1、光谱数据采集模块:便携式数据采集终端的关键是糖尿病患者摄入食物的近红外光谱数据,由于不同的物质分子结构不同,导致它们选择性吸收不同频率的近红外光,所以物质的近红外光谱中就包含着物质的组成成分等信息。针对糖尿病患者需要知道所摄入食物的含糖量这种情况,需要综合考虑常用的嵌入式技术,同时满足后续近红外光谱数据相应处理算法的精度要求。
2、数据处理模块:由于糖尿病患者饮食监测系统的数据采集终端便携性的要求,所以数据处理模块的选择应结合应用场景的实际需求,既要注意工作效率也要符合经济可靠这一标准。
3、光谱数据处理算法:由于待测物质的近红外光谱与其有机化合物的组成和其分子结构信息存在着对应关系,同时这种对应关系可以通过函数来近似表征。如果使用机器学习中的一些算法来建立起对应的数理函数模型,就可以通过物质的近红外光谱来得到物质的有机化合物组成和分子结构信息。但是针对糖尿病患者需要知道所摄入食物的含糖量这种情况,需要从常用的多元线性回归(MLR)、支持向量机(SVM)、主成分分析(PCA)和偏最小二乘法(PLS)等算法中找出适合本系统的光谱数据处理算法。
Project Proposal
1. High-level project introduction and performance expectation
目标用户:
农业、检察、安全、医疗以及大专院校。还用于特殊部门的人事筛选、研究机构的果实研究等很多领域。
应用范围:
近年来,人们的生活水平日渐提高,尤其体现在饮食方面。但是部分人群并不能做到均衡膳食,他们过度的依赖个人口味和喜好,这导致这部分人群的营养过剩或营养失衡,从而引发各种慢性疾病。糖尿病是继慢性消耗性疾病、慢性血夜类疾病之后又一危害人类健康的慢性疾病。近年来,我国的糖尿病患病率直线上升,由于人口基数大,我国已经成为世界糖尿病第一大国。
项目实施的目的
在糖尿病众多治疗手段中,饮食治疗是预防和治疗糖尿病的重要手段,良好而健康的饮食习惯能够很好地控制糖尿病患者的病情。然而大多数患者自我控制意识不高也缺乏相应的营养知识,导致他们不能够有效地控制自己的饮食。若正常人群长期不注意饮食,那么其极有可能患上糖尿病或其他慢性疾病;所以就需要一款便携式糖尿病患者饮食监测设备。
为什么使用英特尔 FPGA 设备进行设计。
- 英特尔FPGA具有全新的芯片布局。
英特尔在芯片布局上做出了多个重要改变,简化了设计过程中的布局规划,消除了I/O单元对逻辑阵列带来的区隔,系统性能会得到提升,也会极大简化时序计算,并提升布局与放置的灵活性。
- ALM微架构的优化设计
在微架构方面,对其中的ALM进行了设计优化,以进一步降低其传输延时。
- 重新设计的布线架构
这样的简化设计使得它的整体布线架构更加简洁,也在很大程度上减少了交换节点MUX的输入,从而在保证布线灵活性的基础上,有效的降低容抗、并提升性能。
