
Mucilage pre-detection system determines the possible locations where mucilage can appear using sensors to detect the amounts of nitrogen and phosphate in the water, a thermostat to determine water temperature and transmit this information to the authorities.
Demo Video
Project Proposal
1. High-level project introduction and performance expectation
Due to the global warming and environmental pollution, sea creatures are in danger and water resources are damaged. Because of the deterioration of environmental conditions, the balance of water resources is disturbed. As a very recent example, in the last few months, wildlife of the Marmara Sea has been in grave danger because of something we call mucilage. Mucilage is a slimy, sticky structure that is formed by the combination of many biological and chemical conditions. This structure is created by the overgrowth of plant-based organisms called “phytoplankton” and is mostly seen in polluted and warmer areas of the sea because polluted areas are rich in nitrogen and phosphate. When mucilage first forms on the water, sunlight gets blocked so underwater plants can’t get enough light to maintain the ecosystem, then since mucilage is sticky, organisms like fish or jellyfish who most likely will have to go up for oxygen get stuck in the substance to starve and die.
We are planning to run this project together with the city government to reduce and prevent mucilage in the Marmara Sea. Intel FPGA devices will be used in this design because Intel FPGA devices are strong, reliable, robust, and have good performance.
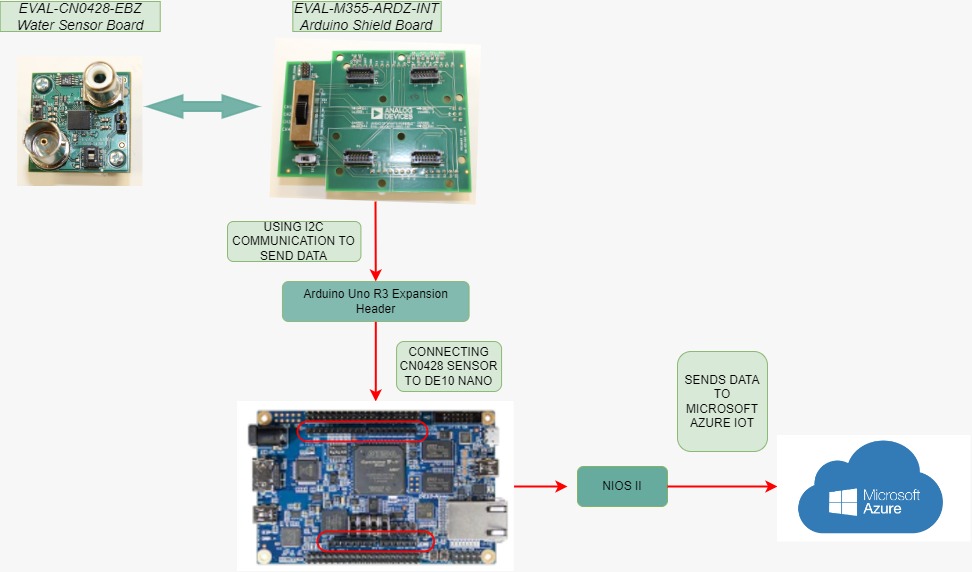
2. Block Diagram
3. Expected sustainability results, projected resource savings
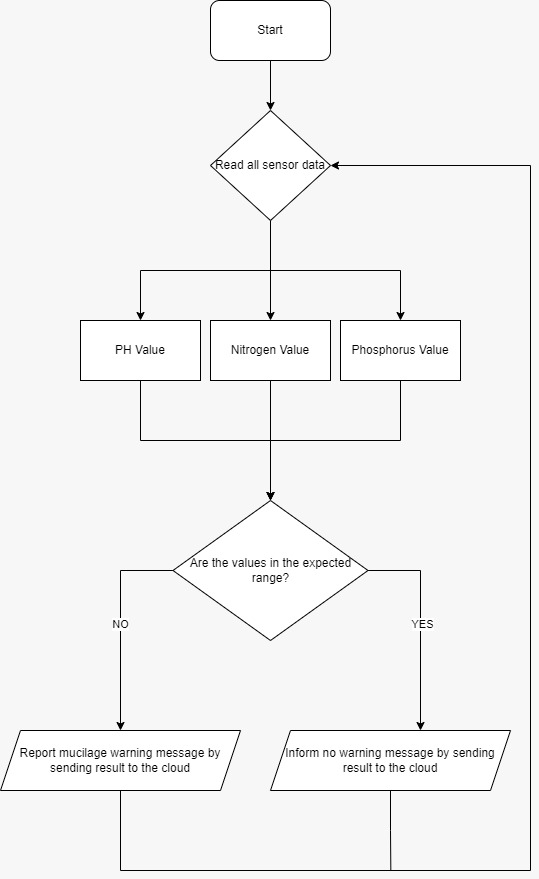
The mucilage pre-detection system measures the nitrogen, phosphorus, and pH level of the water. If the levels of these components are higher than it is expected, the system reports a mucilage warning message by sending the results to the cloud. This design is expected to last very long on the field because it is planned to get its power from the local grid also Intel FPGA devices are used to make the system even more durable. For this project, it is given importance to the quality of the devices as the devices will be in contact with water.
