
Nowadays, the number of network-based devices (IoT
devices) has been increasing. They can be controlled by
other network-based smart devices such as smartphone,
personal computer or personal assistant robots, and so on.
These systems or devices should have user-friendly interface design. In this project, we propose easy-to-use and
intuitive user interface design for them. We employ gesture controlling UI.
Demo Video
Project Proposal
1. High-level project introduction and performance expectation
There are around 195 countries around the world, many of them has their own native languages that they can easily use in their daily lives, but there is only one unified lagnuage that everyone learned to use without going into any classes to learn it which is body language, body language consists of set of gesture that we use on our daily lives if we can't tell our ideas or our needs clearly with our native language.
Our project is called advanced gesture recognition, our main focus on autonomous applications which can easily be controlled by using gestures instead of manual control, or using touch screens. it is easy to be learned if it can be used easily by nearly anyone because it depends on body language by using normal gestures that we use in daily lives our focus will be on deploying these ten gestures below.

2. Block Diagram
.jpg)
3. Expected sustainability results, projected resource savings
- Speed: Speed is enough to detect real-time hand movements using cam of fps 24
- Accuracy: has an accuracy of minimum 85% in detecting gestures
- Resources: leaving at least 10% of resources non used for more performance
4. Design Introduction
Our project is focusing on implementing advanced technique in gesture recognition with the help of terasic de-10 nano kit, and analog devices accelerometer sensor,
The project is divided into two parts, First part is implemented on processing system of Arm Cortex A9 in de10 nano for communicating with camera , accelerometer and hdmi screen, where at first it pre-process the data from the two steams, and convert them into fixed size arrays, to be sent to the processing logic on Cyclone V ,
The second part is implemented on Cyclone V where it consists of three modules, which are Pre-trained 3D-CNN module for Gesture using camera, Pre-trained ANN module for gesture using accelerometer and data-fusion module for the two neural networks using ANN.
after data is processed in the accelerator implemented on cyclone V, it is sent back to Arm Cortex A9 to be displayed on screen or on a terminal
5. Functional description and implementation
Gesture Net Model
Training
Cam Model
We used squeezenet 1.1 pretrained model for processing camera part, where we transformed image sequence of 28x28x3 and 64 frames to full picture of 224x224x3 by collecting the frames in a single using opencv for example the figure on the right.
Cam Net Structure:
| Layer Name | Input Size | Output Size | Cam Net Model |
| Transform | 28 x 28 x 3 x 64 | 224 x 224 x3 | Transform |
| Conv 1 | 224 x 224 x 3 | 64x111x111 | conv(3x3,3) + ReLU |
| MaxPooling | 64 x 111 x 111 | 64 x 55 x 55 | MaxPooling,3 |
| fire 2 | 64 x 55 x 55 | 128 x 55 x 55 | Fire 2 |
| fire 3 | 128 x 55 x 55 | 128 x 55 x 55 | Fire 3 |
| Max Pooling | 128 x 55 x 55 | 128 x 27 x 27 | MaxPooling,3 |
| fire 4 | 128 x 27 x 27 | 256 x 27 x 27 | Fire 4 |
| fire 5 | 256 x 27 x 27 | 256 x 27 x 27 | Fire 5 |
| Max Pooling | 256 x 27 x 27 | 256 x 13 x 13 | MaxPooling, 3 |
| fire 6 | 256 x 13 x 13 | 384 x 13 x 13 | Fire 6 |
| fire 7 | 384 x 13 x 13 | 384 x 13 x 13 | Fire 7 |
| fire 8 | 384 x 13 x 13 | 512 x 13 x 13 | Fire 8 |
| fire 9 | 512 x 13 x 13 | 512 x 13 x 13 | Fire 9 |
| Conv 10 | 512 x 13 x 13 | 11 x 13 x 13 | Conv 1x1, 3 |
| Global Avg Pooling | 11 x 13 x 13 | 1 x 1 x 11 | Avg Pooling (13 x 13) |
| Flatten | 1 x 1 x 11 | 11 | Flatten |
Fire Module
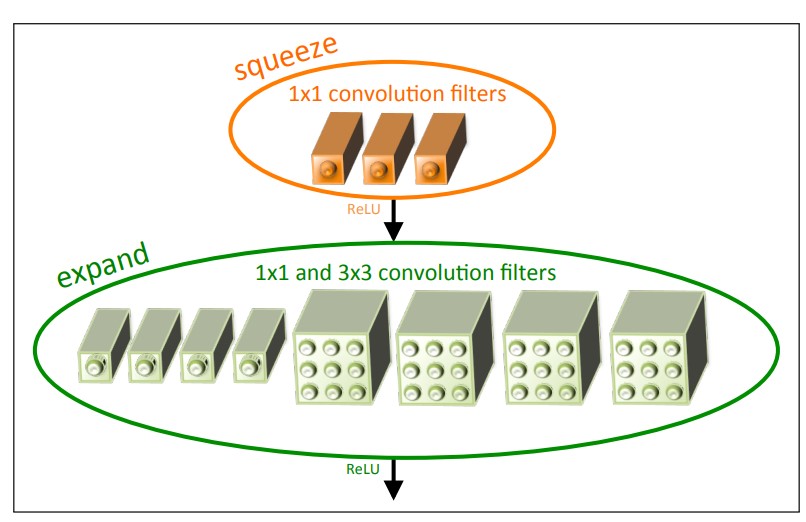
Accelerometer Model
For accelerometer, We used dnn model for predicting the data from an array of data with dimensions 1x1x192 where 192=64*3 which means capturing a sequence of 64 frames where each frame has 3 coordinates for the wrist x,y, z
| Layer Name | Input Size | Output Size | Acc Net Model |
| layer1 | 1 x 1 x192 | 1 x 1 x 30 | FC(192,30)+ReLU |
| layer2 | 1 x 1 x 30 | 1 x 1 x 30 | FC(30,30)+ReLU |
| layer3 | 1 x 1 x 30 | 1 x 1 x 11 | FC(30,11)+ReLU |
| classifier | 1 x 1 x 11 | 1 x 1 x 11 | FC(11,11)+Softmax |
| Flatten | 1x1x11 | 11 | Flatten |
Fusion Model
For Data Fusion, there are three different ways for data fusion Observation level Fusion, Feature Level Fusion, Decision-level Fusion, where we chose the third one because it is the one that is most suitable for our case where we made dnn for data fusion that takes input with size 1x1x22 where 22=11x2 which is the output from camera squeeze net part concatenated with the output of accelerometer dnn part then the output of the DNN is the final decision for the class.
