AP085 » Embedded Neural Coprocessor
Embedded Neural Coprocessor is the next generation of embedded processor which have capability to execute machine learning functions efficiently. Our Coprocessor supports small scale convolution neural networks(CNN) computation natively using re-configurable layers which will be implemented in programmable logics of Cyclone V. First, user designs the neural network using provided API, then train it offshore (servers) and feed the model to our Coprocessor. Then it can execute feed forward computation and generate output which will be used in targeted application eg real-time object recognition, face recognition, voice command recognition etc. we have separate dedicated hardware logic to emulate each type of layers which are computational intensive operations like convolution/ Fire layer, Maxpool layer. For example, if a network have convolution layer operation, it have dedicated hardware which perform the convolution layer function. Layer parameters (dimension, inputs, etc) are configurable dynamically according to requirement. Similarly we have configurable Maxpool hardware module. We support most commonly used layer operations, But if user required different operation, which also supported by performing computation in ARM processor. Layers are connected through memory after each layer output stored in memory.
Our Coprocessor can achieve great speed compare to typical sequential embedded processor since we are using hardware level parallelization. It can be used in many real-time applications. It will be cost effective compare to GPU or other dedicated hardware level acceleration. We separate device used for training (in servers) and testing application (Coprocessor), because training is very time consuming process which need heavy computing power while testing can be done remotely. Ultimately we could able to run small scale neural network on embedded device with greater speed.
Introduction
Machine learning is the game changer in computer vision and other similar applications. Without any doubt, next generation embedded should support machine learning functionals efficiently. We propose an embedded processor architecture which supports small convolution neural network(CNN) natively using re-configurable layers which will be implemented in programmable logic of Cyclone V. Our Coprocessor can achieve great speed compare to typical sequential embedded processor since we are using hardware-level parallelization. It will be cost effective and power efficient compared to GPU or other dedicated hardware level acceleration.
Applications
This Coprocessor will give vast facilities for embedded engineers to facilitate machine learning algorithms for signal processing(audio, image, video and sensor data). Our Coprocessor can be used in any embedded system which requires small scale neural networks. It can be used as vision processor for cameras to perform high level operations like real Time Object recognition, facial recognition, intelligent remote monitoring, surveillance, activity monitoring, a robotic application which use cameras etc. It can be used in audio processing application like voice command recognition. Ultimately this will open several paths for new ideas which will use the power of neural network in embedded systems.
Advantages
The primary advantage of this architecture is speed, it will be faster compared to other embedded processor. GPUs are not feasible for small embedded application and this will be more power efficient as we can switch of the blocks which are not in use. Low power usage is a key requirement in the embedded application. In our approach, we load the network model and run it on Coprocessor so computationally intensive training process can be done in servers. This approach does not require cloud service which enforces the privacy and security and won't demand high network bandwidth.
Methodology
We are going to implement our Coprocessor on DE10-nano board. The primary reason for selecting this device is it has powerful ARM processor along with programmable logic and DDR3 memory. In our architecture, there should be a processor which will schedule the feedforward computations, then communicate with the external computer and also perform other regular tasks in the embedded system. ARM Cortex 9 in this board is the best match for this purpose. This board has 110K LEs which is well enough to implement each type of layers. During operation, each layer takes input and store the output in memory so DDR3 memory is the suitable option. Other than these DE10- nano board have numerous input and output interface, (eg from camera, audio source, video in or out. HDMI in out, network, GPIO, sd card, USB) which facilitate different application requirement.