- 新一代HyperFlex寄存器结构
引入了HyperFlex架构。就是在FPGA的布线网络上,加入很多名为Hyper-Register的小型寄存器,这样可把原本较长的时序路径分割成多个较短的路径,从而提升时钟频率。
2. Block Diagram
3. Expected sustainability results, projected resource savings
对待测物质的组成成分含量有要求,由于近红外光吸收能力弱但渗透能力强,所以 待测物质组成成分含量必须大于 0.1%。在使用近红外光谱技术检测食品掺假方面结合 MLP 神经网络法、PLS-DA、fisher 线性判别分别 建立校正模型,其中 MLP 神经网络法的验证集的正判率达到 100%,证明采用近红外光谱分 析技术可以快速鉴别掺假羊奶。除了食品成分鉴别,食品成分含量的鉴别也可利用近红外光 谱分析技术实现。近红外光谱分析技术来测定大米中主要物质的含量,对光谱 进行预处理后选出特征波长,结合偏最小二乘法和 BP 神经网络法建立数理模型,经测验, 两类模型的相对标准差均小于 2.6%,决定系数均大于 0.9,模型精度良好。
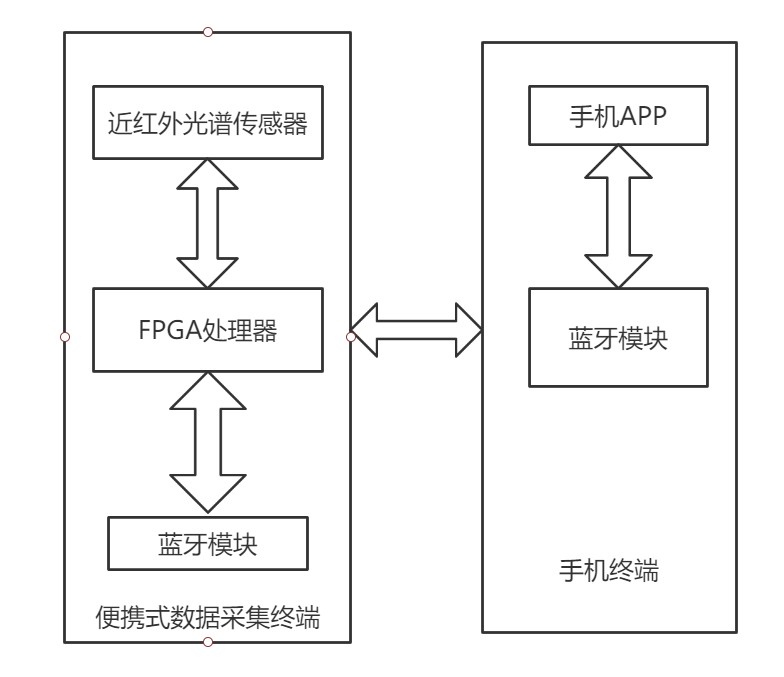
FPGA需要对近红外光谱传感器采集的数据进行处理,对处理后的数据通过蓝牙模块传输给手机APP。
2.ALM微架构的优化设计
在微架构方面,对其中的ALM进行了设计优化,以进一步降低其传输延时。
3.重新设计的布线架构
这样的简化设计使得它的整体布线架构更加简洁,也在很大程度上减少了交换节点MUX的输入,从而在保证布线灵活性的基础上,有效的降低容抗、并提升性能。
4.新一代HyperFlex寄存器结构
引入了HyperFlex架构。就是在FPGA的布线网络上,加入很多名为Hyper-Register的小型寄存器,这样可把原本较长的时序路径分割成多个较短的路径,从而提升时钟频率。
5.多样的时序优化方法
主要采用了三种时序优化方法:retiming、clock skewing和time borrowing
4. Design Introduction
项目实施的目的、意义。
近年来,人们的生活水平日渐提高,尤其体现在饮食方面。但是部分人群并不能做到均衡膳食,他们过度的依赖个人口味和喜好,这导致这部分人群的营养过剩或营养失衡,从而引发各种慢性疾病。糖尿病是继慢性消耗性疾病、慢性血夜类疾病之后又一危害人类健康的慢性疾病。近年来,我国的糖尿病患病率直线上升,由于人口基数大,我国已经成为世界糖尿病第一大国,患病人群也更加年轻化。
