导盲小车控制系统设计是指通过导盲系统将周围环境中阻碍盲人出行的障碍物进行检测,通过语音提示盲人安全通过障碍物。导盲小车控制系统,运用超声波模块对周围环境进行实时检测,具有障碍物检测精准,检测效率高等特点,通过语音提示,帮助盲人安全外出。通过电子罗盘,告知盲人应当行进的方向。且结合了物联网+智慧城市的城市发展趋势,与了社会的发展相结合。同将红绿灯信息传给导盲小车,提示盲人安全的通过十字路口。
Project Proposal
1. High-level project introduction and performance expectation
设计目的:我国盲人数量的快速增长,使得导盲设备和基础导盲设施的普及成为必要,并且随着现代城市的建设,城市道路也在发生日新月异的变化,路况的复杂程度对导盲辅具有着更加严峻的考验。而常见的导盲辅助主要有导盲杖和导盲犬,导盲杖安全性和可探索性太低,导盲犬培训费用又及其昂贵,所以设计一套操作简单、实用可靠、价格低廉的智能导盲控制系统成为了当务之急。
应用范围、目标用户:视力有障碍的人群
为什么使用英特尔FPGA进行设计:
本系统的主要功能为:盲道避障行进和红绿灯信息识别。盲道避障行进功能采用在前、左、右和下分别放置一个超声波模块,通过多模块联合来进行障碍物的检测并避障;红绿信息灯识别功能通过北斗定位模块、电子罗盘和无线通信模块相结合实时获取当前红绿灯信息。所以本系统的特点是外部控制模块多同时要求实时采集外部环境信息。而英特尔FPGA全新的芯片布局以及ALM微架构的优化设计,正好可以满足本系统的要求。
。
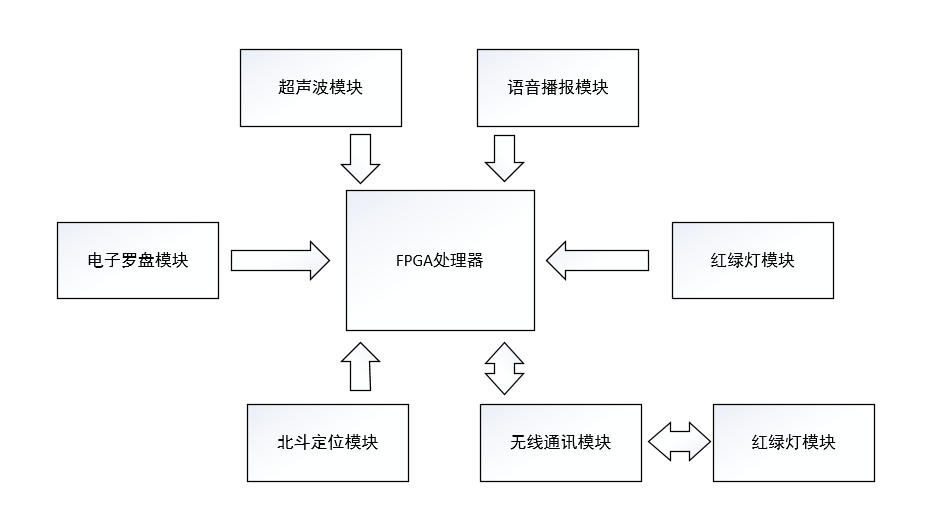
2. Block Diagram
3. Expected sustainability results, projected resource savings
采用超声波测距,对前、左、右,以及台阶进行检测,通过FPGA设置测试障碍物的距离,我们根据个人安全出行一般需要通过的左右距离为一米左右,因此我们设置的障碍物测试距离为30厘米,前后我们设置的是60厘米,台阶我们设置的是15厘米,因为我们的小车高为十厘米,所以15厘米就可以检测出台阶或一些小坑。也正因为我们所设计产品需要对数据处理迅速,所以英特尔FPGA完全满足我们对数据处理速度的要求。并且英特尔在芯片布局上做出了多个重要改变,简化了设计过程中的布局规划,消除了I/O单元对逻辑阵列带来的区隔,系统性能会得到提升,也会极大简化时序计算,并提升布局与放置的灵活性。在微架构方面,对其中的ALM进行了设计优化,以进一步降低其传输延时。除了ALM之外,Agilex还特别增加了片上内存MLAB的逻辑密度。与Stratix10相比,单位面积内Agilex有着双倍的MLAB密度,且50%的LAB可以配置成存储器模式。所以我们选择英特尔FPGA。
4. Design Introduction
设计目的:我国盲人数量的快速增长,使得导盲设备和基础导盲设施的普及成为必要,并且随着现代城市的建设,城市道路也在发生日新月异的变化,路况的复杂程度对导盲辅具有着更加严峻的考验。而常见的导盲辅助主要有导盲杖和导盲犬,导盲杖安全性和可探索性太低,导盲犬培训费用又及其昂贵,所以设计一套操作简单、实用可靠、价格低廉的智能导盲控制系统成为了当务之急。
应用范围、目标用户:视力有障碍的人群
为什么使用英特尔FPGA进行设计:
本系统的主要功能为:盲道避障行进和红绿灯信息识别。盲道避障行进功能采用在前、左、右和下分别放置一个超声波模块,通过多模块联合来进行障碍物的检测并避障;红绿信息灯识别功能通过北斗定位模块、电子罗盘和无线通信模块相结合实时获取当前红绿灯信息。所以本系统的特点是外部控制模块多同时要求实时采集外部环境信息。而英特尔FPGA全新的芯片布局以及ALM微架构的优化设计,正好可以满足本系统的要求。