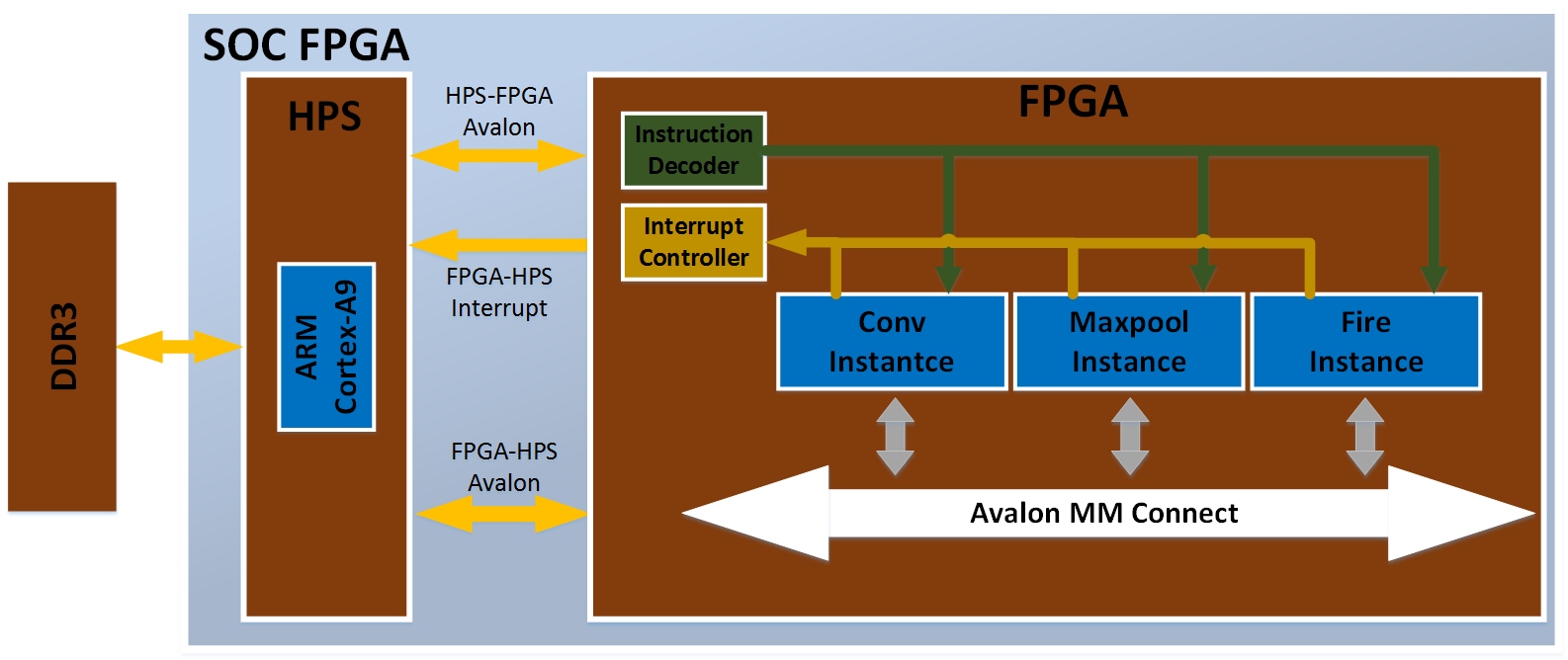
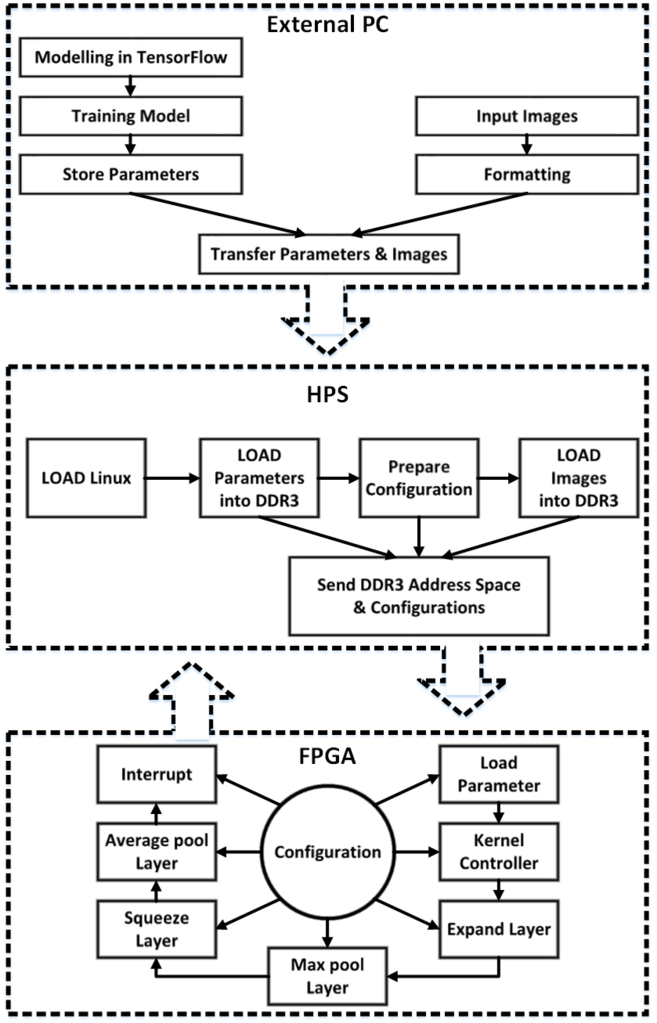
There are 3 communication bridges in between the FPGA and HPS.
