The device is a co-processor that accelerates matrix operations. Its design supports the completeness of matrix algebra, which was proved in the research of hardware and software complexes. This completeness is provided by the isomorphic mapping of vector algebra to the matrix one. Vector algebra was chosen because of intuitive implementation of the one vector with fixed length computation in hardware without significant costs. The description of matrix algebra through vector`s one allows to provide full support of matrix algebra. As the signature operations were chosen the operations of primitive-program algebra (PPA), which are commonly used in programming.
In the co-processor`s architecture is used the logical-subject principle, according to which control and executive parts are separated and connected by forward and backward connection. To support isomorphic mapping, a special block is used – Isomorphism Support Unit (ISU). Its goal is to calculate addresses and control operations on vectors. In addresses calculation the counters are used. And for the work of the entire unit the responsibility is brought by the special control structure, which is described by the logical equations for the control signals. All this allows the programmer not to worry about the implementation of matrix computations. The programmer works directly with Control Unit (Ctrl Unit) of the entire co-processor. The Ctrl Unit supports all PPA operations as it is based on the RISC architecture.
Input-Output Unit (IO Unit) contains modified multi-lines Serial Peripheral Interface (SPI) in half-duplex mode. The interface besides SPI`s standart control signals, such as synchronization signal and device selection, has also the interrupt signals from the co-processor. And the data bus uses multiple lines to transfer the data fast. IO unit has a counter that calculates the memory address for reading and writing, it allows to work independently of the Ctrl Unit. In order to get and access the co-processor`s memory a special key should be given. If the given access key is incorrect, the address counter will be switched on timer mode. The access to the co-processor is denied until the counter will be overflowed, then an access key should be given again. For the correctness of the operations and description of the software interface is responsible for the control scheme, which is described by the transition diagram of the state machine. All transitions occur at the rising edge of the synchronization signal.
The project uses partial cells reconfiguration. Namely, for control circuits of IO Unit, ISU and decoding schemes of instructions in Ctrl Unit. Reconfiguration of ISU control circuit allows to declare new operations and change the old ones. Reconfiguring IO Unit`s control circuit allows to change the software interface. And change the decoding scheme - the instructions themselves. Also, the parameterization of the co-processor allows to adapt it to certain limitations of the different FPGA chips.
One of the main reasons for using FPGA is the use of partial cell reconfiguration, as this technology is one of the main advantages of FPGA. Parameterization of the co-processor allows to implement it on a wide range of devices. Also, parts of the co-processor are used as blocks in the Platform Designer tool, which will allow them to be used in other projects.
Project Proposal
1. High-level project introduction and performance expectation
Recently, in the world of embedded systems, there has been a trend towards implementing complex algorithms for processing and modifying large amounts of data. Among them are signal processing (photo, video or analog signals), calculations of coordinates in three-dimensional space, and the implementation of neural networks and algorithms for their training (known as Tiny ML for embedded). When implementing all the above algorithms, directly or indirectly, matrix operations are used.
In this project the acceleration of matrix operations is realized in hardware. The hardware design was developed during hardware-software complexes research. One of the main points in developments was the ensureness of functional completeness. Thus to achieve the completeness the isomorphic mapping on vector algebra was used, that has already proven functional completeness. Vector algebra was used as vector data type is similar to matrix one and due to the ease of vector calculations implementation in hardware. However in assembly language all variables are matrices. The correct transition from vector to matrix are provided by hardware. The mediator between the programmer and the data is naming data model. Here the name is represented by a set of parameters such as the address of initial element of the matrix and matrix dimensions. The architecture is developed using logic-subject principle, according to which control and executive parts separates from each other and have forward and backward connection. This principle provides a high level of modification, which simplifies the development of future versions.
The co-processor has an onboard I/O system. The I/O system is based on Serial Peripheral Interface (SPI) but has multi-line data bus and works in half-duplex mode. Besides the standard SPI control lines it has the lines for interrupt identification that co-processor generates. Along with the hardware interface comes the software. The software interface provides fast and safe access to data. The safety is ensured by requesting an access key each time the main device selects the co-processor. The entire software interface is implemented in hardware by describing it as an end-state machine.
