
In this project, we aim to train a quantized orthogonal Recurrent Neural Network (ORNN) model for speech recognition and implement its inference accelerator on DE-10 Nano using intel HLS. With an era of increased use of AI to facilitate our lives speech recognition at the edge has numerous advantages. From a tiny personal assistant in our phone to the autopilots of self-driving cars, speech recognition has shown impressive performances and has contributed to assisting our lives and making it much easier. Similarly on the other hand having a speech recognition model (which is compute and memory expensive) on an edge device like DE-10 Nano allows us to explore the potential of the Altera FPGAs and to be able to deploy such technologies (e.g., bigger speech recognition model such as conversation bots) offline with a huge power savings (thanks to the configurable architecture of FPGAs). This allows us to integrate and explore the potential usage of edge devices (like DE-10 Nano) in autopilots. Moreover, the orthogonal RNNs are the choice of our project because they have the capacity to learn long-term dependencies like LSTMs but have a much lower parameter count.
What potential expertise do I have to complete this project successfully?
I (Ussama) have 4+ years of experience in working with efficient quantized training of deep learning models i.e., MLPs, CNNs, GANs, RNNs, etc., with a research internship at Xilinx on the same topic. Currently, I am an MS/Ph.D. student at KAUST working at the intersection of Deep Learning and embedded systems i.e., “Edge AI”. Have a detailed look at my LinkedIn (https://www.linkedin.com/in/ussamazahid96/) and Hackster.io profile (https://www.hackster.io/ussamazahid96) which also features my winning project i.e., “Quad96”.
Demo Video
Project Proposal
1. High-level project introduction and performance expectation
Recurrent Neural Networks (RNNs) are the state-of-the-art models for natural language processing (NLP), speech recognition, language modeling, and many time series dependent tasks. RNNs such as Long Short-Term Memory (LSTMs) achieve state-of-the-art performance in learning long-term dependencies at the expense of high memory and computational cost. This computation and memory complexity make them difficult to deploy on small, embedded devices e.g., mobile phones, smart home assistants, self-driving cars, etc. One efficient way of reducing the memory and computational complexity of these models is to use quantized parameters. Either training from scratch is done with quantization or a full precision model is quantized for inference deployment. In both cases, it gives us a much smaller and lightweight model than its full precision counterpart with a little to acceptable drop in accuracy. Recently a new class of RNN models i.e., Orthogonal RNNs (ORNNs) attracted researchers because it offers the same performance as LSTMs but with ~3x lower parameter count. LSTMs use a complicated gating mechanism (up to 16 weight matrices) to learn long-term dependencies but ORNN uses orthogonal weight matrices (up to 6 weight matrices) to achieve the same results.
In this project, we aim to train quantized ORNNs for image and speech recognition and develop an efficient inference accelerator on DE-10 Nano. It will potentially be a quantized ORNN model. The training of the RNN will be configured to have a variable bit-width for weights and activations to allow for exploration. After the successful training of the ORNN, we will develop an accelerator for the trained model, in intel HLS. This accelerator is also expected to be variable with respect to the precision of the weights and the activations of the trained model. The accelerator will be controlled by the host code running on the ARM processor for all the input/output communication/start/stop etc. Moreover, after the successful implementation of the accelerator, we aim to make it a scalable architecture and explore the resource utilization vs throughput trade-off.
This accelerator will be specialized for quantized ORNN and hence will result in much better performance per watt as compared to GPUs and CPUs while achieving the same results as compared to LSTMs. To the best of our knowledge, we are the first ones to deploy ORNN on an edge device as opposed to LSTMs which have been deployed on different embedded devices. Please refer to the “Expected sustainability results, project resource savings” section for further details. Moreover, we will provide a complete open-source stack from training variable precision RNNs/LSTMs up to implementing the accelerator and deploying and running them on DE-10 Nano. This will allow future researchers to explore the potential of DE-10 Nano and other intel-based FPGA devices for ML/AI acceleration.