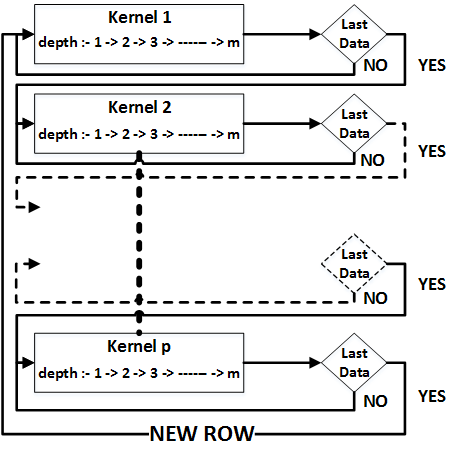
Each layers will get the address input and output data's location and configuration parameters from the instruction decoder. And each layers will send signal to the interrupt controller to inform to the processor that particular task has been completed.
There are four main functional in complete system
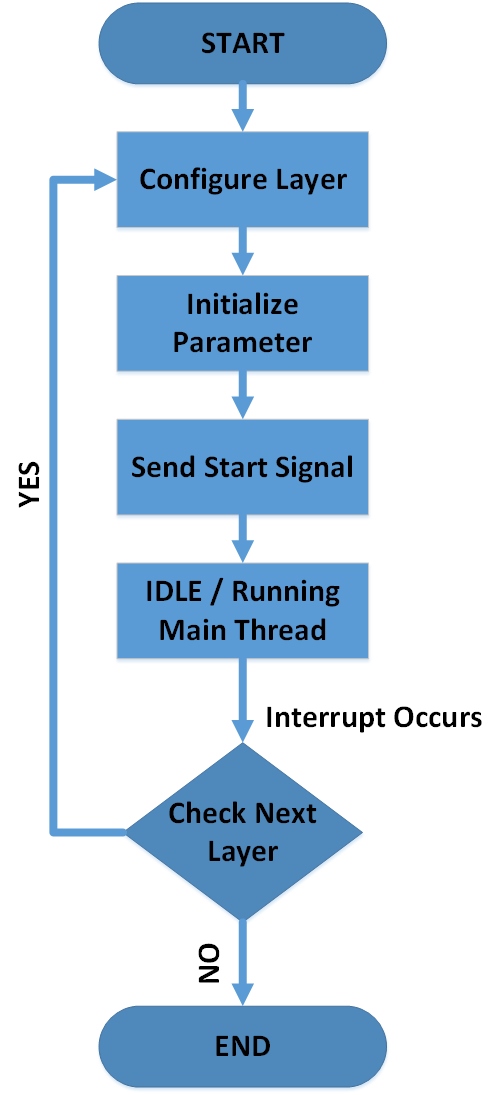 ARM processor programes
ARM processor programes
Feasibility of using DE10-nano Board
Board provide DDR3 bandwidth around 25Gbps, which can handle input and output memory access for each layers. Memory size is 1 GB well enough to store the input and output and intermediate data.
MAC(multiply and accumulate) operation is heavily used in computations. Cyclone V have 224 multiplier which can run at least 50 MHz. So it can handle 224*50 = 11 200 million MAC operation. But if we take a embedded ARM processor (two core, 800MHz, dispatch interval 2 for MAC instruction), which can achieve maximum 2*800*½ = 800 million MAC operation only. Note SqueezeNet requires 860 million MAC instruction in one run.