在糖尿病众多治疗手段中,饮食治疗是预防和治疗糖尿病的重要手段,良好而健康的饮食习惯能够很好地控制糖尿病患者的病情。然而大多数患者自我控制意识不高也缺乏相应的营养知识,导致他们不能够有效地控制自己的饮食。若正常人群长期不注意饮食,那么其极有可能患上糖尿病或其他慢性疾病;若糖尿病患者仍然不注意饮食,那么将会导致血糖难以控制、较早地出现并发症。采用饮食疗法在治疗糖尿病的科学性已被医学界公认,目前医学界已将其确定为糖尿病的基础疗法之一。然而养成良好的饮食习惯并坚持下去并不容易,部分人群由于个人口味喜好、个人惰性等因素无法长期的坚持良好的饮食习惯。
色谱分析法、光谱技术和生物检测分析法被广泛用于食品检测领域。采用光谱技术可对样品进行快速的无损检测且其对样品纯度要求低,可同时测量多种样品,因此光谱技术分析法逐渐成为食品检测领域的主流分析方法。在光谱检测方法中,近红外光谱分析技术的迅速发展使得各个领域都广泛的采用该技术来进行物质的分析检测,如农业领域、食品领域、药材领域等。在食品领域的应用中,近红外光谱分析技术主要用来对食物内的水分、酸度、甜度、成熟度进行分析。目前,国内外学者在食品检测领域上使用近红外光谱分析技术进行了大量研究,收获了较多成果;但是在上述研究中大多采用光谱分析仪这种实验室设备采集食品的近红外光谱,这些光谱分析仪不仅价格昂贵而且并不便携,日常生活中人们难以利用这些设备对光谱进行采集。
针对以上问题,本项目主要目标是设计一套针对糖尿病患者的饮食监测系统,本系统由便携式数据采集终端和手机两部分构成。便携式数据采集终端主要通过近红外光谱传感器检测食品光谱信号,在手机上对采集数据进行算法分析与存储。本项目所设计的便携式数据采集终端操作方便,结合手机APP便可随时随地的对食品进行近红外光谱的采集以及含糖量的分析,检测速度快且不用破坏食物。总体而言,该系统就是帮助糖尿病患者加强对健康饮食习惯的认识,利用便携式数据采集终端对饮食糖含量进行检测,成本低且普及性强。
英特尔 FPGA 具有诸多优点:
1.英特尔FPGA具有全新的芯片布局。
英特尔在芯片布局上做出了多个重要改变,简化了设计过程中的布局规划,消除了I/O单元对逻辑阵列带来的区隔,系统性能会得到提升,也会极大简化时序计算,并提升布局与放置的灵活性。
2.ALM微架构的优化设计
在微架构方面,对其中的ALM进行了设计优化,以进一步降低其传输延时。
3.重新设计的布线架构
这样的简化设计使得它的整体布线架构更加简洁,也在很大程度上减少了交换节点MUX的输入,从而在保证布线灵活性的基础上,有效的降低容抗、并提升性能。
4.新一代HyperFlex寄存器结构
引入了HyperFlex架构。就是在FPGA的布线网络上,加入很多名为Hyper-Register的小型寄存器,这样可把原本较长的时序路径分割成多个较短的路径,从而提升时钟频率。
5.多样的时序优化方法
主要采用了三种时序优化方法:retiming、clock skewing和time borrowing
