
"Softbank expects ARM to deliver 1 trillion IoT chips in the next 20 years." (Reuters, 2017)
Since AI is considered as an emerging technology by many companies and research institutes in the world because of its performance and accuracy, the number of AI chips and relevant systems are increased exponentially as Softbank already expected in 2017. With this kind of technical evaluation, it is expected that AI systems will help people to make their life richer than in the past because of its versatile functions and better performance than human-being.
However, people are also faced with side effects of AI systems' exponential increment because recently many researchers found that AI inference and training sequences can generate numerous CO2s. For example, training a single AI model can generate 626,000 pounds of carbon dioxide from relevant operations. This amount is five times bigger than a car. (MIT Technology Review, 2019)
For that reason, TinyML with lower-power and high-performance features is emerging as a replacement of ultra-scale AI systems.
To contribute to maintaining sustainability for the next generation, we will focus on designing low-power and high-performance TinyML accelerator with minimal hardware resources and energy consumption. To realize this goal, we will use Intel FPGA-based IoT device kits, self-developed hardware architecture and optimized software stacks for covering AI full stacks and contributing to CO2 reduction with low-power features for global sustainability.
Project Proposal
1. High-level project introduction and performance expectation
The purpose of this study is to design a heterogeneous Neural Network accelerator with the microprocessor (Include novel AI specified instruction sets) and the NPU (Neural Processing Unit) for the ultra-low power CNN applications. Since AI is an emerging technology for CV (Computer Vision) and NLP (Natural Language Processing), Intel and many other companies are using CPU (Central Processing Unit), GPU (Graphic Processing Unit) and NPU (Neural Processing Unit) for accelerating relevant applications’ performance. However, since the scale of data is gradually increased, costs for designing and maintaining relevant devices and infrastructures are also exponentially increased.
For that reason, this project will focus on enhancing AI applications’ performance, saving the power consumption and reducing the cost of relevant infrastructures such as CPU and NPU, etc. To realize this goal, there will be three steps for designing CPU, NPU and relevant peripheral IPs. First, analyzing remarkable deep neural network to extract essential hardware and software features. Second, inventing novel hardware architectures and software algorithms for accelerating relevant AI applications’ performance. Finally, performing design, verification and implementation of AI full stacks that are fully optimized for novel deep neural network with ultra-low power features.
During this project, we will deliver two types of project results. First, initial delivery will be verilog HDL (Hardware) and C source code (Software). Finally, after RTL/C coding has been finished, it is expected to deliver prototyped IP with Intel FPGA board. If there is any chances, it will be possible to test functionality and performance of project results with Intel data center's real test beds.
After completion of this research project with Intel, there will be short/mid/long term-based benefits for Intel PSG. First, the short-term benefit will be securing verified full-stacks with AI specified features for the ultra low-power AI applications. Also, it is expected to submit various patents and publications during this project. Second, the mid-term benefit will be designing own custom processor for Intel FPGA platform with the reference architecture from this project. Finally, the long-term benefit will be reducing costs of core processors for the Intel's AI infrastructures such as data centers and IoT devices by replacing the entire CPU and AI relevant processors with cheaper custom processors from this project. In addition, it will be possible to enhance performance of Intel's AI application with optimized hardware architecture and software stacks.
In summary, with this project, we would like to design essential infrastructure for Intel's AI applications and data centers. We think that our professional experiences at a major semiconductor companies and research experiences at UVA would be helpful for this research project.
2. Block Diagram
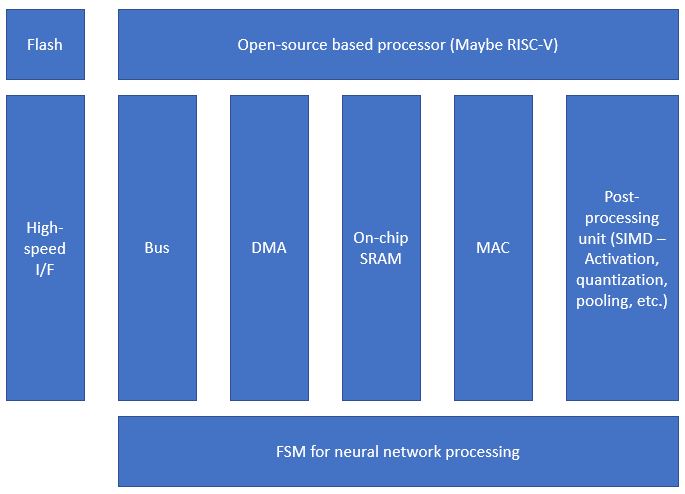
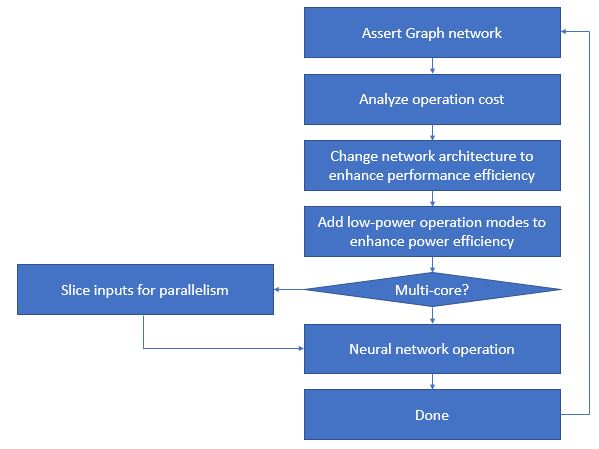
3. Expected sustainability results, projected resource savings
By designing the low-power and high-performance heterogeneous neural network accelerator, we would like to realize and contribute to the following categories:
1. Power efficiency : With low-power features such as DVFS, zero-skipping and novel low-power relevant algorithms, it is expected to contribute to saving energy consumption and CO2 generation at the same time. To realize this goal, we will try to enhance power efficiency with hardware/software co-design techniques for reducing useless usage of relevant resources and optimizing AI full stacks.