110 K LEs can be utilised for parallel comparators in Maxpool layer and RELU operations
112 Variable-precision DSP Block provides floating point operations. It has hard corded accumulator will be useful in convolutional layer.
5Mbit block rams can be used as a buffer. This allows to copy data from DDR3 in burst mode
Dual core ARM cortex 9 processor on board can be used as host processor which will schedule and control overall application.
Rich input and output interfaces. So we can use it for different application eg - video/images, audio, sensor data, etc.
Case study : SqueezeNet on our coprocessor
SqueezeNet is the compressed version (0.5MB) of AlexNet. It have 50 times fewer parameter while achieving same accuracy. So SqueezeNet will be the best candidate to test in our coprocessor
Reference
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size - Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, Kurt Keutzer
Convolutional neural networks(CNN) have become mainstream of research in computer vision, video analysis, and natural language processing. Accuracy in vision-related tasks like object recognition, object detection, segmentation has increased close to human-like performance with the cost of increased computations. But resources and power requirements for inference computation are very high which cannot be affordable in the embedded environment. Another option is cloud-based CNN inference, but it's also not suitable due to network delay and privacy issues. In most of the use cases in embedded systems, resources, power, and latency are the main decision factors compare to accuracy. But there are no any embedded processors or microcontrollers which natively support So we propose a configurable architecture which can run CNN inference in FPGA with the limited resource (8 bit float computations) and timing constraints. We have chosen SqueezeNet showcase our architecture, but this architecture can be configured to implement any SqueezeNet like architecture without any modification in design. With little modification in design, we can implement any small-scale CNN architecture. Here we summarise key features of our design, low resource usage, low power usage, portable, low cost, independent of the cloud-based system and data privacy.
Our design has very broader application scope from computer vision to natural language processing. Whatever the application requires SqueezeNet like models can use our architecture by giving appropriate configuration. For other types of CNN architectures, our design can be used with minimal modification. Our design primarily focused on computer vision related task, especially object recognition. Object recognition is a vital task in lots of fields, here are few of them. In self-driving cars or automobile system, our design can be used for pedestrian detection, lane detection, and traffic signal detection. In robots or drones, our design can be used to detect objects and avoid obstacles. It can be used in portable medical scanning devices to analyze medical images. It can be used with portable surveillance cameras to detect anomalies, so cameras will become more intelligent and no need to depend on the cloud, which ensures privacy. Face attributes detection, handwritten text detection, pose estimation, artistic style transfer are few more applications of our design related to computer vision. As mentioned earlier, other CNN related applications can be built with our system with additional effort.
Our design is more general purpose one, so it is not for end users, it can be used embedded engineers, hardware engineers, and electronic enthusiasts. Embedded application engineers can use our system as a vision processing unit to perform object detection, segmentation etc. They can directly run inference for Squeezenet like models. Hardware engineers can use our model and extend to support other CNN architectures according to their requirement. Eventually, our design will help offload the processor, so it can perform other tasks.
CNN inference needs huge computation resources and can be executed in parallel. Our design exploits inner layer parallelism and intralayer parallelism of CNN architecture. We use FPGA in Cyclone V to implement parallel computations with efficient pipelines. In our design, HPS initialize the architecture configurations, model parameters, and input data after that FPGA perform all computations and at the end, it will send interrupt to HPS, in the meantime HPS system can perform other tasks. This kind of CPU offloading is mandatory in an embedded system since CPU have to control overall system and cannot be loaded with a single inference task.
In our design, we use 8-bit custom float operation to reduce resource usage. Using FPGA we could able to implement this with very lower resources usage whereas in CPU or GPU it cannot be implemented efficiently.
Our design is scalable, the user can change the size of the model by configuring the number of layers, size of the input, location of pooling layers. FPGA provide reconfigurability to achieve this but other hardware level accelerator cannot have this capability. Our design is expandable, for large FPGA we can increase the number of blocks executed concurrently, in small FPGA we can perform the task with one instance of computation block. This modularity is another key advantage achieved using FPGA. As described earlier, with little modification, our design can support other CNN architectures. This rapid hardware level modification is only possible in FPGA system by simply reprogramming with necessary changes.
Our design has broader application scope, so there can be varieties of input and output requirements. FPGA helps to expand IO easily as required. For example, our design can be used for portable scanning machine, here scan sensor and LCD display can be directly attached to FPGA.
