 Other: Ecological
Other: Ecological
Forest Environment Analysis to Detect and Predict Forest Fires
EM021 »
Recently, forest fires are on the agenda of a lot of countries. A significant portion of forests in tropical zones is facing a risk of burning down. To help to respond quickly to fires, a cloud-based IoT solution could be used. Current fires will be sensed with a camera and CO2 sensor which will use either NDIR or electrochemical technology. System alerts authorized personnel about risky and emergencies over Cloud. Additionally, notable environmental factors are oxygen, combustible gases, humidity, and temperature, so sensors for these factors will be used to collect environmental data to predict potential forest fires beforehand. This collected data will also be available in the Cloud. System alerts authorized personnel about risky and emergencies over Cloud.
Cover image by skeeze on Pixabay
 Smart City
Smart City
AUTONOMOUS RAG PICKING BOT FOR GARBAGE MANAGEMENT IN SMART CITIES.
AP080 »
Plastic pollution has become one of the most pressing environmental issues, as rapidly increasing production of disposable plastic products overwhelms the world’s ability to deal with them. Plastic pollution is most visible in developing Asian and African nations, where garbage collection systems are often inefficient or nonexistent. But the developed world, especially in countries with low recycling rates, also has trouble properly collecting discarded plastics. Plastic trash has become so ubiquitous it has prompted efforts to write a global treaty negotiated by the United Nations.
Did you know that every plastic that is being produced in the world still exists today? Half of all plastics ever manufactured have been made in the last 15 years.Millions of animals are killed by plastics every year, from birds to fish to other marine organisms. Nearly 700 species, including endangered ones, are known to have been affected by plastics. Nearly every species of seabird eats plastics.There is no natural process to degrade plastic but we can recycle them.so, we wanted to design our bot to collect and dump them into the trash.
 Marine Related
Marine Related
Mucilage Pre-detection System
EM023 »
Mucilage pre-detection system determines the possible locations where mucilage can appear using sensors to detect the amounts of nitrogen and phosphate in the water, a thermostat to determine water temperature and transmit this information to the authorities.
 Health
Health
DIGITAL EYE FOR AID OF BLIND PEOPLE
AP085 »
Every citizen has their basic rights to live a healthy and independent life likewise the blind and partially sighted people should lead their lives independently.
Through our project we aim to help the blind and visually impaired people which makes them independent to a certain extent. The aim is to use the FPGA and Microsoft cloud to build a prototype of the device. The idea is to guide the individual by giving the necessary instructions to reach their location and also by using image processing techniques, the device will be able to convert the text to speech which makes him/her independent to the most extent. Earlier there are projects which are aimed at obstacle avoidance using Ultrasonic sensors whose range is not good enough to roam on the roads. There are also projects which need implantation of electronic chips in the visual cortex to make the blind people see but the implantation is expensive which needs highly skilled surgeons. Our Prototype plan includes the glasses , blue tooth pen-cam and headphones.
So we want to design a cost effective and portable device which performs the 3 tasks:
1.OBSTACLE AVOIDING
2. READING THE TEXT THE DEVICE HAS CAPTURED WITH PERMISSION OF THE USER.
3. NAVIGATION SYSTEM AND SAVE DATA ABOUT THE FREQUENTLY VISITED LOCATIONS AND GUIDE THEM IN FUTURE.{ i.e the device has to be trained to save the frequently visited locations such as workplace, hospital etc.,.}
 Water Related
Water Related
Water Quality Analyzer
AP086 »
Water is a vital factor in human life and for the existence of other habitats. Easy access to safe water for drinking, domestic use, food and production is a civic health requirement. Therefore, maintaining a water quality balance is very essential for us. Otherwise, it causes serious health problems to humans. Water contamination has been studied as one of the leading causes of death and illness in the world. Many people die from contaminated water every year. One reason is that public and government ignorance and the absence of water quality checking systems cause severe medical issues.Water contamination is also a serious issue in industries, irrigation and aquaculture.
Traditionally, water quality detection is done manually when water samples are taken and sent to the laboratory, but this process requires a lot of time, cost, and human resources. These techniques do not provide real-time data. By considering these challenges, we have come up with an idea to design a Water quality analyzer to check the quality of the water used for different purposes.
The Process starts from taking the real time data from the water bodies using sensors and type of water need to be checked must be selected from the mobile app. FPGA Board processes the collected data and compares it with the standard data in order to assess the water quality.The quality parameters of the water and the quality of the water will be sent to the mobile app using IoT Technology. If the quality of the water is below the desired levels, an alert will be sent to the user. In this way we can have continuous real time water monitoring.