6.灵活的DSP微架构
Agilex的DSP单元增加了对FP16、FP19、BFLOAT16的支持,同时也保留了对FP32、INT9等多种数据表达方式的支持,这极大提升了DSP的配置灵活性,使其更加适用于AI相关的应用。
5. Functional description and implementation
在日常生活中,为了方便糖尿病患者对所摄入食物的含糖量进行检测,通过饮食治疗法达到预防和治疗糖尿病的目的。本项目以FPGA技术为基础进行便携式糖尿病患者饮食监测系统的设计。系统主要由便携式数据采集终端和手机两部分组成,其中便携式数据采集终端包含近红外光谱传感器、数据处理模块和无线通讯模块。 系统主要功能为通过近红外光谱传感器检测食物光谱信号,通过数据处理模块后经无线通讯模块发送到手机,手机端根据相应算法计算得出食物含糖量并显示出来,从而实时帮助人们合理选择食物,并且手机端还可以录入糖尿病患者每日饮食内容、糖摄入量,此外还可以记录患者餐后的血糖,通过长时间的数据记录,可以发现食物与患者血糖之间的相关性,进而指导患者日后的饮食。该系统主要是帮助糖尿病患者加强对健康饮食习惯的认识,利用便携式数据采集终端对饮食糖量进行监测,成本低而且普及性强。本研究项目的顺利开展,依赖于以下几项关键问题的解决:
1、光谱数据采集模块:便携式数据采集终端的关键是糖尿病患者摄入食物的近红外光谱数据,由于不同的物质分子结构不同,导致它们选择性吸收不同频率的近红外光,所以物质的近红外光谱中就包含着物质的组成成分等信息。针对糖尿病患者需要知道所摄入食物的含糖量这种情况,需要综合考虑常用的嵌入式技术,同时满足后续近红外光谱数据相应处理算法的精度要求。
2、数据处理模块:由于糖尿病患者饮食监测系统的数据采集终端便携性的要求,所以数据处理模块的选择应结合应用场景的实际需求,既要注意工作效率也要符合经济可靠这一标准。
3、光谱数据处理算法:由于待测物质的近红外光谱与其有机化合物的组成和其分子结构信息存在着对应关系,同时这种对应关系可以通过函数来近似表征。如果使用机器学习中的一些算法来建立起对应的数理函数模型,就可以通过物质的近红外光谱来得到物质的有机化合物组成和分子结构信息。但是针对糖尿病患者需要知道所摄入食物的含糖量这种情况,需要从常用的多元线性回归(MLR)、支持向量机(SVM)、主成分分析(PCA)和偏最小二乘法(PLS)等算法中找出适合本系统的光谱数据处理算法。
本研究项目核心在于便携式数据采集终端方案的选择、光谱数据采集模块设计、无线通信模块设计以及光谱数据处理算法的选择等关键技术环节,为此,提出如下技术方案;整个研究过程的技术路线如下:
1、根据当前近红外光谱分析技术在食品检测领域的研究成果和相关资料,针对嵌入式技术初步确定系统实现方案;