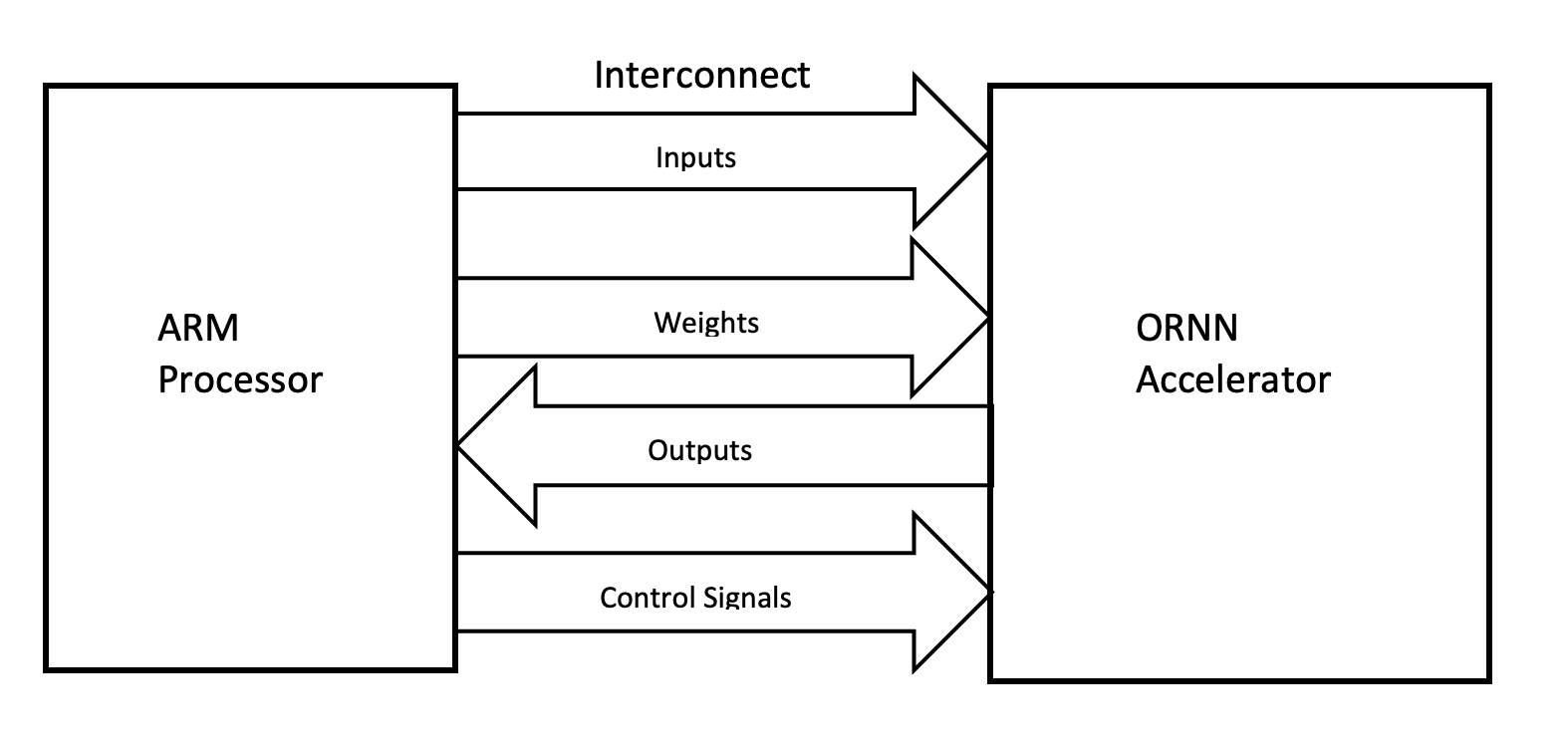
2. Block Diagram
ORNN Accelerator with ARM Processor
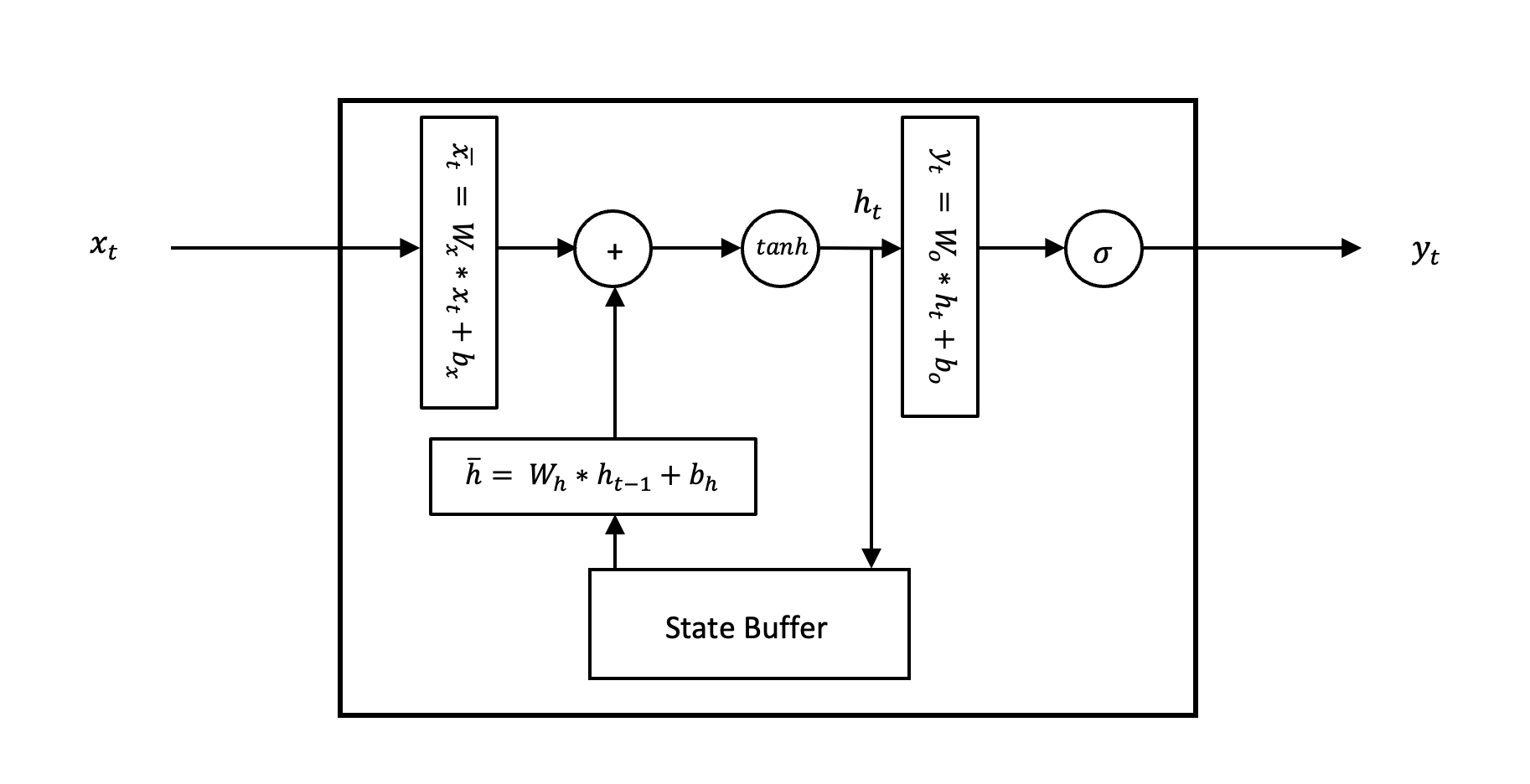
ORNN Cell
3. Expected sustainability results, projected resource savings
As mentioned in the High-Level Project Introduction, LSTMs based accelerators have much higher memory costs because of having up to 16 different weight matrices. The equations for an LSTM are:
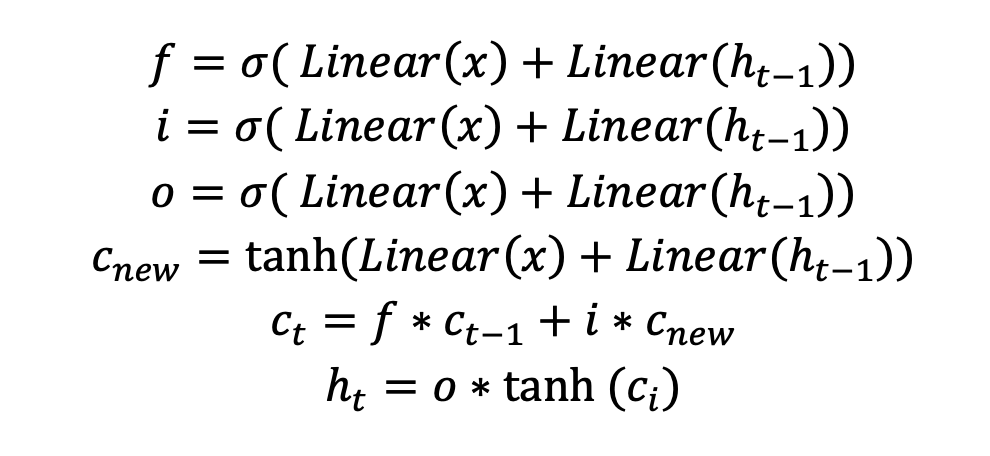
Where:
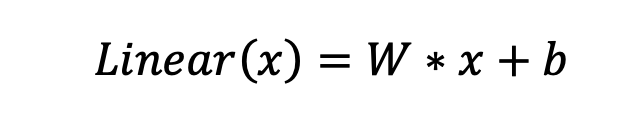
And here, every linear layer is having a different set of W and b
and b resulting in 16 different parameters. Whereas an ORNN has the following equations:
resulting in 16 different parameters. Whereas an ORNN has the following equations:
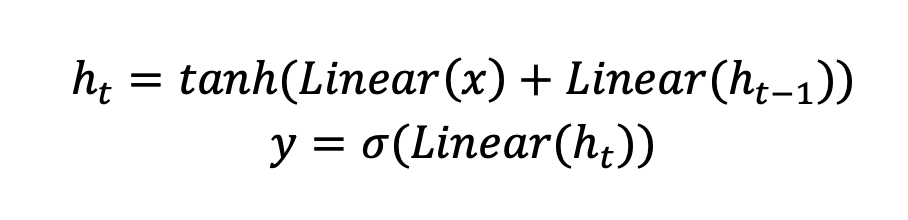
It can be clearly observed that ORNN has a much lower parameter count and computational cost. A quantized accelerator for ORNN will be much lightweight and efficient as compared to the LSTM accelerator and has much better performance per watt than GPU and CPU implementations.