| Layer Name | Input Size | Output Size | Fusion Net Model |
| flayer1 |
[1x1x11], [1x1x11] |
1x1x22 | Transform |
| flayer2 | 1x1x22 | 1x1x15 | FC(22,15)+ReLU |
| fclassifier | 1x1x15 | 1x1x11 | FC(22,11)+Softmax |
| Flatten | 1x1x11 | 11 | Flatten |
Inference
The inference model for the three models were implemented using openCL Kernels where the kernels which are implemented are conv 3x3, conv1x1, maxpool, avgpool, fully connected,
where streaming the input data was through ethernet using websocket and python to send and receive cam and adxl data from pc to DE10-Nano
6. Performance metrics, performance to expectation
- Accuracy: can be measured by confusion matrix where it is expected that by datafusion we are getting more accuracy because some of gestures depend only on palm movement which can be detected using accelerometer-based track and some of gestures depend only on finger movement which can be detected easily using camera-based track
- Speed: can be detected by changing fps and measuring accuracy
- Resources Management: in utilization reports
7. Sustainability results, resource savings achieved
Gesture Net Model
Resource Utilization
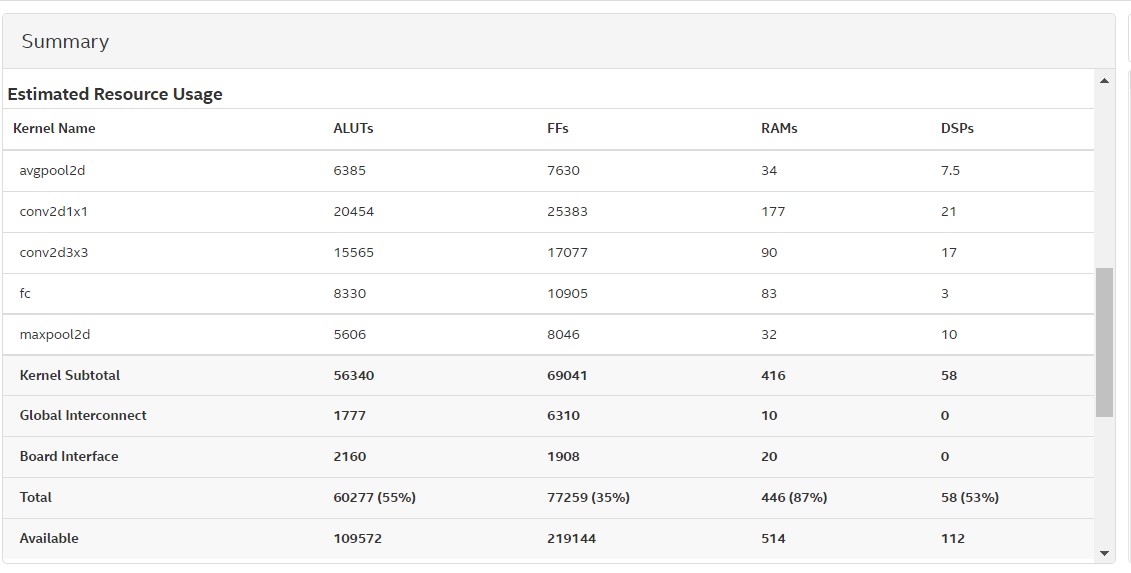
Speed
The speed for cam model is around 2.1s and speed of acc, fusion model is around 0.1 sec and this time was calculated in cpp where we start the timer before we give the arguments to the kernel and after command "clfinish(queue)" we stop the timer and then calculate the difference
8. Conclusion
we can conclude the capability of building gesture recognition real time system inside autonomous cars using de10nano and adxl362 accelerometer which can be used safely by user.
0 Comments
Please login to post a comment.