In addition, the NIOS II CPU has presented characteristics favorable to miniaturization which constitutes one of the main requirements for making hardware platforms. Thomas Wicent [1] proposed two architectures; the first one with NIOS II processor and cache memory hierarchy, the second contained a MIPS processor kernel adapted and named Plasma CPU [2]. Thomas Wicent also assessed the impact of logical cells and memory bits on an APEX FPGA. The MIPS CPU required 2861 logical cells, while the NIOS II CPU required only 1500. In addition, the MIPS memory model uses 70% more memory bits when compared to the NIOS memory model. In view, the NIOS II CPU was chosen, at the expense of the other CPUs, aiming to explain the advantages of creating a hardware architecture-level abstraction layer for an antivirus.
Application-level antivirus replica runs on a single-processor platform containing a NIOS II processor with a frequency of 50MHz, supply voltage of 1.2 volts, a level of cache memory hierarchy, containing instruction cache and data cache. The architecture has a 128KB RAM of main memory. In addition, they are used: JTAG UART (an input and output peripheral), the Performance Counter: a number of cycles counter, the System ID Peripheral (a peripheral which avoids the exchange between devices) and finally the Interval Timer (a time counter). Both the instruction cache and the data cache have a size of 64 Kbytes. The instruction cache and data cache line sizes are 32 bytes and 4 bytes respectively, for all configurations. Associativity is fixed at 1 for both the data cache and the instruction cache.
The synthesis performed by Quartus II used balanced speed and area optimization techniques both in the creation of the authorial coprocessor and in the NIOS II CPU. Both methodologies were made in VHDL language at RTL (Register Transfer Level) level. Parameters were used by default such as: room temperature (25°C), 23mm heat sink with 200 LFpM air circulation rate and toggle rate of 12.5%. The family and target device of all experiments were Cyclone IV and EP4CE115F29C7, respectively.
[1] Wincent. "The Design, Implementation and Evaluation of a MIPS IP-core for the Altera SOPC-Builder". Department of IMIT/LECS, pp. 1-22, 2005.
[2] The Plasma CPU. Available in: http://www.opencores.org/projects.cgi/web/mips/overview. Access on February 2022.
7. Sustainability results, resource savings achieved
Desktop Application-Level Accuracy
Limited mechanisms by conventional antiviruses can be suppressed by artificial intelligence techniques based on neural networks. Artificial intelligence is able to statistically recognize the pattern of behaviors previously classified as suspicious in real time. Our dataset is the union of malware databases such as Vxheaven and TheZoo. Regarding benign executables, the acquisition came from benign applications repositories such as sourceforge, github and sysinternals. It should be noted that all benign executable files have been submitted to VirusTotal and have been certified by the world’s major commercial antiviruses. The diagnostics corresponding to benign and malicious executables, provided by VirusTotal, are available at the virtual address of our dataset [1].
Expectedly, system applications are PE (Portable Executable) files. These files correspond to processes, services and libraries associated with .exe, .sys and .dll extensions, respectively. PE files are broadly used in basic system functions and utility applications. As an aggravating factor, PE malware can cause significant losses since they execute directly in the Operating System. Unlike the interpreter, the execution of the PE file does not rely on the virtual machine like the Java virtual machine. Then, PE malware can directly perform critical operations on the system. Our antivirus employs a dataset designed to 32-bit Windows files [1]. Our dataset contains 6,272 executables: 3,136 malware samples, and 3,136 other benign samples. Hence, our dataset is suitable for learning with neural networks because the number of samples of the two classes is the same.
Malware in the authorial dataset are broadly used in various malicious activities. They can be Worm, Virus, HackTool, Trojan Horse, Backdoor, Constructor, Hoax, Exploit, Rootkit, and Spyware. In expansion, malware can be botnets aiming Flooder, DoS (Denial of Service), IRC (Internet Relay Chat), CF (Click Fraud), CC (Command and Control server), and SPAM email. A botnet is a group of machines infected with malware. These machines are called bots or zombies. They are remotely controlled by an individual named botmaster through the Command and Control (C&C) communication channel. Technically, the zombie has the operating system contaminated. Thereafter, after the C&C channel is established, the bot will receive updates and/or commands from botmaster in order to unconsciously participate in cyber-attacks. The ultimate goal of a botnet is to launch simultaneous attacks by recruiting its zombies.
The executable feature extraction employs the process of disassembling in order to reverse the binary file in its assembly code. Then, the executable can be studied and then classified by the neural networks. Next, the functional groups extracted from the studied executable files are introduced in detail. In total, there are extraction of 630 features of each executable. They are histogram instructions, which represent the mnemonic in assembly. Number of subroutines that call TLS (Transport Layer Security). Number of subroutines that export data (exports). APIs (Application Programming Interface) used by the executable files. Features associated with clues that the computer has suffered fragmentation on its hard disk, as well as accumulated invalid boot attempts.