 Autonomous Vehicles
Autonomous Vehicles
Autonomous Disinfection Robot
AP087 »
In recent years, international socioeconomic development and medical reforms have permitted the medical industry to move toward true "intelligence". The outstanding developments in medical technology have helped people overcome many challenges in life. Especially, during the global pandemic of COVID-19, besides the development of vaccines, the application of advanced technical technologies also helps people slow down the increase of the disease. The incorporation of greater artificial intelligence, internet of things in to develop robots that automatically disinfect the air and surfaces of hospital environments can help reduce the human resources spent on environmental cleaning and disinfection and minimize the risk of occupational exposure for staff. These robots also facilitate informatized management of environmental disinfection, reduce costs, and increase the efficiency of disinfection efforts.
In this study, we propose to deploy a type of autonomous disinfection robot with the ability to automate tasks such as: Automatic scene recognition and disinfection; Automatic movement and avoids obstacles; Collect patient's body temperature and blood oxygen to assist in building a chart to monitor the patient's health automatically.
The autonomous disinfection robot applies AI algorithms and robotic technology to the field of hospital disinfection. In essence, the model is a disinfection robot with a high level of independent self-sensing AI. The robot model uses intelligent scene recognition, independent sensing in the disinfection process, real-time disinfection process monitoring, intelligent planning, independent execution, and evaluation of the results. An intelligent disinfection robot can compensate for the shortcomings of existing disinfection methods, improve the quality of disinfection, and reduce the probability of infection.
 Food Related
Food Related
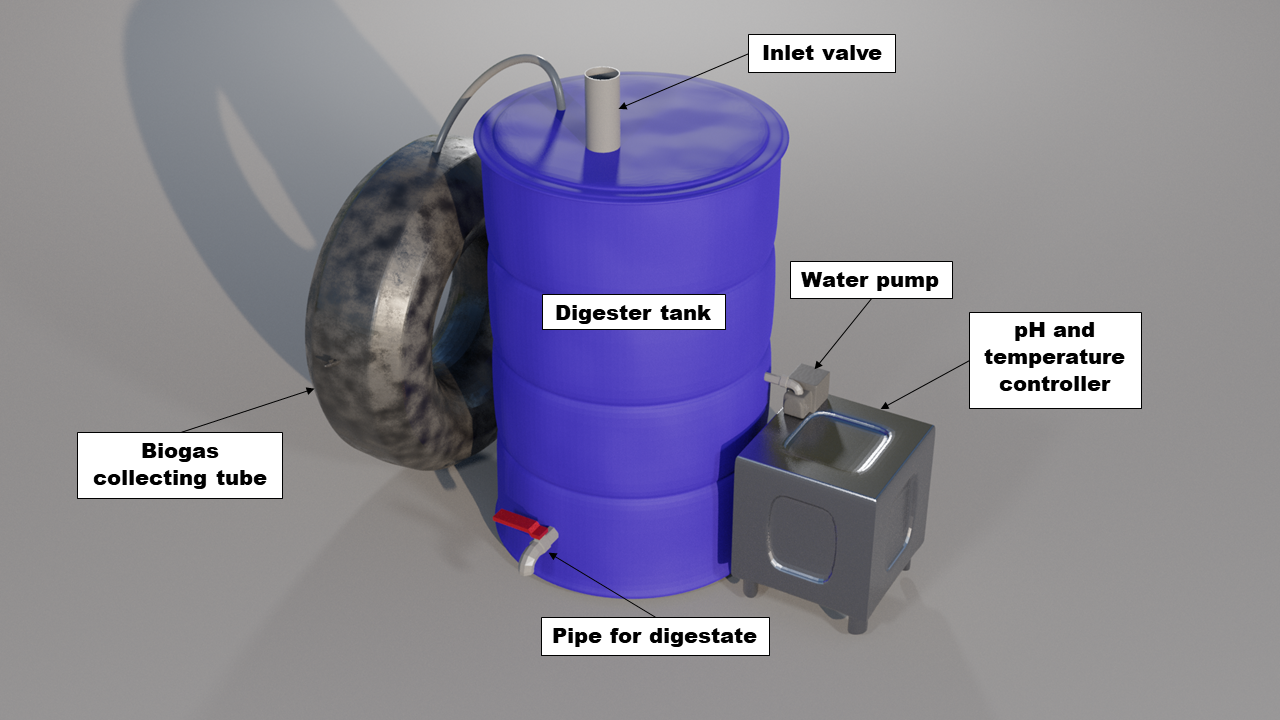
Mini Biogas Plant with AI Implementation for Parametric Optimization of Biogas Yield
AP089 »
According to the Food and Agriculture Organization (FAO) of the United Nations, one third of the food produced is wasted and the financial costs of food waste in the world could total to USD 1 trillion each year. According to United Nations Environment Programme (UNEP), approximately 1.3 billion tonnes of food is wasted annually. Besides, Asia produces 50% of global food waste with China, Japan and South Korea alone contributed to 28% of the global disposed food. According to the Future Directions International (FDI), South and Southeast Asia on the other hand contributed to 25% of global food waste. In Malaysia, the food waste produced is 2,921,577 tonnes per year from households alone. This is equivalent to 91 kg of food waste per capita per year generated in Malaysia. This is concerning since Malaysia is the highest country to produce the amount of food waste among Southeast Asia countries.