2、确定糖尿病患者饮食监测系统所实现的具体功能,系统完成食物的近红外光谱数据采集、数据传输以及相应算法对采集数据的处理功能,并且研究实现饮食监测系统功能需求的相关技术;
3、确定饮食监测系统的硬件结构,其包含近红外光谱传感器、数据处理模块和无线通讯模块,同时确定各模块与嵌入式处理器之间的接口电路;
4、在硬件系统实现的基础上,通过对实际情况分析和各种采集数据处理算法的比较,确定糖尿病患者饮食监测系统功能的算法。
6. Performance metrics, performance to expectation
对待测物质的组成成分含量有要求,由于近红外光吸收能力弱但渗透能力强,所以 待测物质组成成分含量必须大于 0.1%。在使用近红外光谱技术检测食品掺假方面结合 MLP 神经网络法、PLS-DA、fisher 线性判别分别 建立校正模型,其中 MLP 神经网络法的验证集的正判率达到 100%,证明采用近红外光谱分 析技术可以快速鉴别掺假羊奶。除了食品成分鉴别,食品成分含量的鉴别也可利用近红外光 谱分析技术实现。近红外光谱分析技术来测定大米中主要物质的含量,对光谱 进行预处理后选出特征波长,结合偏最小二乘法和 BP 神经网络法建立数理模型,经测验, 两类模型的相对标准差均小于 2.6%,决定系数均大于 0.9,模型精度良好。
1.英特尔FPGA具有全新的芯片布局。
英特尔在芯片布局上做出了多个重要改变,简化了设计过程中的布局规划,消除了I/O单元对逻辑阵列带来的区隔,系统性能会得到提升,也会极大简化时序计算,并提升布局与放置的灵活性。
2.ALM微架构的优化设计
在微架构方面,对其中的ALM进行了设计优化,以进一步降低其传输延时。
3.重新设计的布线架构
这样的简化设计使得它的整体布线架构更加简洁,也在很大程度上减少了交换节点MUX的输入,从而在保证布线灵活性的基础上,有效的降低容抗、并提升性能。
4.新一代HyperFlex寄存器结构
引入了HyperFlex架构。就是在FPGA的布线网络上,加入很多名为Hyper-Register的小型寄存器,这样可把原本较长的时序路径分割成多个较短的路径,从而提升时钟频率。
5.多样的时序优化方法
主要采用了三种时序优化方法:retiming、clock skewing和time borrowing
7. Sustainability results, resource savings achieved