First, we have to choose model required for the dataset. The number of layers, number of kernels, input image size and pooling layers need to be decided. Then model the network in TensorFlow additionally use our methods to support custom 8-bit float number. If pre-trained weights available for that model, we can use that to speed up training. After training store the weights using our python script in particular format required by our design.
Transfer model parameters to Linux system running on HPS through the network port. Run the C executable, which will load the model weights into DDR and pass the address to the FPGA subsystem. Then HPS will send the model configuration parameters like input size, number of layers, number of kernels, etc. All communication happens through AXI interconnect between HPS and FPGA systems. Now model initialization is complete and now we can run inference
Another C executable loads the input image into DDR from SD card(we can use network or camera or any other image sources) in raw pixel format and send the address to FPGA and then become idle or perform other tasks. A state machine in FPGA controls overall inference computations. It configures the computation blocks and handles fetching of weights, biases and input values from memory required for that state. When computation block finishes, the intermediate output is written to DDR. On next state, this block will be configured with another parameter and intermediate data from the previous layer is feed as input. This iteration continues until the final layer of inference is reached. Upon finishing the last layer, the output is written to DDR and state machine will fire an interrupt to HPS and pass the address. HPS can read the result and display it.
In the layered archiecture the expand (3x3 & 1x1) layer has 4 parallel convolution blocks and squeeze layer has 16 (8 + 8) parallel convolutuion blocks. The performance of expand and squeeze is 1 : 2 ratio. The computation time of the layered archiecture for a single layer is described in following example cases.
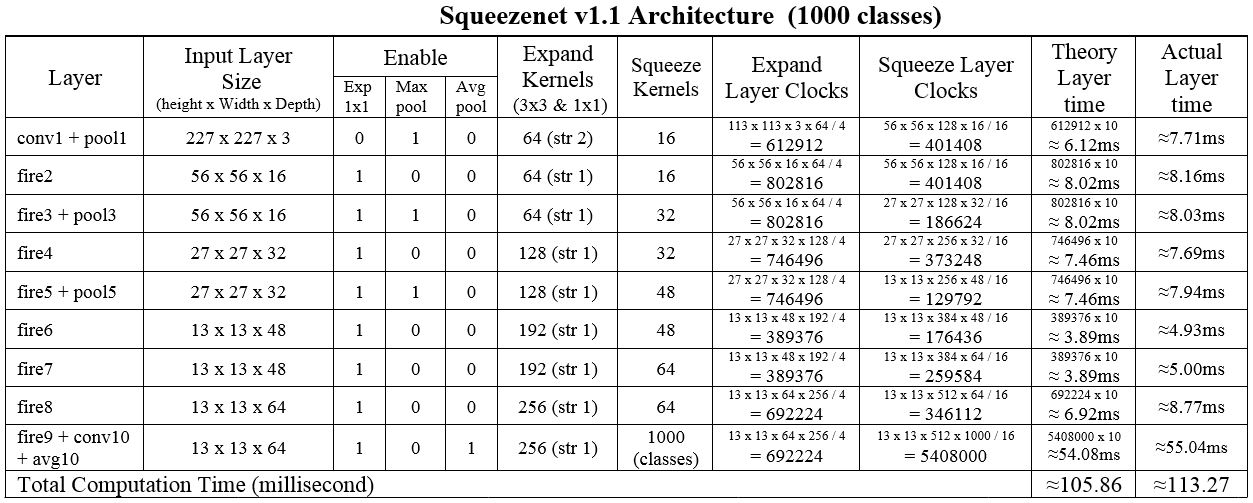