The reason why we examine the values of phosphorus, nitrogen, and pH is these elements damage seawater. The increase in phosphorus and nitrogen density decreases the pH value. In short, it causes the basic seawater to become acidic. This situation damages the ecological balance in the sea. We want to detect it at the initial stage of mucilage formation. Our estimated success in preventing mucilage by 60 to 90%, since thanks to our system we will detect mucilage even before it appears and let the authorities know when to clean areas, we also expect a general decrease in water pollution since we will be able to find causes of pollution easier by looking at areas that have more risk of mucilage forming.
4. Design Introduction
We propose the idea of a pre-detection system as a solution to mucilage problem and marine pollution. Mucilage pre-detection system determines the possible locations where mucilage can appear using sensors to detect the amounts of nitrogen and phosphate in the water, a thermostat to determine water temperature and transmit this information to the authorities. As the main reason for mucilage in the Marmara Sea is marine pollution, detecting mucilage before it appears will be the key to find the polluted areas and taking the first step in having a cleaner, safer, habitable sea, both for wildlife, and city life surrounding the sea.
5. Functional description and implementation
Our idea is to implement an algorithm on the FPGA to measure pH, nitrogen density, and phosphorus density in the water using sensors from Analog Devices. We will put these systems on the shores of Marmara Sea and use Microsoft Azure IoT to get warnings from the FPGA system, since all these systems will have unique IDs and locations, we don’t need GPS to know where the mucilage may form. Our primally goal is to place the system in the southern regions of Marmara Sea because research shows that the southern region was the latest victim of this problem. Also, since our system is on shores that all have their own electrical infrastructure, we can use the grid to power our devices. If this proves to be a problem, we can always use rechargeable batteries that get charged periodically but it isn’t an efficient option since it generates a lot of manual labor. This system is highly sustainable since the only parts that can deteriorate over time are the sensors we put in the water, power can be supplied by the city, or we can change batteries periodically.
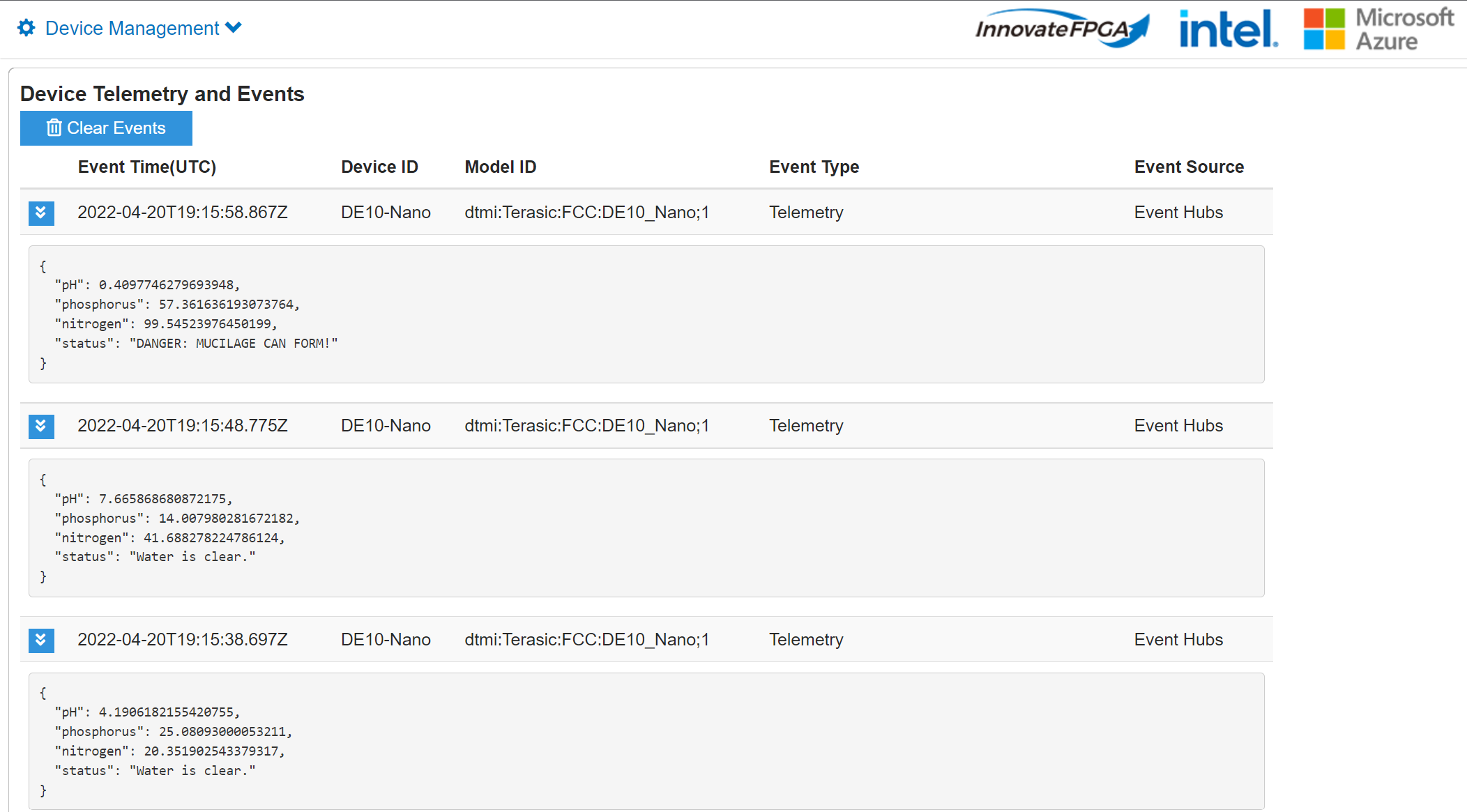
To implement this system, Quartus Prime is used, and to make FPGA cable connections with the sensor using NIOS II. We connected the CN0428 sensor to the Arduino Headers of the FPGA between the CN0428 and the FPGA and used an I2C communication system to communicate. After that, the data obtained from I2C communication is sent to Microsoft Azure IoT. The results from the system are seen as shown below.