To address the problem of excessive food waste in Malaysia, biogas could be a solution. Biogas is a renewable energy source produced by the breakdown of organic matter such as food waste to produce mainly methane and carbon dioxide gases which are environmentally friendly. Another end product which is the digestate can also be used as fertilizers since it is rich in nutrients. Globally, coal and natural gases are mainly used to generate electricity – even cooking. With the used of biogas to occasionally replace these two resources is seemed to be more sustainable since biogas is renewable energy – more resources could be saved.
In line with the aim of this year's InnovateFPGA competition, which is "Enabling the Edge for a Sustainable Future", a mini biogas plant with AI monitoring features capable of producing methane gas from food waste through Anaerobic Digestion (AD) is proposed under the food waste category to help address the problem of excessive food waste particularly in Malaysia. This mini biogas plant will be smaller compared to the other biogas powerplant in industry which means it is also portable and just can be put in the backyard. All the food waste generated daily in the household could be ‘reused’ for two main purposes: heating (for cooking) and electricity. Several key parameters are affecting the AD process: pH, temperature, C/N ratio, Volatile Fatty Acids etc. The use of FPGA in this project is to provide an Artificial Intelligence (AI) implementation to the system to optimize the biogas yield from the food waste by controlling the pH and the temperature.
 Other: SGP - Biodiversity
Other: SGP - Biodiversity
MEDICINAL PLANT PLUCKER
AP094 »
Plants are considered as one of the greatest assets in the field of Indian science of medicine called Ayurveda.Some plants have it's medicinal values apart from serving as the source of food.The innovation in the allopathic medicines has degraded the significance of these therapeutic plants. People fail to have their medication at their doorstep instead went behind the fastest cure unaware of its side effects.
The main reasons are extinction of medicinal plants and lack of knowledge about identifying medicinal plants among the normal one's.Plant from the basis of Ayurveda and today's modern day medicines are great source of income.Due to cutting of forests,lot of medicinal plants have almost become extinct.Because of Ecosystem is the major part of Biodiversity,Where plants plays a crucial role. So we have to replant the extincting medicinal plants to improve our Ecosystem And to do not disturb Biodiversity.
So there is an immediate need for us to identify medicinal plants and replant them for next generations.Medicinal plants identification by manually means often leads to incorrect identification.
This project aims at implementing a System which can be able to identify some medicinal plants and Plucking of plants if they are medicinal.
 Water Related
Water Related
River Guardian
AS039 »
The high level of river pollution in industrial and metropolitan environments negatively impacts the ecosystem and raises the government's cost of maintenance and cleaning of those areas. A significant number of rivers, though, are never or rarely cleaned since there is not enough data about their pollution level, nor where the garbage foci are. Hence, a significant portion of all the river waste worldwide is never discovered. It remains unattended, increasing environmental degradation and furthering the impunity of bad actors that pollute rivers without having their actions put to judgment.
We propose a river waste monitoring system composed of an UAV equipped with an image capturing and processing device based on a FPGA. The proposed system also includes support stations with solar panels that will send the collected data to a cloud application while also sending data back to the UAV about its energy status.
The UAV will be capable of flying over the river waters and the riverbank in search of waste. It will also have a small compartment onboard, that will be used to collect water samples, which will then be sent back to a support station for testing.
The support stations will aid the UAVs by collecting solar energy to charge them and analyzing the water collected by the UAVs.
The cloud application will have a dashboard that will display the garbage accumulation spots on a map alongside pictures of the trash and historical data.
The FPGA is an essential part of the system because it will provide the computing power and precision needed for the obstacle and waste recognition algorithm to work in real-time while also being energy-efficient.