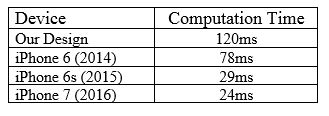
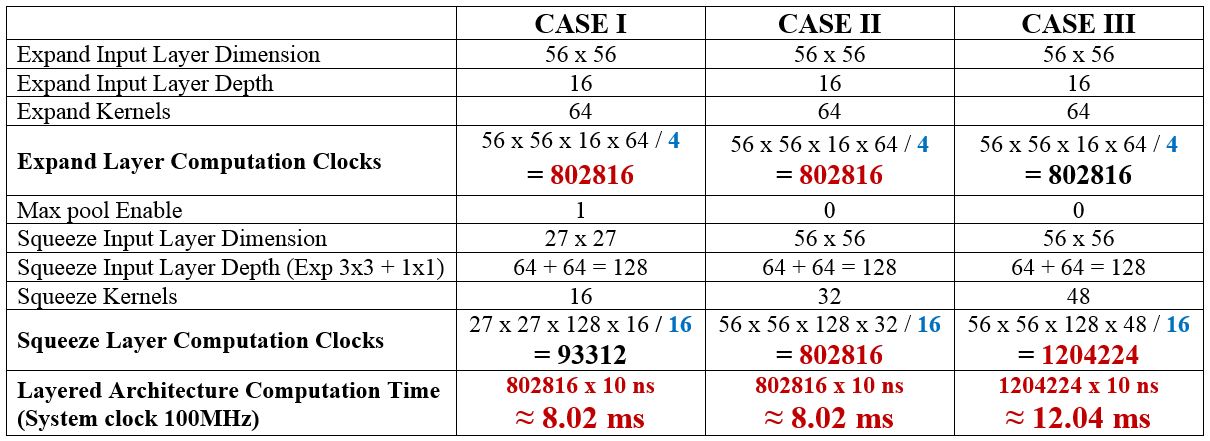 Based on the above table, the expand layer and squeeze layer consume high time in case I and case III respectively, and both layer consume equal time in case II. As inputs layer data and kernel's weight values are buffered internally, processing modules doesn't get idle by DDR3 latency. It was verified in board and we got almost same processing time. Time Taken for Squeezenet v1.1 (mapped to our processing module) for 1000 classes is shown in following table
Based on the above table, the expand layer and squeeze layer consume high time in case I and case III respectively, and both layer consume equal time in case II. As inputs layer data and kernel's weight values are buffered internally, processing modules doesn't get idle by DDR3 latency. It was verified in board and we got almost same processing time. Time Taken for Squeezenet v1.1 (mapped to our processing module) for 1000 classes is shown in following table
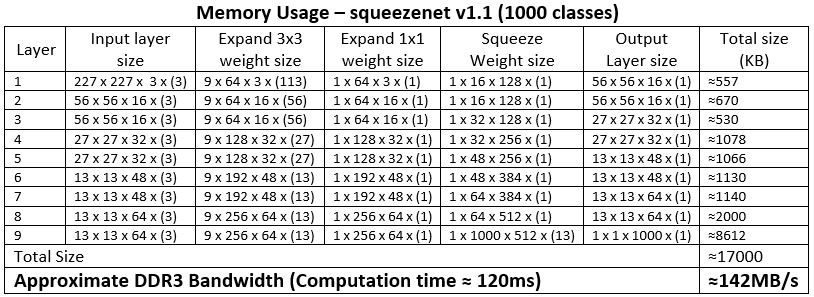
 Memory usage for squeezenet v1.1 configuration listed on the following table.
Memory usage for squeezenet v1.1 configuration listed on the following table.
 Notes :- () - repeat
Notes :- () - repeat

Performance comparsion for Squeezenet v1.1 model

The overall architecture of our design is shown in figure 1. Initially HPS load the network parameters(weights and biases) and the raw images to DDR3 through SDRAM Controller. Then HPS sends the address location of loaded data and configuration information for the computation logic through the Light-Weight HPS to FPGA Bridge. This configuration information contains details about the whole model like number of layers, layer size, number of kernels, enabling pool layer, etc.
Then it will 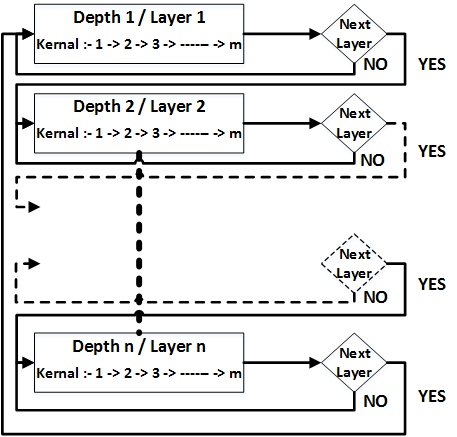
Few example of object detection using pretrained weight of SqueezeNet V1.1 Our approch gave the same results for most of the images with higher confidence. In the figure below, we can observe the ouput values from our design seems to be quantized, this is because final ouput is 8bit.