在日常生活中,为了方便糖尿病患者对所摄入食物的含糖量进行检测,通过饮食治疗法达到预防和治疗糖尿病的目的。本项目以FPGA技术为基础进行便携式糖尿病患者饮食监测系统的设计(其系统结构图如图1所示)。系统主要由便携式数据采集终端和手机两部分组成,其中便携式数据采集终端包含近红外光谱传感器、数据处理模块和无线通讯模块。 系统主要功能为通过近红外光谱传感器检测食物光谱信号,通过数据处理模块后经无线通讯模块发送到手机,手机端根据相应算法计算得出食物含糖量并显示出来,从而实时帮助人们合理选择食物,并且手机端还可以录入糖尿病患者每日饮食内容、糖摄入量,此外还可以记录患者餐后的血糖,通过长时间的数据记录,可以发现食物与患者血糖之间的相关性,进而指导患者日后的饮食。该系统主要是帮助糖尿病患者加强对健康饮食习惯的认识,利用便携式数据采集终端对饮食糖量进行监测,成本低而且普及性强。本研究项目的顺利开展,依赖于以下几项关键问题的解决:
1、光谱数据采集模块:便携式数据采集终端的关键是糖尿病患者摄入食物的近红外光谱数据,由于不同的物质分子结构不同,导致它们选择性吸收不同频率的近红外光,所以物质的近红外光谱中就包含着物质的组成成分等信息。针对糖尿病患者需要知道所摄入食物的含糖量这种情况,需要综合考虑常用的嵌入式技术,同时满足后续近红外光谱数据相应处理算法的精度要求。
2、数据处理模块:由于糖尿病患者饮食监测系统的数据采集终端便携性的要求,所以数据处理模块的选择应结合应用场景的实际需求,既要注意工作效率也要符合经济可靠这一标准。
3、光谱数据处理算法:由于待测物质的近红外光谱与其有机化合物的组成和其分子结构信息存在着对应关系,同时这种对应关系可以通过函数来近似表征。如果使用机器学习中的一些算法来建立起对应的数理函数模型,就可以通过物质的近红外光谱来得到物质的有机化合物组成和分子结构信息。但是针对糖尿病患者需要知道所摄入食物的含糖量这种情况,需要从常用的多元线性回归(MLR)、支持向量机(SVM)、主成分分析(PCA)和偏最小二乘法(PLS)等算法中找出适合本系统的光谱数据处理算法。
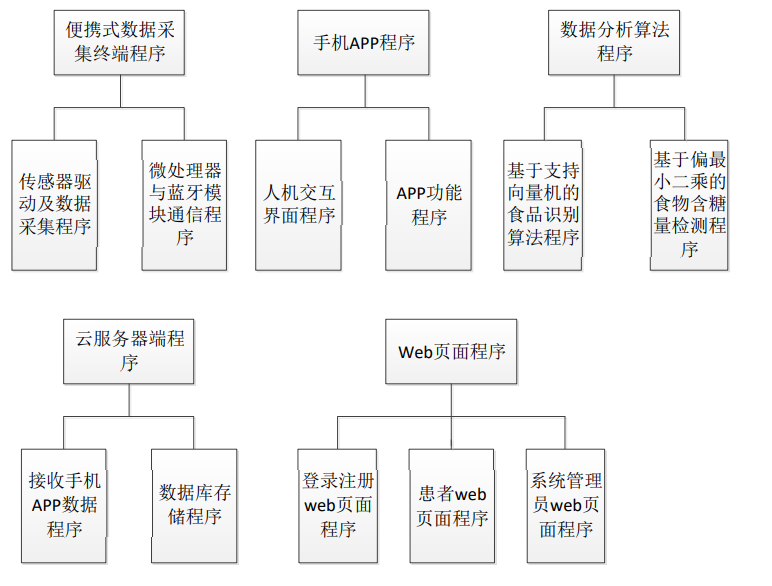
饮食监测系统的软件设计与实现,主要包含便携式数据采集终端、手机 APP 和云服务器三个部分的代码实现。便携式数据采集终端这一部分的代码主要是用来实现微处 理器与传感器模块通信、微处理器与蓝牙模块通信以及对光谱数据的初步处理。手机 APP 这 一部分的代码主要是用来配置传感器并接收采集到的光谱数据,然后在手机上用相应的算法 对光谱数据进行分析,最后将分析结果显示给用户并将用户输入的数据发送至云服务器上的 数据库中进行存储。云服务器端代码主要接收、存储用户通过手机 APP 上传的数据,然后通 过 web 页面展示给患者用户。本课题使用支持向量机作为食物识别算法,并对比了多元线性 回归和偏最小二乘,最终使用偏最小二乘作为系统食物含糖量检测算法,详细的算法对比及 实现将在第五章中进行描述。本系统便携式数据采集终端、手机 APP 以及云服务器的软件设 计与实现将在下面三节中进行详细介绍。 软件的总体方案图如下所示:
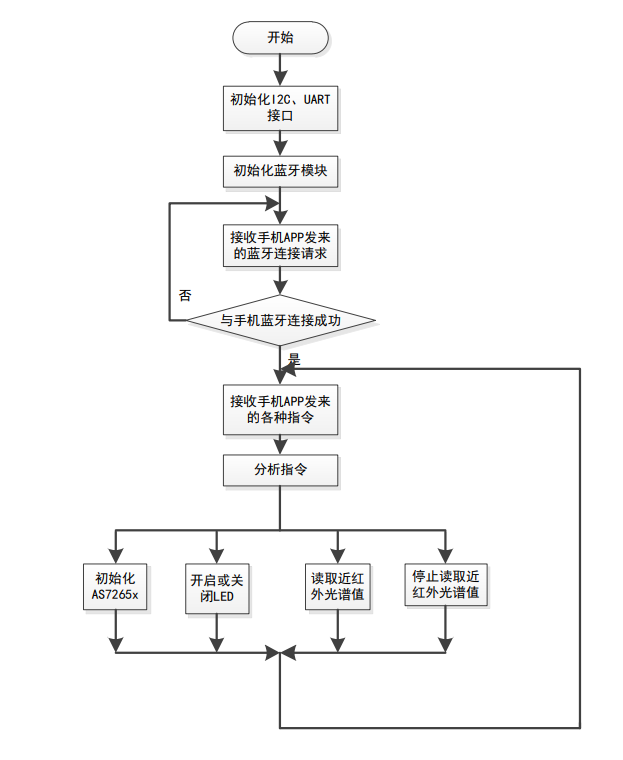