In addition, features associated with the Operating System. Features associated with Windows Registry. It is worth noting that even if the malware is detected and eliminated, the victim may not be able to get rid of the malware infection. Due to the inclusion of malicious entries (keys) in Registry, the persistence of malicious activities will happen even after the malware is excluded. Then, when the operating system starts, the cyber-attack restarts because the malicious key invokes the vulnerability exploited by the malware (for example, redirects the Internet Explorer homepage). Features associated with spywares such as keyloggers (capture of keyboard information in order to theft of passwords and logins) and screenloggers (screenshots of the victims). Features related with Digital Antiforensic which are procedures of removal, occultation and subversion of evidences in order to reduce the results of forensic examination. Features associated with the creation of GUI (Graphical User Interface) of the suspicious program. Features associated with the illicit forensic of the RAM (main memory) of the local system. Features related to network traffic. Features associated with utility applications programs.
Through the description of the features of our antivirus software audit, a malware can use native legitimate services of the operating system, however, in a distorted manner in most cases.For example, malware uses the victim’s webcam without his/her consent. Our conclusion is that it is wrong to condemn an application because it makes use of a specific process (such as a webcam). In general, it is incorrect to condemn an application for a single feature, because benign applications can also use these features. Then, malware recognition should occur through the crossover of information and, so all audited behaviors should be weighted. Our antivirus employs data science, machine learning repository, and artificial neural networks.
We employ artificial neural networks as classifiers. The neural network architectures have an input layer containing a number of neurons relative to the feature extraction vector. Then, the classifiers must have an input layer containing 630 neurons. They are related to features coming from the executable. The output layer has two neurons, associated with benign and malware classes.
In application-level, our antivirus achieves the average maximum performance of 99.76% with a standard deviation of 0.17% through the mELM kernel Dilation with 500 neurons in its hidden layer as seen in Table 3. Therefore, our mELM Dilation kernel presents the excellent quality of not suffering abrupt changes due to the initial conditions. It would be emphasized that the authorial Dilation kernel obtained the best average accuracy regardless of its architecture. We claim that our morphological kernels are able to adapt to any decision boundary. Because they are inspired by Mathematical Morphology, our mELMs are able to model any mapping present in the decision frontiers of neural networks.
Table 3. Result of ELM Networks. The number of neurons in the hidden layer varies according to the set {100, 500}.
Coprocessor antivirus at hardware architecture-level abstraction layer
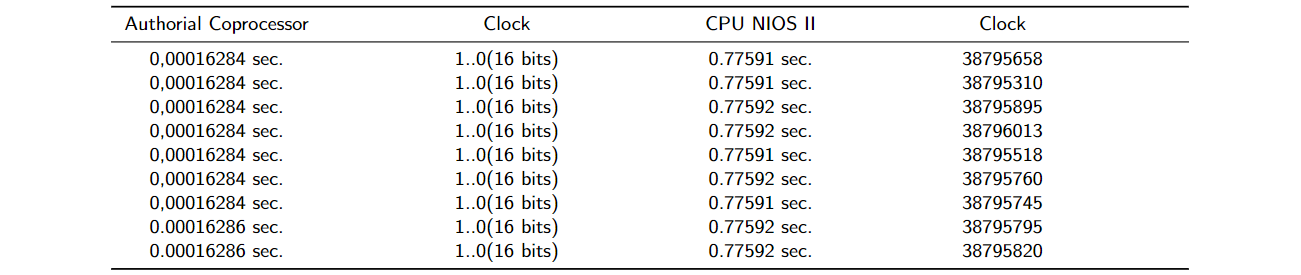
Social Engineering is able to manipulate the victim's feelings to the point of disabling/ignoring an application-level antivirus. Then, we construct a coprocessor-based antivirus prototyped on Intel/Altera FPGA. Preliminary results indicate that the authorial coprocessor, created in hardware architecture-level abstraction layer, can speed up the response time of the proposed antivirus by about 4,765 times as seen in Table 2. Thus, the malicious intent of the malware is detected, preventively, even when executed on a slow device (low processing power).
It is worth noting that, in addition to its high performance, the authorial Coprocessor can discharge the CPU. Then, the Central Unit can focus on the inherent tasks of the device's target applications. We performed 10 iterations of each case; authorial coprocessor and NIOS II CPU. In Table 4, there are the machine clock cycles and the time values in seconds. Indicated as coprocessor, the operations with the hardware described in VHDL for the fully organized architecture for the operations. For authorial coprocessor, several functional units operate at the same time. Therefore, a comparison to show how much faster to the detriment of a central unit environment.
