This project introduces the concept of deep learning based automatic intracranial hemorrhage recognition & detection from CT Scans images dataset. Purpose of this is to remove role of man from detection purpose to increase efficiency and save time and manpower. CT Scans are used widely in medical for detecting the type of hemorrhage etc.
The task of detecting and identifying hemorrhage is very sensitive as it is a serious health problem requiring often intensive medical treatment. It requires very high precision and accuracy in very short time. Several techniques are available for detection but this project will focus on training a deep learning convolutional neural network model that is trained to detect images and identify the type of hemorrhage. CNNs are more useful because they automatically extract features of targets unlike machine learning algorithms.
Intracranial hemorrhage, bleeding that occurs inside the cranium, is a serious health problem requiring rapid and often intensive medical treatment.
Diagnosis requires an urgent procedure. When a patient shows acute neurological symptoms such as severe headache or loss of consciousness, highly trained specialists review medical images of the patient’s cranium to look for the presence, location and type of hemorrhage. The process is complicated and often time consuming.
We will implement a new algorithm on CT Scans dataset for detecting the Hemorrhage to increase the efficiency of the output results and we will also make it fast enough to give the output in short time in order to save the life of patient.
We will use machine learning and deep learning techniques and different image processing methods to identify the types of hemorrhage. We will use different image identification and processing algorithms, if required the combination of different Neural network and image processing algorithms like YOLO, Faster RCNN and Tensorflows and Keras etc. will be used in order to increase the efficiency of the output results.
Project Proposal
1. High-level project introduction and performance expectation
The key requirement of this project is to create a model that detects intracranial Hemorrhage and its type from the CT Scans of the brain, with high precision and accuracy. We have selected the Deep Learning based YOLO model to perform this task.
Hemorrhage detection is not an easy task especially when images are CT scans. A human can perform this task but targets are not clearly identifiable from naked human eye which results in delayed and poor results. Moreover, the identification & classification of Hemorrhage is a slow process. So, we will implement the algorithm that will make the process fast.
We will design the system that aims to reduce the gap between CNN models and its fast prototyping in FPGA devices. This is achieved by proposing a system-flow to generate FPGA-based accelerators from fully customized CNN models in minutes.
We will use deep learning based convolutional neural networks which processes the input images, learns features of targets, adjusts weights, and then are finally used to detect targets from test images. The main advantage of deep learning is that it automatically learns features of targets but in case of machine learning, we have to manually pass features of target to train the model. Thus, deep learning is faster and more accurate.
Our task is to create a model for automatic detection of hemorrhage. So, we proposed a deep learning-based YOLO model which contains convolutional neural networks. YOLO uses an approach in which we split our images in different regions and then a bounding box is created for each region according to some calculated weights. YOLO is very fast because it processes the whole image at once and some pre-trained models are also available for fine tuning purposes.
We are training YOLO model on our dataset provided by Radiological Society of North America (RSNA). Training results will be shared and in future, we’ll try techniques to improve efficiency of trained models with the help pf FPGA.
