
本研究提出透過軟硬體協同設計(hardware software co-design)將卷積神經網路(Convolutional Neural Network, CNN)加速器實現於FPGA (Field Programmable Gate Array, FPGA)中的方法。本研究主要分成三個部分來實現:在硬體方面,(1)透過Avalon 匯流排將卷積神經網路模型中的遮罩、權重參數與影像載入至處理單元模組中,進行CNN中卷積與池化的運算,(2)處理單元模組的設計透過平行處理架構提升模組的運算效能,並且透過遮罩與權重的重複使用和定點數運算,有效節省記憶體空間的使用。而在軟體方面,(3)透過NIOS實現CNN中的全連結層,並將此模組與相關硬體模組進行整合,進而實現完整的CNN加速器。從實驗結果可以得知,本文提出的設計架構可以有效提升模型運算效能,並且能夠節省記憶體空間使用量。
Project Proposal
1. High-level project introduction and performance expectation
近年來,類神經網路的相關應用越來越為廣泛,不論是在影像處理、各類型的語音互動系統以及推薦系統(recommender systems)逐漸在我們的日常生活中變得普及與廣泛。然而,類神經網路的模型需要計算極其龐大的數據,故在硬體部分往往需要高容量的記憶體以及強大的運算能力。現在用來運算類神經網路模型之平台主要可分為三種:(1)圖形處理單元(Graphic Processing Unit, GPU)、(2)特殊應用積體電路(Application Specific Integrated Circuit, ASIC)、(3)現場可程式化邏輯閘陣列(Field Programmable Gate Array, FPGA)。圖形處理單元基於高容量的記憶體以及平行式的影像處理方式,進而達到高速運算的目標,但平台往往需要高成本以及高功耗,導致模型的應用場域會被限縮。再來,特殊應用積體電路,雖具有高效能與低功耗等兩項特性,但其應用場域相當受限,因為此平台通常只針對某種演算法、架構去進行設計,其平台之彈性與靈活性相當低。而在FPGA平台中不僅具有低功耗的特性,更能夠使用平行式架構、高頻時脈處理來提升模型運算效能,使平台能夠提供和圖形處理單元、特殊應用積體電路相等或更高的運算能力。
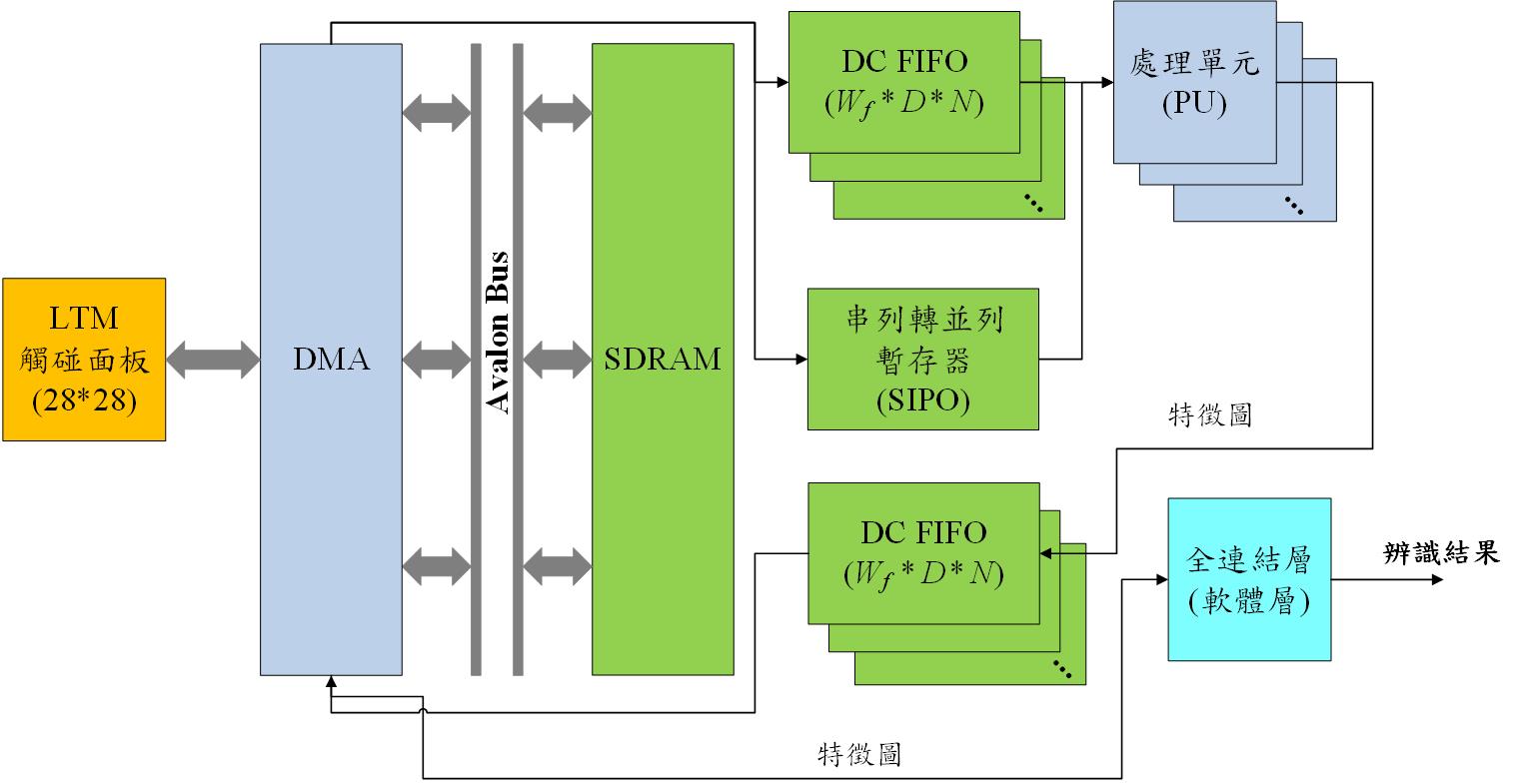
2. Block Diagram
3. Expected sustainability results, projected resource savings