5. Functional description and implementation
1.障碍物检测模块
障碍物检测模块采用多个超声波来进行检测,在前、左、右和下分别放置一个超声波模块,来进行障碍物的检测,超声波感应模块的工作原理是先通过控制超声波的发送模块,先向前方物体发送一定频率的超声波,在其有效距离之内,如果超声波遇到前方的物体则会被物体反射回来,由接收模块接收。在经过相关硬件电路与软件程序处理,来测定当前位置与前方障碍物距离。
2.位置信息模块
位置信息的获取由一个北斗定位模块和多用途电子罗盘组成。其作用是通过北斗定位模块和多用途电子罗盘从卫星和地球磁场获取位置数据和磁场方向数据并通过UART通信发送该控制模块进行数据处理。
3.语音播报模块
语音播报模块采用的是JQ8900芯片为核心的模块,该模块支持FAT文件系统、MP3、WAV硬件解码、7种播放模式控制,可以很好的控制扬声器告知盲人当前道路信息。
4.无线通信模块
无线通信模块选用HC-12无线串口通信模块,内置MCU,用户无需对模块另行编程。多种数据传输方式只需要模拟为发送和接收串口数据,使用方便。该模块采用多种串行数据传输方式,用户可以根据不同需求使用AT命令进行相应选择,支持一对多通信。
6. Performance metrics, performance to expectation
采用超声波测距,对前、左、右,以及台阶进行检测,通过FPGA设置测试障碍物的距离,我们根据个人安全出行一般需要通过的左右距离为一米左右,因此我们设置的障碍物测试距离为30厘米,前后我们设置的是60厘米,台阶我们设置的是15厘米,因为我们的小车高为十厘米,所以15厘米就可以检测出台阶或一些小坑。也正因为我们所设计产品需要对数据处理迅速,所以英特尔FPGA完全满足我们对数据处理速度的要求。并且英特尔在芯片布局上做出了多个重要改变,简化了设计过程中的布局规划,消除了I/O单元对逻辑阵列带来的区隔,系统性能会得到提升,也会极大简化时序计算,并提升布局与放置的灵活性。在微架构方面,对其中的ALM进行了设计优化,以进一步降低其传输延时。除了ALM之外,Agilex还特别增加了片上内存MLAB的逻辑密度。与Stratix10相比,单位面积内Agilex有着双倍的MLAB密度,且50%的LAB可以配置成存储器模式。所以我们选择英特尔FPGA。
7. Sustainability results, resource savings achieved
设计方案:
本设计中的数据及处理模块由英特尔FPGA构成,英特尔FPGA的主要功能是将串口接收来的各项数据进行分析处理,再将处理的结果显示到LCD屏幕上,同时发送相应的语音数据给语音播报模块。
位置信息传感器包括三轴电子罗盘和北斗定位模块,三电子罗盘通过UART通信对三轴电子罗盘来进行工作参数配置以及将获取到的数据发送给控制模块,北斗定位模块通过UART通信将从太空卫星中获取到的位置信息发送给控制模块;
超声波数据的采集由英特尔FPGA完成,FPGA将采集的超声波数据进行计算,将每个超声波检测到的距离进行组帧打包,通过UART协议发送给英特尔FPGA;
无线通信模块采用HC-12模块,该模块内置MCU,用户只需要通过UART协议进行配置。该模块的作用是将接收到的红绿灯信息通过UART协议发送给英特尔FPGA;
语音播报模块采用JQ8900模块,该模块内置存储芯片,只需提前将需要的播报的语音编号存储进去,通过UART协议接收英特尔FPGA发送来的启动信号及语音编号即可控制扬声器发出相应的语音。
硬件设计框图:
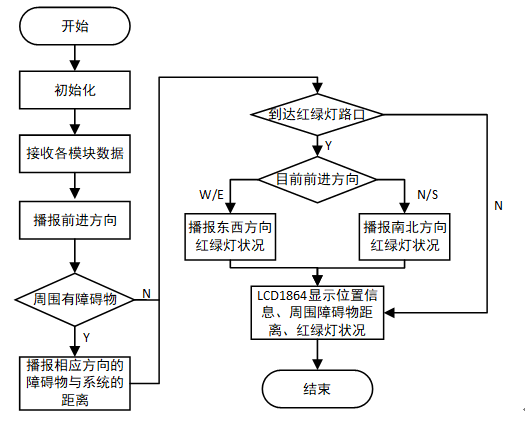
软件流程:
8. Conclusion
0 Comments
Please login to post a comment.