2. Block Diagram
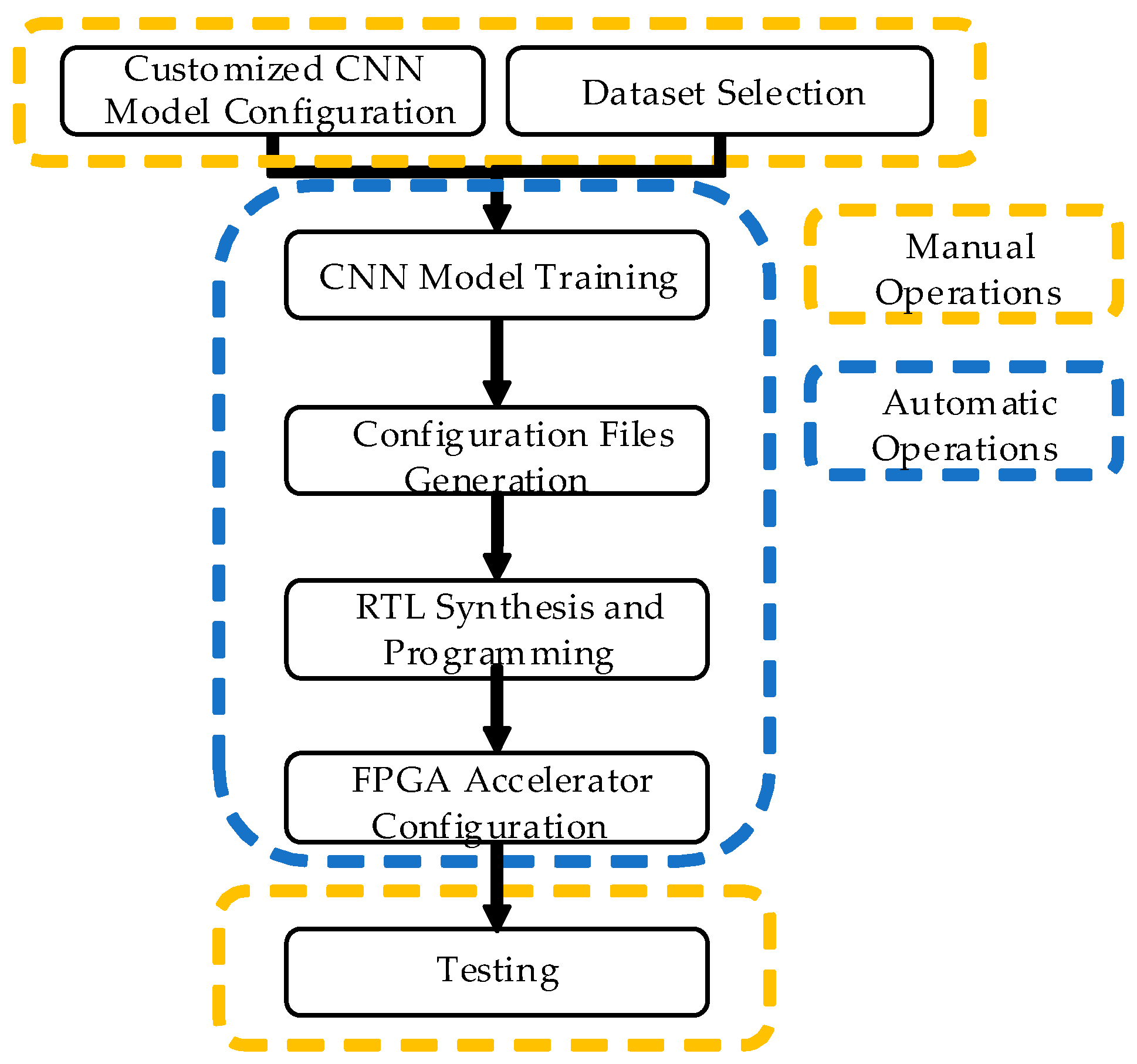
3. Expected sustainability results, projected resource savings
One way to optimize the Neural Network is through computation acceleration, using FPGAs. FPGASs has many benefits for machine learning applications. These include:
- Power Efficiency: FPGAs provide a flexible and customizable architecture, which enable the usage of only the compute resources that we need. Having low-power systems for DNN is critical in many applications, such as ADAS.
- Reconfigurability: FPGAs are considered raw programmable hardware compared to ASICs. This feature makes them easy to use and reduces the time to market significantly. To catch up with daily-evolving machine learning algorithms, having the capability to reprogram the system is extremely beneficial rather than waiting for a long fabrication time of SoCs and ASICs.
- Low Latency: Block RAM inside the FPGA provides at least 50 times faster data transfer compared to the fastest off-chip memories. This is a game-changer for machine learning applications, for which low latency is essential.
- Performance Portability: You can get all the benefits of the next generation of FPGA devices without any code modification or regression testing.
4. Design Introduction
One of the main advantages of accelerating CNNs with FPGAs, rather than with a Central Processing Unit (CPU) or GPU, is the flexibility to design customised hardware to exploit various parallelism sources and use dedicated dis- tributed on-chip buffers to support data reuse. As networks get deep, the number of operations and storage requirements increase. Thus, external memory is required, whose access results in high latency and significant energy consumption. FPGAs present a density of hard-wired Digital Signal Processing (DSP) blocks and a collection of On-Chip Memories (OCMs) that can be used to perform the MAC operations and reduce the number of external memory accesses.
The most common approaches for accelerating CNN inference in FPGAs is focused on exploiting the parallelism of the MAC operations of the convolutions and on approximating the model with fixed- point computation.