2. Performance efficiency : Recent AI systems are trying to increase their system size for getting better performance. However, because of this kind of approach, generated amounts of CO2 are exponentially increased and it is seriously affecting global sustainability. To solve this problem, we will try to find novel hardware architecture and software algorithms to reduce wasted resources to operate relevant AI systems. At the same time, it is expected to minimize required hardware and software resources by simplifying relevant systems’ architecture for reducing cost for mass production and contributing CO2 reduction of manufacturing processes.
3. Technical contribution : We will contribute to submitting patent applications (With sponsors' name), writing innovative publications (With acknowledgement) for spreading sponsor companies' ideas about global sustainability and discussing with many researchers in the world to enhance our project. With these activities, it is expected to enhance our project results and global sustainability at the same time.
4. Design Introduction
- Purpose of design : Ultra-low power CNN applications
- Application scope : Computer vision
- Targeted users : Various tech companies in the world
- Usage of Intel FPGA devices
: To design this project, I considered several factors.
First, Scalability: To find a golden trade-off point of performance for this project, it requires a scalable Neural Processing Unit. So I choose Intel's FPGA platform because it provides rich hardware resources for this kind of scaling work.
Second, Programmability: This is related to the first factor. For searching a golden trade-off point and maintaining relevant processors with latest features, it requires programmability for enabling re-programmable hardware architecture and relevant components. Since it is possible to do it with Intel's FPGA chip and S/W, I choose Intel's FPGA platform.
Finally, Comfortable UX: I already used Intel's FPGA platform, so I choose it for this project because of its easy and intuitive UX. I think this would be helpful to accelerate my project with Intel's FPGA platform.
5. Functional description and implementation
We have a plan to design microprocessors with AI specified instruction sets, Neural Processing Units and relevant peripherals for this project.
Main focus for this project will be a heterogenous neural network accelerator for CNN applications with ultra-low power applications. For making this goal, I will invent novel algorithms for zero-skipping scheme, DVFS, load re-balancing algorithms, etc. I will try to implement almost entire algorithm but some algorithms might be tested only with simulation environment that we will design.
Relevant blocks will be designed from scratch (By verilog HDL) and software need to be determined whether it will be designed from scratch or modified. However, if there is enough time, we will try to design our own neural network to enhance performance of this project.
6. Performance metrics, performance to expectation
Since I am doing an evaluation work for looking for proper performance that is well-matched to the Intel's FPGA platform, there is no fixed performance parameters yet.
7. Sustainability results, resource savings achieved
- Microprocessor with AI specified instruction sets : This processor will be used to decode commands from Host PC and perform partial operation for Neural Network processing. For this work, we will design AI specified noval ISAs for this project.
- NPU : This custom processor will be used to perform Neural Network processing including convolution, pooling and activation, etc. For this work, we will design this processor with various AI specified features to accelerate performance of CNN applications.
- FSM : This small controller will be used to decode high-level commands via bus interface. For a smooth process, we will implement dual FIFO to occur storing and performing commands at the same time.
- SRAM : This component will be used to design on-chip memory for storing temp results from relevant processors to reduce DRAM access and enhance re-usability of data.
- Bus : This component will be used to transmit data from memory to processor and vice versa. Currently we are considering the addition of compression and optimized data arbitration scheme for better performance.
- Peripheral IPs : Since we are still considering interfaces for getting data from high-speed interface IPs, it needs to be determined.
8. Conclusion
0 Comments
Please login to post a comment.