4. Design Introduction
The design of the RNN accelerator is a streaming dataflow architecture and it has one Avalon Memory-Mapped interface which reads and writes to the DDR memory and one Avalon register agent interface to have access to the CSR of the accelerator from the ARM processor. The accelerator is written using intel HLS i.e., C++ which is a very well know high-level programming language. It includes many architecture-based optimizations using pragmas which makes it suitable to run on any Altera FPGAs. HLS based accelerators are becoming more and more common among the research community and are being adopted in the industry as well because of a higher level of abstraction offered by HLS as well as high performance. This HLS based accelerator design is simple and readable yet, scalable and high performance.
This accelerator is implemented on Terasic’s DE10 Nano device which has an ARM hard processor along with the FPGA fabric. The hard processor and the FPGA fabric are connected together with a number of high bandwidth Avalon bridges as well as a lightweight bridge. This embedded platform is particularly suitable for the accelerator design we proposed. The high bandwidth Avalon bridge allows to read and write directly to the DDR memory of the ARM processor and similarly, the lightweight bridge allows to control of the accelerator i.e., CSR access. Furthermore, we can leverage the ARM processor to use this accelerator under Linux which allows for the control of FPGA fabric from a variety of high-level languages e.g., python, C++, etc. Linux also allows us to integrate this accelerator in different application domains by interfacing it with a camera, network, internet, bluetooth, WLAN, etc.