Preliminary results indicate that our antivirus is faster than a blink of an eye due to the multiprocessing of data. It is emphasized that the human requires about 0.3 seconds in order to blink. In addition, there is no way for the user to disable/ bypass the work of our coprocessor-based antivirus, unlike application-level antivirus. Being developed in a hardware architecture-level abstraction layer, our coprocessor-based antivirus is insensitive to Social Engineering attacks and/or Operating System corruption.
Table 4: Runtime measurement for NIOS coprocessor and NIOS II CPU (our coprocessor 4,765 times faster on average).
In addition, the present work replicates the authorial antivirus in firmware targeting IoT (Internet of Things), specifically, prototyped in the ARM architecture. Malicious applications have been propagated on the Internet of Things due to its increasing popularity. Information Security is a major challenge in IoT as its computer systems are relatively recent. This fact makes it possible for thousands of malware to hide in a large number of legitimate applications, which seriously threatens the security of systems.
There are malware specialized in stealing automotive information, surveillance cameras and routers [2][3][4]. As a general rule, IoT malware is corrupted firmware. Once the IoT firmware has been corrupted, its disinfection may be infeasible. The explanation is that the internal pins and connectors related to the device update can be disabled by the corrupted firmware. The firmware-level antivirus replica runs on the ARM processor. The family and target device of all experiments were Cyclone V and 5CSEBA6U2317NDK, respectively. In firmware-level, our antivirus consumes 0.2 seconds with a standard deviation of 0.1 through the mELM kernel Dilation with 500 neurons in its hidden layer.
[1] REWEMA: Retrieval Applied to Malware Analysis. Available in: https://github.com/rewema/. Accessed on February 2022.
[2] LE, H.-V.; NGO, Q.-D.; LE, V.-H. Iot Botnet Detection Using System Call Graphs and One-Class CNN Classification International Journal of Innovative Technology and Exploring Engineering (IJITEE), 2019.
[3] BEZERRA, V. E. A. IoTDS: A One-Class Classification Approach to Detect Botnets in Internet of Things Devices. Sensors (Basel, Switzerland). doi: 10.3390/s19143188, 2019.
[4] SHARMEEN, S. E. A. Malware Threats and Detection for Industrial Mobile-Iot Networks. Special Section on Security and Trusted Computing for Industrial, IEEE, 2018.
8. Conclusion
The goal of the proposed work was to surpass the limitations of commercial antiviruses which, even with billionaire revenues, have low effectiveness and have been questioned by research institutes for more than a decade [1]. Commercial antivirus methods are based on signatures comparing suspicious executable files with the blacklists cataloged in previous reports (which require previous victims). In synthesis, blacklists are effectively null due to the current worldwide malware creation rate of 8 (eight) new malware every second [2]. Beyond retrograde methods, Social Engineering is able to manipulate the victim's feelings to the point of disabling/ignoring an application-level antivirus .
Our coprocessor-based antivirus is prototyped on Intel/Altera FPGA. Preliminary results indicate that our antivirus is faster than a blink of an eye due to the multiprocessing of data. Our antivirus is able to preventively identify a malicious application before it is even executed by the user. Our coprocessor-based antivirus achieves an average performance of 99.76% in the discrimination between benign and malware executables. In addition, there is no way for the user to disable/bypass the work of our coprocessor-based antivirus, unlike application-level ones. Being developed in a hardware architecture-level abstraction layer, our coprocessor-based antivirus is insensitive to Social Engineering attacks and/or Operating System corruption.
The explanation of the success of our learning machines concerns their capacity in order to model any borderline decision since their mapping does not comply with the ordinary geometric surfaces like ellipse and hyperbole employed by classic neural networks systems. Borderline decision mapping, performed by our morphological kernels, uses the values of samples reserved for training. Our morphological learning machine interprets the boundary decision of neural network as an n-dimensional image, where n is the number of extracted features, including different shapes that can be described by using Mathematical Morphology. Therefore, our morphological machine kernels naturally handle the delineation and modeling of regions mapped to different classes of any machine learning repository.
With the growth of social networks and more and more people connected via electronic devices, confidentiality of information plays an important legacy in maintaining the dignity, financial status and mental health of genuine users. Then, our coprocessor antivirus hopes to collaborate in guaranteeing the human rights of contemporary society. Our expectation is to show how technology can be at the service of fundamental rights
[1] SANS Institute InfoSec Reading Room. Out with The Old, In with The New: Replacing Traditional Antivirus. Available in: https://www.sans.org/reading-room/whitepapers/analyst/old-new-replacing-traditional-antivirus-37377. Accessed on January 2020, 2016.
[2] INTEL. McAfee Labs: Threat Report. Available in: https://www.mcafee.com/ca/resources/reports/rp-quarterly-threats-mar-2018.pdf. Accessed on February 2022.
0 Comments
Please login to post a comment.