Typical FPGA-based CNN accelerators introduce several levels of memory hierarchy. This system will be composed of two on-chip input buffers, one for fetching the feature maps and the other for fetching the parameters from the external memory using a Direct Memory Access (DMA). The data will be streamed into configurable cores responsible for computing the MAC operations. Each core will have its on-chip registers. The on-chip output buffer will store the intermediate results and will output the feature maps. These will be transferred back, if needed, to the external memory. The CPU will issue the controller’s workload, which in turn will generate control signals to the other modules. The multipliers and adder trees present in each core will be pipelined to reduce the circuit’s critical path and increase the throughput.
5. Functional description and implementation
The entire process and every CNN accelerator are controlled with a PC-based specialized GUI system developed for this specific purpose andwill be used to generate a new CNN customized accelerator and test the current accelerator.
Once the CNN accelerator will be programmed into the FPGA device, it will be automatically configured through its communication sub-system. In this configuration process, some parameters will be sent, and the weight values contained in WeightsF will be stored in the off-chip memory.
At this point, the CNN accelerator will be ready to be tested with the GUI. For testing the accelerator, the platform will randomly select and send to the accelerator an image from the dataset. Then, the accelerator will process it and send the results back to the GUI for displaying purposes.
6. Performance metrics, performance to expectation
Using Yolo Algorithm with FPGA we will achieve high recognition rate as well as frame rate along with other parameters, like storage burden, high bandwidth occupation and complex computation. we will try to reduce the size of the network as well as the storage use and computation through advanced network structures, without accuracy loss. We will focus on reducing the computing complexity. Increasing Computing Parallelism, pruning and quantization.
7. Sustainability results, resource savings achieved
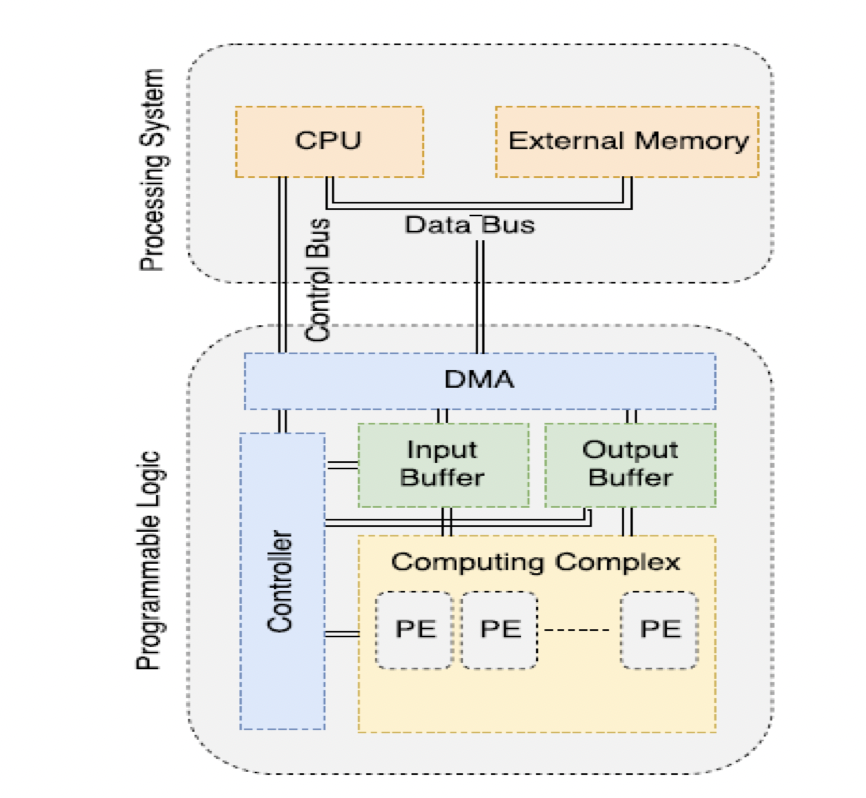
8. Conclusion
In the end we will be able to detect intracranial Haemorrhage with the help of Deep Learning based Neural Network Algorithm. We will implement this Neural Network algorithm on FPGA to increase the efficiency of the output results.
0 Comments
Please login to post a comment.