5. Functional description and implementation
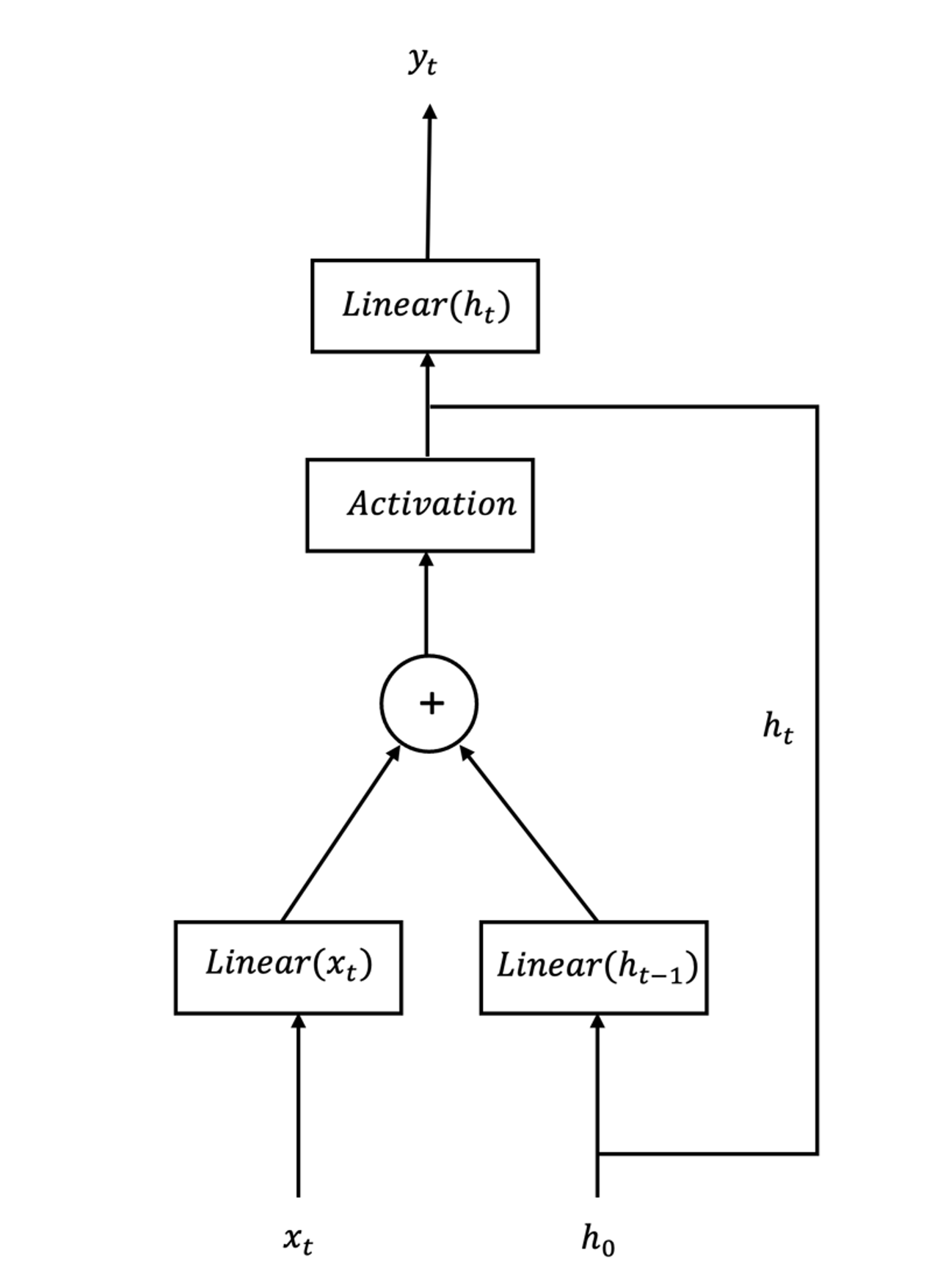
The accelerator for Orthogonal RNN is a streaming dataflow architecture where the inputs are read from the DDR memory of the processor and weights are stored on-chip. The output scores for the given input are also written back to the DDR memory. Due to the recurrent nature of the RNN cells, each input column of the sequence i.e. (xt) is processed at a time. The accelerator has one Avalon memory-mapped interface which is responsible for reading and writing data to and from the DDR memory, and it has one Avalon agent interface for interaction with the control and status register of the accelerator.
The inputs from the DDR memory which comes from the Avalon memory master interface are packed to 64-bits and are first converted to the stream so that the rest of the accelerator architecture can process this sequentially in a pipelined fashion. The input stream then goes to the ORNN cell where the sequence is processed for each time step pipelined time-folded fashion.