The co-processor uses partial LUT reconfiguration technology that allows to redefine the co-processor`s work. For instance, it gives the possibility to set a new matrix operation or modify an existing. As partial LUT reconfiguration is used in the structure which is responsible for vector-to-matrix transition. Another use of this technology is in I/O system, where it allows to rewrite the software interface. Thus, the device can be used in a wide range of applications due to its flexibility provided by partial LUT reconfiguration.
The device can be used in embedded systems, especially for Tiny ML applications. It can accelerate computer vision and image processing algorithms, neural networks, etc. Co-processor can work in robotics projects by accelerating the computations of the movements. Also it is suitable for processing a big amount of data (relatively to embedded applications). It allows to free the central device from a large amount of calculations, giving them to the co-processor.
In majority, the targeted users are embedded developers who want to add Tiny ML to their projects, or just who need a fast processing of the big data.
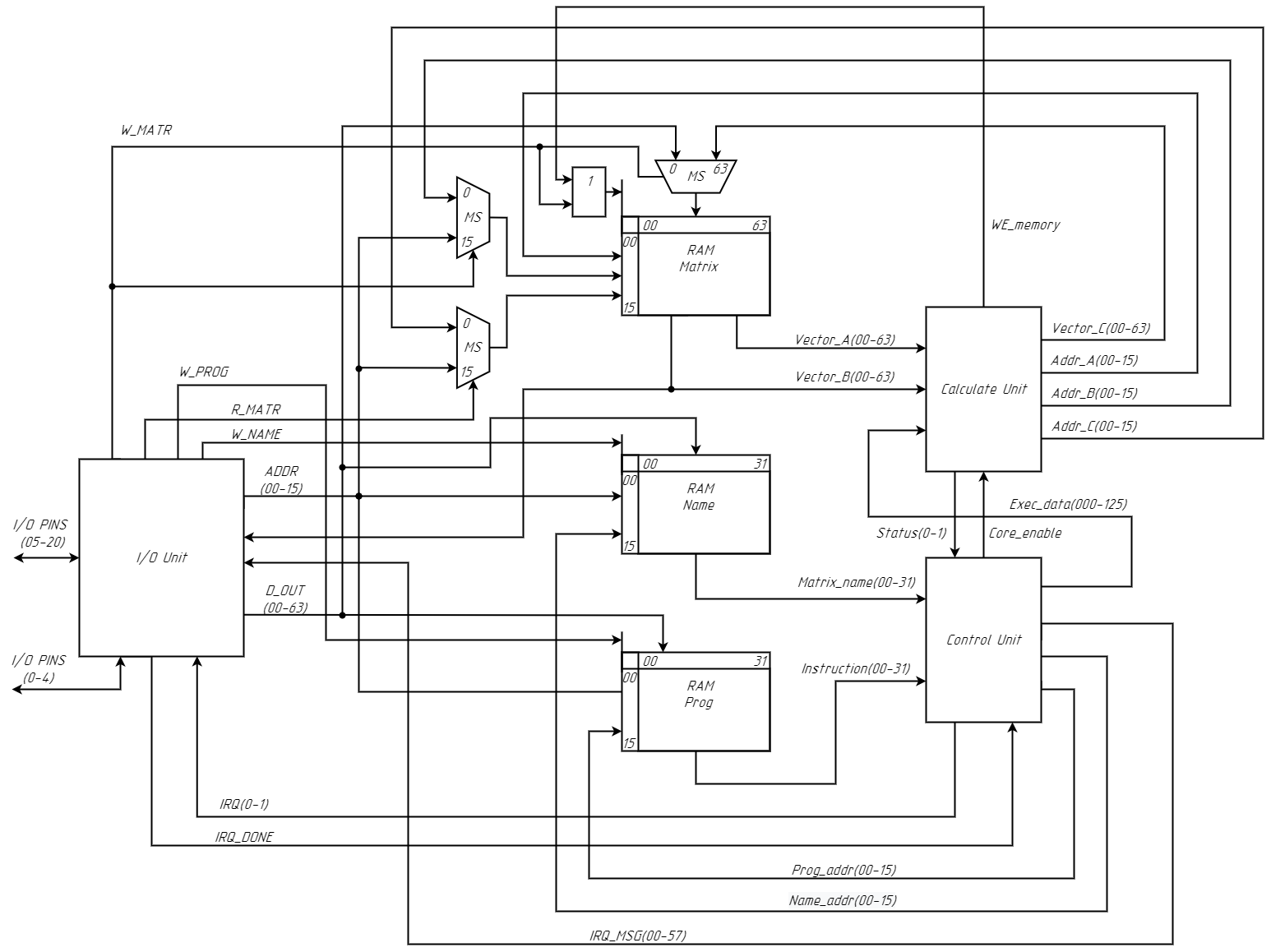
2. Block Diagram
Top-level Drawing
3. Expected sustainability results, projected resource savings
The goal of the project is to accelerate matrix operations and simplify its use. For that reason, a matrix co-processor has been developed, which should efficiently execute matrix operations and at the same time provide functional completeness. Also, the design should ensure ease of programming and implementation in projects. In addition, the design should support the reconfigurability to cover a wider range of applications. And last but not least is to make the design flexible to simplify the development of the further versions.