6. Performance metrics, performance to expectation
Total carbon, inorganic carbon, total organic carbon, and total nitrogen values of seawater were analyzed. Total carbon, inorganic carbon, total organic carbon, and total nitrogen values of sea saliva were also determined. The pH value of mucilage is between 6.70 - 6.94, and the pH value of seawater is between 7.97 - 8.15. It is seen that mucilage is acidic and seawater is basic. In the nitrogen + phosphorus experiment, it was observed that the pH value of seawater decreased to 7.13-7.25, and the environment became acidified by decreasing to 6.4 in mucilage. Mucilage Pre-detection System can measure the phosphorus, nitrogen, and pH values. Thus, authorities will be able to obtain mucilage warning by using our system. The system is designed by considering the data parameters that trigger the formation of mucilage by scientists. If water has,
a pH value between 6.70 - 6.94
a Nitrogen Density of more than 40%
a Phosphorus Density of more than 60%
With these parameters, the system will detect if there is a mucilage formation or not and will send the data by using Microsoft Azure IoT. In addition to that, in the implementing part, we can’t expect to measure some values due to the limited sensor types. In this design, CN0428 device is used to measure the minerals, pH, and temperature of the water. Thanks to Analog Devices, sensors suitable for this project were sent to us. However, this CN0428 sensor system has limited sources on the internet. The sensor has some specific codes which are suitable with Arduino boards but when the design was configured on a more professional platform with a device like DE10 NANO FPGA, there were not enough codes of CN0428. Thus, this situation may cause the progress of the project to be different than planned.
Intel Fpga devices have lots of features. There are many ways to make connection between a device and FPGA. In our design, we chose the I2C communication protocol. With this feature, Intel FPGA devices are qualified, compatible, efficient, and high-tech. De10 Nano Device is a very convenient device to realize our project. Thanks to this device, has allowed us to realize a useful project for the world.
7. Sustainability results, resource savings achieved
8. Conclusion
In conclusion, this project is designed to eliminate the mucilage problem in the Marmara Sea by detecting pre-emptively and acting before the problem even occurs. This way it is planned to achieve a gorgeous and healthy sea both for people living on the shores and the wildlife living inside. In addition, with the help of the cloud, the system will be constantly active. Thanks to the data obtained in the past, we will be able to predict more easily in the future.
0 Comments
Please login to post a comment.