The Linear layer engine in the ORNN cell is designed to work with any bit-width of inputs, weights, and output. And each of them (input, recurrent, and output) processes a patch of the matrix multiplication (of the input/recurrent with the weights) at a time, defined by the number of processing elements (PE) and Single Instruction Multiple Data (SIMD) lanes of the Linear layer engine. The number of PEs defines the output parallelism i.e., how many output elements will be processed in parallel. Similarly, the number of SIMD lanes defines the input parallelism, i.e., how many inputs will be processed at a time. This folded (time-multiplexed) matrix multiplication engine performs the Linear operation on input and the recurrent connection in a fully pipelined way and allows the resources vs. throughput trade-off by adjusting the PEs and SIMDs. This idea was inspired by Xilinx FINN. Moreover, for the ORNN activation functions, we have used two activation functions i.e., Tanh and ModReLU and we implemented the Tanh with a lookup table which was also stored on-chip.
The dataflow diagram of the ORNN Layer written in intel HLS is given below.
6. Performance metrics, performance to expectation
For the Quantized ORNN, we trained and implemented 2 different networks at different precision of input, weights, recurrent input, and output. Among both implementations, the target metrics were resource utilization, throughput (frames per second (FPS)), and accuracy.
7. Sustainability results, resource savings achieved
As discussed in the previous section that the ORNN cell has only 6 weight matrices as compared to the LSTM cell which has 16, and the memory utilization for the weights is 2.6x lower for ORNN as compared to LSTM. Moreover, there are also fewer mathematical operations in ORNN. FPGAs allow us to have accelerators that can operate on the user-defined bit width. Lowering the bit width of the ORNN cell from 32bit float to 4/8-bit fixed point allows for a significant saving in the memory and compute resources on FPGA. Now, these saved resources can be used for processing more data in parallel, i.e., by scaling up the low precision accelerator, we can achieve high throughput and low latency without hurting the accuracy of the full precision model.
As discussed earlier, our accelerator implementation is customizable for any precision of input, weights, activations, and output as well as scalable. For this competition, we will demonstrate the two accelerators on two different datasets with multiple precisions and PEs and SIMDs. The tables given below summarizes all the results.
|
Dataset |
Neurons |
Bit Width |
Test Accuracy [%] |
|||
|
Input |
Weights |
Recurrent |
Output |
|||
|
AudioMNIST |
128 |
8 |
4 |
8 |
16 |
91.38 |
|
MNIST |
4 |
4 |
8 |
16 |
91.31 |
|
Table 1: Training Performance of ORNN
|
Dataset |
Input |
Recurrent |
Output |
Avg. FPS On DE10 |
Avg. FPS on CPU (i3-4030U) |
|||
|
PE |
SIMD |
PE |
SIMD |
PE |
SIMD |
|||
|
AudioMNIST |
4 |
1 |
4 |
8 |
4 |
4 |
2569 |
781 |
|
MNIST |
4 |
1 |
4 |
4 |
4 |
4 |
1460 |
2650 |
Table 2: Summary of Accelerator Performance
|
Dataset |
LUT [%] |
Block RAM [%] |
DSP [%] |
|
AudioMNIST |
19 |
41 |
54 |
|
MNIST |
19 |
25 |
32 |
Table 3: Resource Utilization
Finally, all of the code related to this project is open source and available under the BSD-3 license at https://github.com/ussamazahid96/ORNN-Nano.
8. Conclusion
In this project, we developed and implemented an Orthogonal Recurrent Neural Network (ORNN) accelerator on the DE10 Nano and demonstrated its capabilities by training a quantized ORNN on MNIST and audioMNIST datasets. The scalable and variable precision accelerator is developed using intel HLS (C++) which uses Avalon Memory-Mapped and Avalon Lite interfaces. By running the board under Linux, we provided a python-based host code driver and userspace APIs for the accelerator which can manage, interact and communicate with the ORNN accelerator. The resulting development stack i.e., from accelerator development in C++ to the high-level python-based APIs are all open-sourced and are adaptable to any application domain. We believe it to push forward the development and the usage of intel-based SOC-FPGA devices in deep learning inference acceleration i.e., edgeAI and IoT.
0 Comments
Please login to post a comment.