本提案設計以硬體電路的方式實現卷積神經網路中的卷積與池化之運算,並且透過NIOS實現全連結層。在效能的驗證,透過自行設計的卷積神經網路模型來驗證此硬體電路之效能。提案設計之硬體電路也充分運用FPGA中的幾項特性,透過參數化的模組設計使硬體電路模組更具有調整性與彈性,使其能適用於不同任務導向的運算工作。另外,也透過平行處理架構、權重共享等相關設計方法,有效提升硬體電路的運算效能和降低記憶體的使用量,使其硬體電路能夠應用於各類型邊緣平台中。
4. Design Introduction
本研究之硬體加速電路之系統架構主要可分為三個部份,分別是影像輸入與資料緩衝區介紹、處理單元架構以及直接記憶體存取模組(Direct Memory Access, DMA)。將卷積神經網路模型於電腦訓練完畢後,取出模型權重檔中的遮罩、權重參數透過直接記憶體存取模組傳送至串列轉並列暫存器(Serial In Parallel Out, SIPO)中,使處理單元能夠取讀運算時所需的遮罩參數與偏差值。而在影像輸入與資料緩衝區的部份,本研究透過DMA控制器將輸入在LTM觸碰面板上的影像資訊存入至SDRAM中,並且透過雙時脈先進先出模組(Dual Clock First In First Out, DC FIFO)存放這些影像資訊。而在處理單元的部分,基於平行式的輸入架構將儲存於SIPO和DC FIFO中的參數與影像資訊載入至模組中進行卷積與池化運算,得到最顯著特徵圖,並將此些特徵圖儲存於DC FIFO中,最終再透過DMA控制器將最顯著特徵圖寫入至SDRAM中,進而提供全連結層進行運算。而在全連結層的設計中,是以軟體的方式進行實現,透過NIOS實現全連結層之運算,並將此部分整合進入整體的系統中。
5. Functional description and implementation
[影像輸入與資料緩衝區介紹]
使用硬體平台來實現影像處理、物件分類與辨識的模型開發時,如何節省記憶體空間和降低記憶體資料的取讀次數是相當重要的課題。首先,一般的FPGA平台記憶體空間資源往往是非常有限的,故如何節省記憶體空間是個重要的議題。許多的論文會使用線型緩衝器(line buffer)來儲存影像掃描線的資料,但當你輸入的影像越大張時,則會導致你的線型緩衝器所占用的記憶體空間越大,這與本研究的目標完全背道而馳。故本研究採用雙時脈先進先出模組(Dual Clock First In First Out, DC FIFO)來儲存影像掃描線資料,利用其可客製化一次儲存之影像資料寬度與其適用於實時影像處理之特性,有效控制記憶體空間的占用比。
[處理單元架構]