The project's expected outcome is to have a relatively low-cost, self-sustainable autonomous system that can be easily deployed on various rivers and efficiently map the river and riverbank area for garbage accumulation spots while also assessing the water quality. This system will provide the local government and agencies with real-time and detailed data about the river's health and waste accumulation spots. Furthermore, the data gathered will be valuable in policies and efforts to restore the river's condition and educate the local community about correct waste disposal practices and other ways of ensuring the nearby river's well-being.
 Health
Health
A Portable Device for Detection of Foot-and-Mouth Disease in Livestock
AP118 »
Design and Development of Machine-Learning Based Portable IoT-Device for Clinical Detection of Foot-and-mouth disease in Livestock
Often livestock in farms become affected by the Foot-and-Mouth Disease (FMD) due to poor maintenance. This is a highly infectious and sometimes fatal viral disease and poses serious issue to animal farming. The transmission of the FMD virus is possible before an animal has apparent signs of disease, and this aspect of low-detectability at early stages increases the risk of significant spread of the virus before an outbreak is detected. Further the FMD virus can be transmitted in many ways, including close-contact, animal-to-animal spread, and the carriers can be even inanimate objects, such as fodder and motor vehicles. The incubation period for FMD is 14 days. It is reported to be 1 to 12 days in sheep, with most infections appearing in 2 to 8 days; 2 to 14 days in cattle; and usually 2 days or more in pigs, with some experiments reporting clinical signs in as little as 18 to 24 hours [1]. This disease is still prevalent and the current approach to control the spread by large-scale culling results in adverse economic and environmental effects and is traumatic for farm workers and the public. The first major FMD outbreak in the U.K. in 2001 is estimated to have cost the country at least $6 billion, and another major outbreak happened in South Korea in 2010/11, with an estimated impact of about $8 billion. Though the livestock can be protected against FMD by vaccination, non-endemic countries do not vaccinate for FMD preemptively because of the cost of vaccination. However, they must be prepared to act at the first sign of infection. Hence, early detection of clinical signs of FMD is very critical.
We propose to design and develop a portable IoT device based on machine learning (ML) algorithm using FPGA platform that can be used in the preliminary investigation of clinical signs due to FMD. The typical clinical sign is the occurrence of blisters on the nose, tongue, or lips, inside the oral cavity, between the toes, above the hooves, on the teats and at pressure points on the skin. For training the ML model, currently available images of clinical signs of FMD and the corresponding diagnosis will be used for classification. After the model is trained, the portable device can be taken to the farm, and the images of the clinical signs of the suspected animal can be captured. Then the device will classify the diagnosis with a confidence score. Based on this, further investigations, if required, can be taken up.
[1] OIE Technical Disease Card: Foot and mouth disease, World Organization for Animal Health, Sep. 2021. [online]. Available: https://www.oie.int/app/uploads/2021/09/foot-and-mouth-disease-1.pdf
 Smart City
Smart City
Automated traffic control system
EM002 »
The aim of the project is to solve the problems of traffic jams on the city roads. In addition, this should solve the environmental situation in the city: excessive emissions of CO into the atmosphere.
 Other: Climate Change
Other: Climate Change
IOT Home-Alone Prayer Plant
EM003 »
According to the last UN report about Global Warming, we reached the “Code red for humanity”. Thus, we all should show serious steps toward solving such an enormous global issue starting from yesterday and not even from the current moment. The delay in solving this major global threat would cause many drastic circumstances that we might not be able to undo if we kept this “stand-still” manner of reducing CO2 emissions. The damaging effects of greenhouse gases are now clearer and tangible for every human nowadays.
Unfortunately, the main cause of such drastic consequences of global warming is due to the emerging of the technological era that we are both blessed and cursed by using it.
The usage of high-tech devices and their applications is extremely essential for every one of us nowadays. However, the number of emissions of carbon dioxide (CO2) and other greenhouse gases for producing these products is recording remarkable negative records to the point that oriented many scientists to think about how many years left for our existence on our lovely planet, The Earth.
Subsequently, the next generations will be in great danger as they will have to face many dramatic challenges that have been initiated by us, unfortunately.
Without a doubt, we believe that the rise of the technological era caused such a massive issue. However, we also have faith that the technology itself could play the “Hero role” to save our planet through positive and transparent initiatives.
Subsequently, we will shed the light on a special houseplant, the Prayer Plant, as it has a unique capability to remove the CO2 emission in an efficient manner in comparison with many similar indoor plants. Our initiative in this project is to convince everyone to plant such indoor plants at home, workplaces, etc.
The main goal of this project is to conserve the maximum lifetime of such plants without any human intervention. So, we will depend on INTEL’s DE10-Nano FPGA board to process many vital sensory readings and have all these records stored in the Microsoft Azure cloud for further processing.