便携式数据采集终端工作流程图,由下图可以看出,便携式数据采集终端的工 作流程为首先初始化便携式数据采集终端上的蓝牙模块,然后接收由手机发送来的蓝牙连接 请求,若连接成功,则 APP 就能和便携式数据采集终端上的微处理器进行通信,建立好通信 连接后继续等待手机发送来的其他指令,并根据数据的内容进行处理,如:初始化传感器组 AS7265x、开启或关闭 LED、读取或停止读取光谱数据。完成某一条指令后便进入等待下一 条指令的循环中。
在近红外光谱传感器组 AS7265x 中只存在三个真实的寄存器:状态寄存器、写寄存器和 读寄存器,其余的寄存器都为由存储在闪存中的固件实现的虚拟寄存器。该传感器的虚拟寄 存器包括:LED 控制寄存器、原始光谱数据寄存器、温度寄存器等。对虚拟寄存器无法进行 直接操作,必须使用 I 2C 协议通过三个真实的寄存器来间接的读取虚拟寄存器中的值或向虚 拟寄存器中写入值。 该近红外光谱传感器中的写寄存器是一个 8 位的只写寄存器,若要对虚拟寄存器进行读 写,则首先需要将该虚拟寄存器的地址写入写寄存器,同理,要写入虚拟寄存器的数值也需 先写入写寄存器这一真实的寄存器。读寄存器是一个 8 位的只读寄存器,其中的数据供主机 获取。状态寄存器也是一个 8 位的只读寄存器。其中的 Bit0 为读状态位,当它为 1 时表示读 寄存器中的数据已经准备好可以被读取了,若它为 0 则表示此时还无法读取读寄存器中的数 据。Bit1 为写状态位,根据它的值来判断写寄存器的状态,其值为 1 时则代表此时写寄存器 正在被占用无法将数值写入,其值为 0 则代表此时可以将数据写入到写寄存器中。读写 AS7265x 虚拟寄存器的流程图如下图所示:
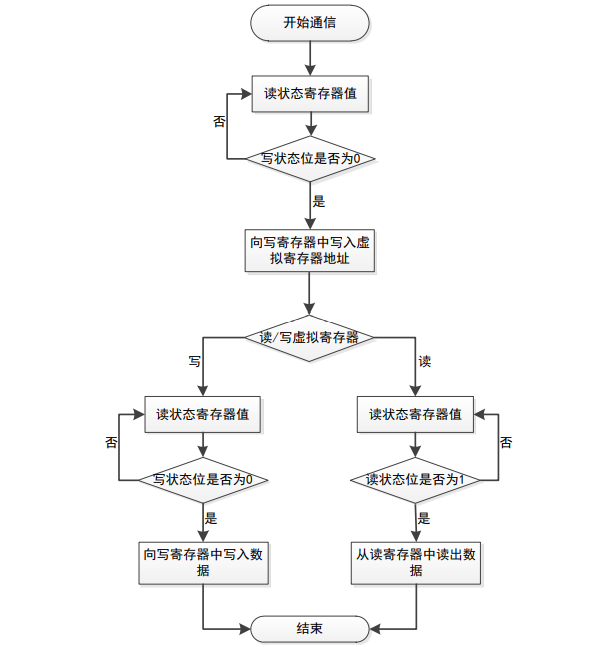
由上述流程图可知,首先需要判断状态寄存器中 Bit1 的值,通过 I 2C 协议的随机读访问 函数读出它的值,若其值为 0 则表示可以向写寄存器中写入数据,此时通过 I 2C 协议的随机 写访问函数写入需要进行读或写操作的虚拟寄存器的地址,当 Bit1 的值不为 0 时需要轮询状 态寄存器中的值直至 Bit1 的值变为 0。若还需执行写操作则需要再次判断状态寄存器中 Bit1 的值,当 Bit1 的值为 0 时,就可以向写寄存器中写入对虚拟寄存器进行操作的值。若还需执 行读操作则需要判定 Bit0 的值,其值为 1 时,便可读取虚拟寄存器中的值。 根据上述流程设计便携式数据采集终端处的软件,以实现微处理器模块与光谱传感器模 块之间的数据通信。在微处理器中对采集到的光谱数值进行初步处理以便与手机 APP 进行通信。
8. Conclusion
0 Comments
Please login to post a comment.