而在處理單元架構中,主要可分為三個部分,分別是負責卷積運算處理的(1)定點數乘法器與(2)階層式加法器,以及負責池化運算的(3)比較器模組,以下是各別的分析與介紹:
本研究所使用的神經網路模型的資料型態為IEEE 754-2008中的binary16,亦也可以稱為半精度浮點數。此資料型態是一種較新的浮點數類型,其優點是此資料型態不需要消耗過多內存,其精準度也不亞於單精度或是雙精度浮點數。另外,為了有效節省運算邏輯電路面積,本研究使用定點數乘法器取代浮點數乘法器。利用定點數乘法模擬浮點乘法器之效果,雖然會損失部分的精準度,但對於縮減運算邏輯面積,以及節省運算時間有相當大的助益。
而在模組設計方面,本研究之定點數乘法器採用六輸入一輸出之架構,將單個pixel與單個遮罩參數進行相乘運算,並將三筆權重值進行加總,進而得到單行影像(3個pixel)的權重值。另外,為了有效的提升運算時的速度,故本研究的定點數乘法器模組,透過精準的時脈對齊控制,讓使用者可以精準的知道此時刻下的輸入與輸出值為何,不僅確保乘法器後之後的階層式加法器不會計算到錯誤的資料,亦也可以在高頻時脈的運算下,不會影響到硬體電路的準確率和執行效能。
在加法器的設計方面,於上段的定點數乘法器中,有提及到的時脈對齊控制,在階層式加法器中亦也採用此種設計方法,為了精準得知每個時刻下的輸入與輸出資料,和避免在高頻運算時累積過多的誤差。透過DMA控制器將儲存於SDRAM中的偏差值載入至暫存器中,並且於乘法器輸出有效權重時,將偏差值載入加法電路中。本研究採用兩輸入一輸出的架構,並且透過此平行式的資料輸入提升加法運算的速度。
[直接記憶體存取模組]
本研究透過Avalon Bus匯流排與狀態機架構來實現直接記憶體存取模組,透過不同狀態來實現讀取與寫入的控制。在讀取控制方面,透過發送讀取命令、判斷是否等待以及讀取資料三個狀態進行讀取訊號、地址訊號以及突發讀取資料數等相關訊號的傳遞和資料的接收。如透過此模組架構將使用者輸入在LTM觸碰面板上的影像傳送至SDRAM中,以便進行後續的卷積運算。另外透過讀取資料計數來計算還需要幾次的讀取才能將存放於DC FIFO中的影像資料與存放於SIPO暫存器中的卷積參數與權重全數讀取完畢。
6. Performance metrics, performance to expectation
[硬體資源與記憶體使用量]
因為希望將此研究應用於邊緣運算中,故希望盡量節省記憶體空間使用量,大約控制在10-20MB左右。而在硬體資源的設定上,希望本研究的邏輯單元能控制在1500~2000左右。
[運算效能目標]
在基準時脈(50MHz)的基底下,希望此研究能夠將吞吐量加速至2-3倍,進而有效的發揮此研究的宗旨,就是能有效加速類神經網路的相關運算,取代TPU或GPU成為主流的類神經網路運算平台。