Features:
* Designed with taking into account theoretically proven Turing-complete algebra for matrices.
* Provides efficient custom interface, which ensures fast and safe access to data.
* Ease of programming provided by classic RISC based commands.
* Flexible architecture that simplifies the development of new versions.
* Using partial LUT reconfiguration to modify or change matrix operations and software I/O system.
4. Design Introduction
Matrix co-processor works in pair with main device (mainly with microcontroller or micro PC). Its purpose is to accelerate matrix operations and algorithms that use it. While also simplifying the way that programmers work with matrices. Programmers should not care about implementation of these operations, as the hardware provides its support.
The device can be used in embedded systems, especially for Tiny ML applications. It can accelerate computer vision and image processing algorithms, neural networks, etc. Co-processor can work in robotics projects by accelerating the computations of the movements. Also it is suitable for processing a big amount of data (relatively to embedded applications). It allows to free the central device from a large amount of calculations, giving them to the co-processor.
In majority, the targeted users are embedded developers who want to add Tiny ML to their projects, or just who need a fast processing of the big data.
5. Functional description and implementation
6. Performance metrics, performance to expectation
7. Sustainability results, resource savings achieved
1. Matrix co-processor
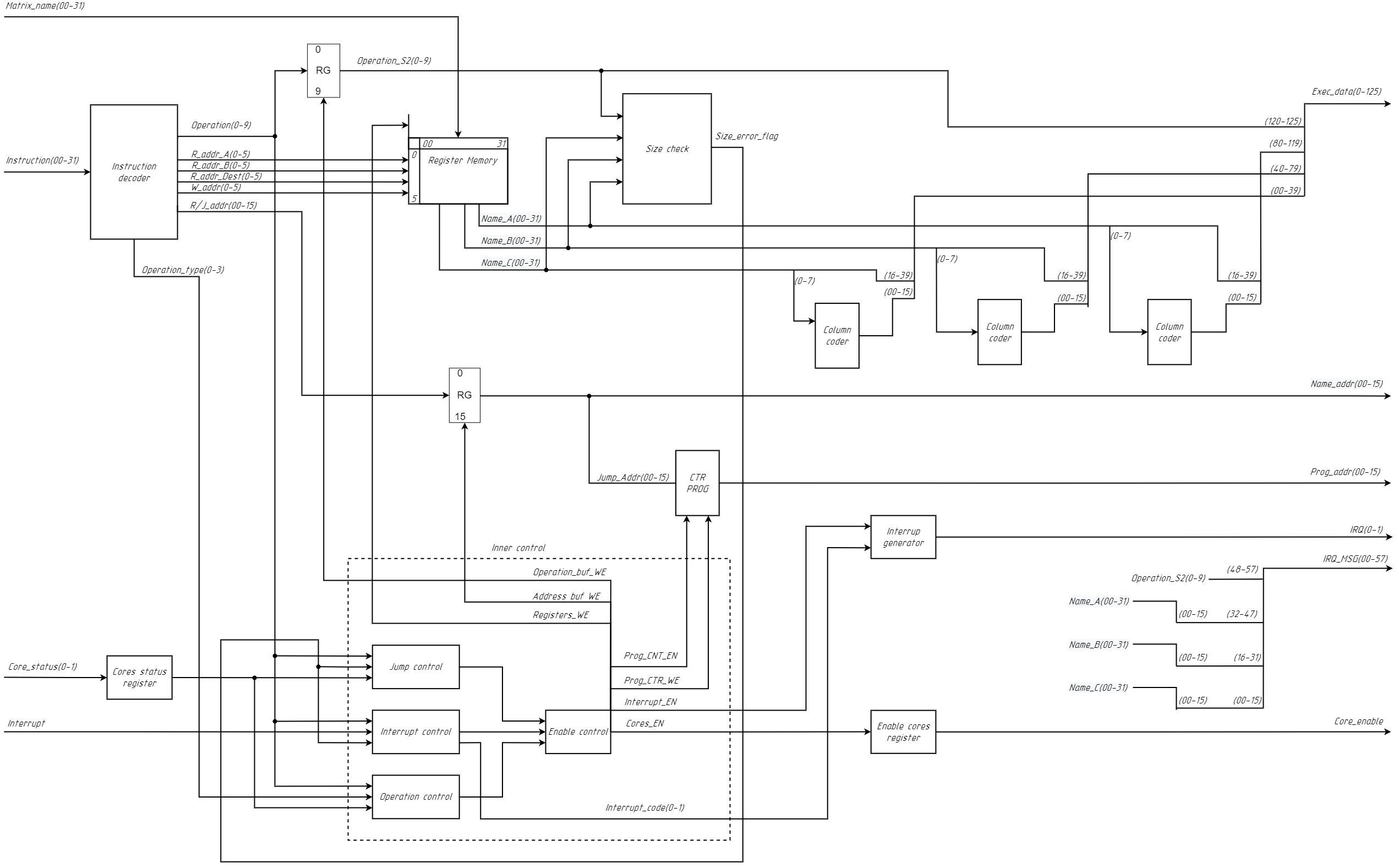
2. Control unit
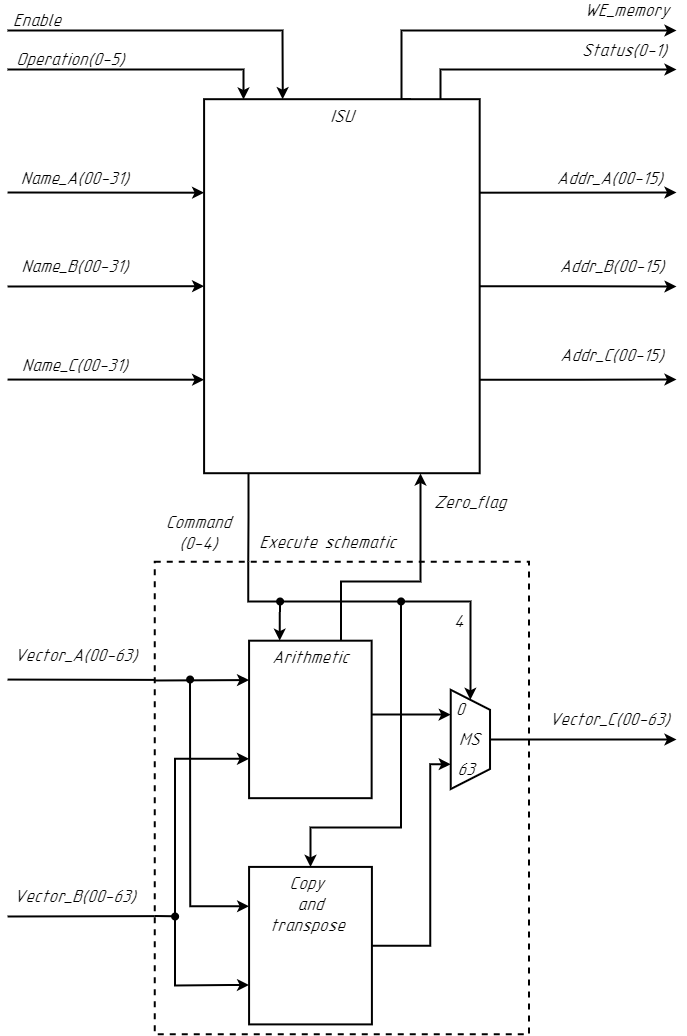
3. Calculate unit
4. Arithmetic
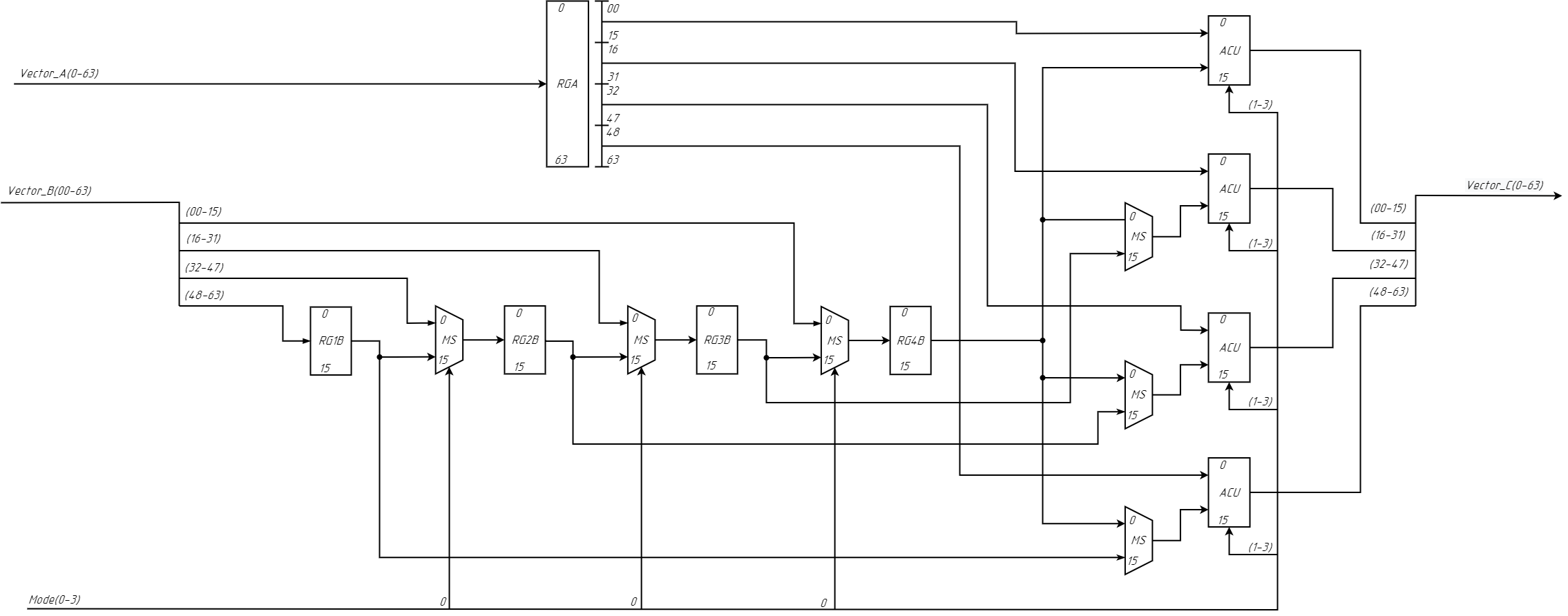
5. ACU
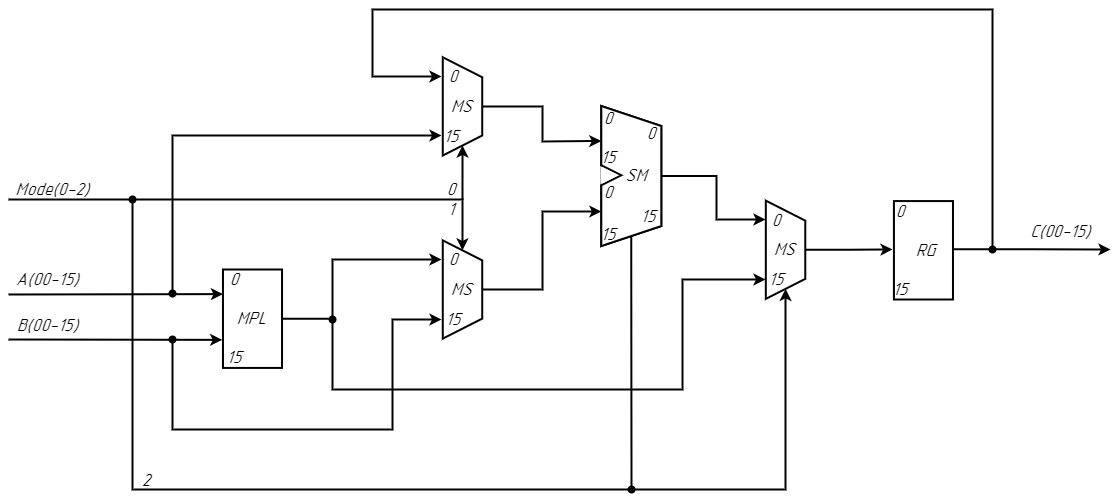
6. Copy and Transpose
![]()
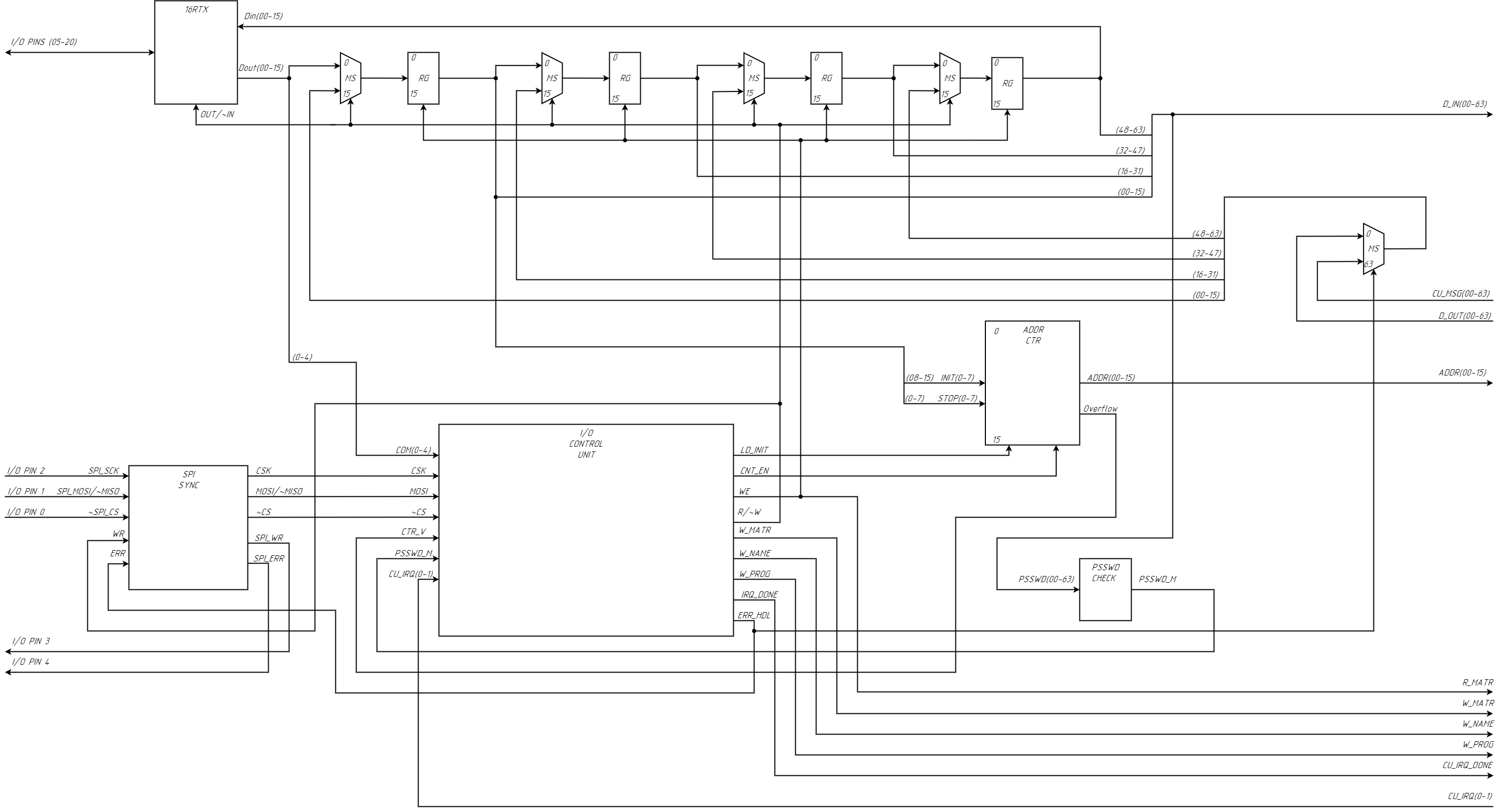
7. IO Unit
8. Conclusion
0 Comments
Please login to post a comment.