7. Sustainability results, resource savings achieved
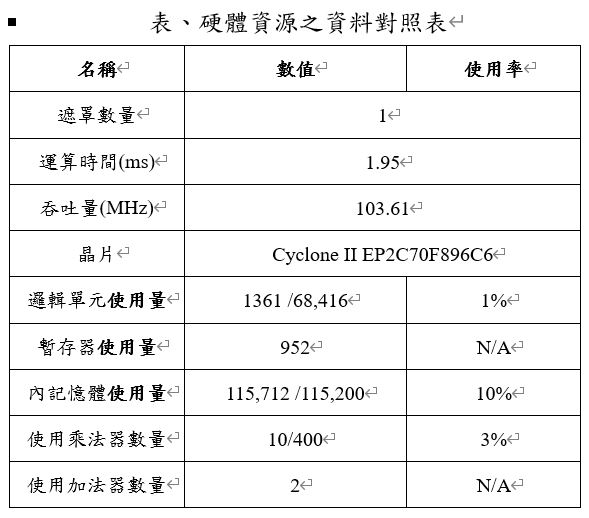
本研究中處理單元的硬體電路所使用到的資源分析,從表中可以得知本研究處理單元的硬體電路只使用到平台中兩成的邏輯單元資源,算是相當的輕量與理想。若是想將此硬體電路移植至更小型、輕量的FPGA平台中亦為可行的,若是以DE0-Nano為例,此平台可以提供22,230個邏輯單元,此硬體電路只需1361個邏輯單元的空間,故想要將此硬體電路應用於邊緣運算平台中,勢必是可以實現的。
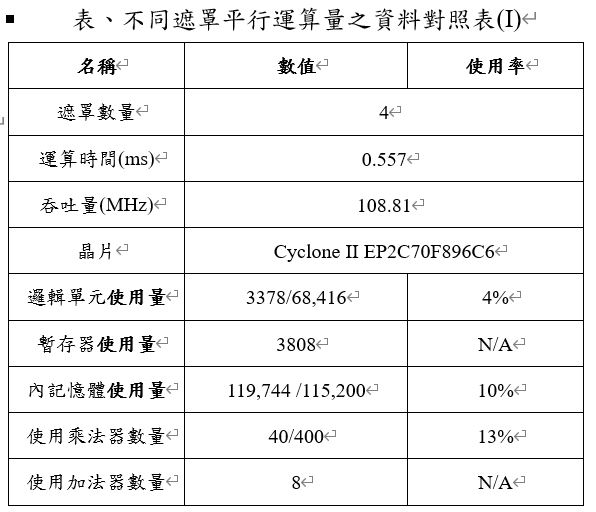
而本研究也基於FPGA平行運算的特點,針對同一個時刻下平行運算4張和8張遮罩,進而去測試能夠提升多少運算效能,以及需要多使用多少的硬體資源。下表是一次運算4張遮罩的相關資料對照表,運算時間和吞吐量相互比較,在提升遮罩的平行運算量,不僅能夠降低完成卷積運算的整體時耗,亦能夠提升整體硬體加速電路的運算效能。但因為平行運算的緣故,導致邏輯電路的面積增加,故需要使用到較多的硬體資源。
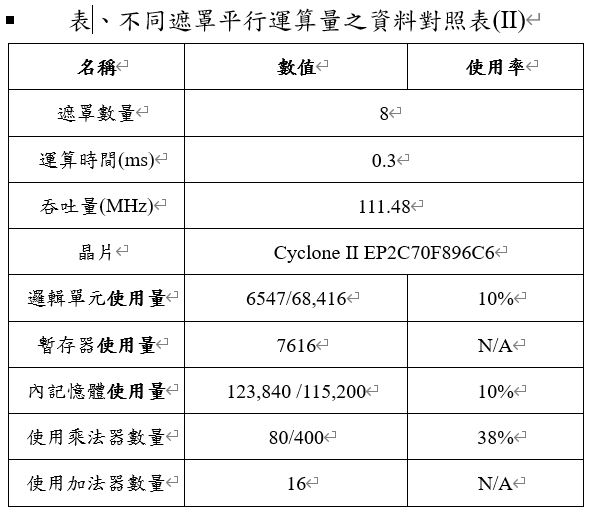
而下表是一次運算8張遮罩的相關資料對照表,與上表相互比較,在運算時間和吞吐量確實有明顯的優化,顯然增加遮罩的平行運算數量能有效的降低完成卷積運算的時間和提升硬體電路的吞吐量,使本研究之硬體加速電路有更卓越的運算效能。但在提升運算效能的同時,在邏輯單元和記憶體資源方面,也需要增加不少。故本研究針對以空間換取時間、以時間換取空間這兩項主要的設計方式進行分析與探討,讓使用者能夠自行決定要使用哪一種的設計方式。
8. Conclusion
本研究以硬體電路的方式實現卷積神經網路中的卷積與池化之運算,並且透過NIOS C語言實現全連結層。在效能的驗證,透過自行設計的卷積神經網路模型來驗證此硬體電路之效能。本研究之硬體電路也充分運用FPGA中的幾項特性,透過參數化的模組設計使硬體電路模組更具有調整性與彈性,使其能適用於不同任務導向的運算工作。另外,也透過平行處理架構、權重共享等相關設計方法,有效提升硬體電路的運算效能和降低記憶體的使用量,使其硬體電路能夠應用於各類型邊緣平台中。
而在未來的設計中,希望將全連結層硬體化,進而提升整體硬體加速電路的運算效能。另外,可以繼續提升參數化模組的占存比,使整體的硬體電路能夠適用於各種尺度的遮罩運算,亦或是能夠進行通道分離的卷積運算。
0 Comments
Please login to post a comment.