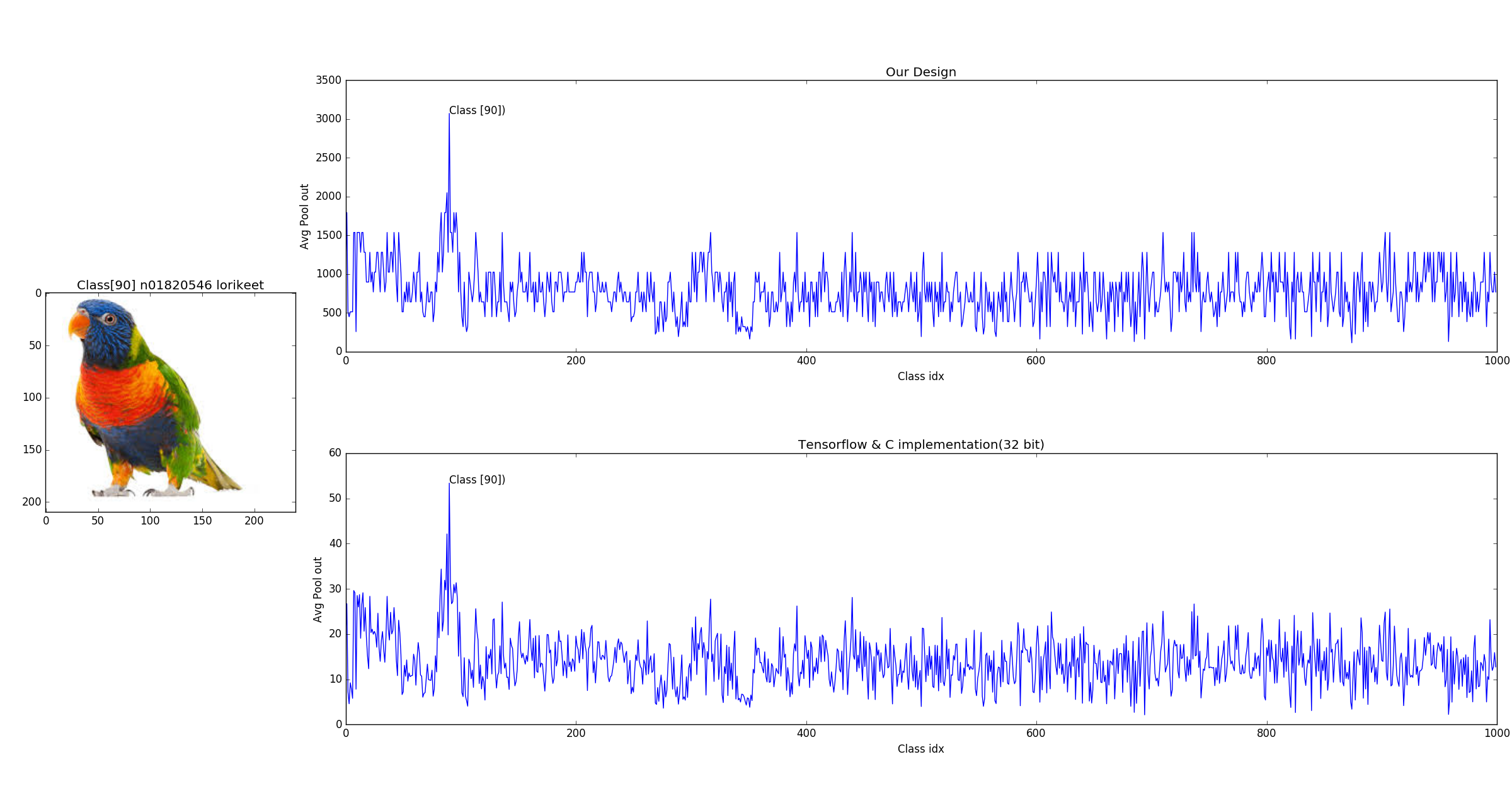
Another Example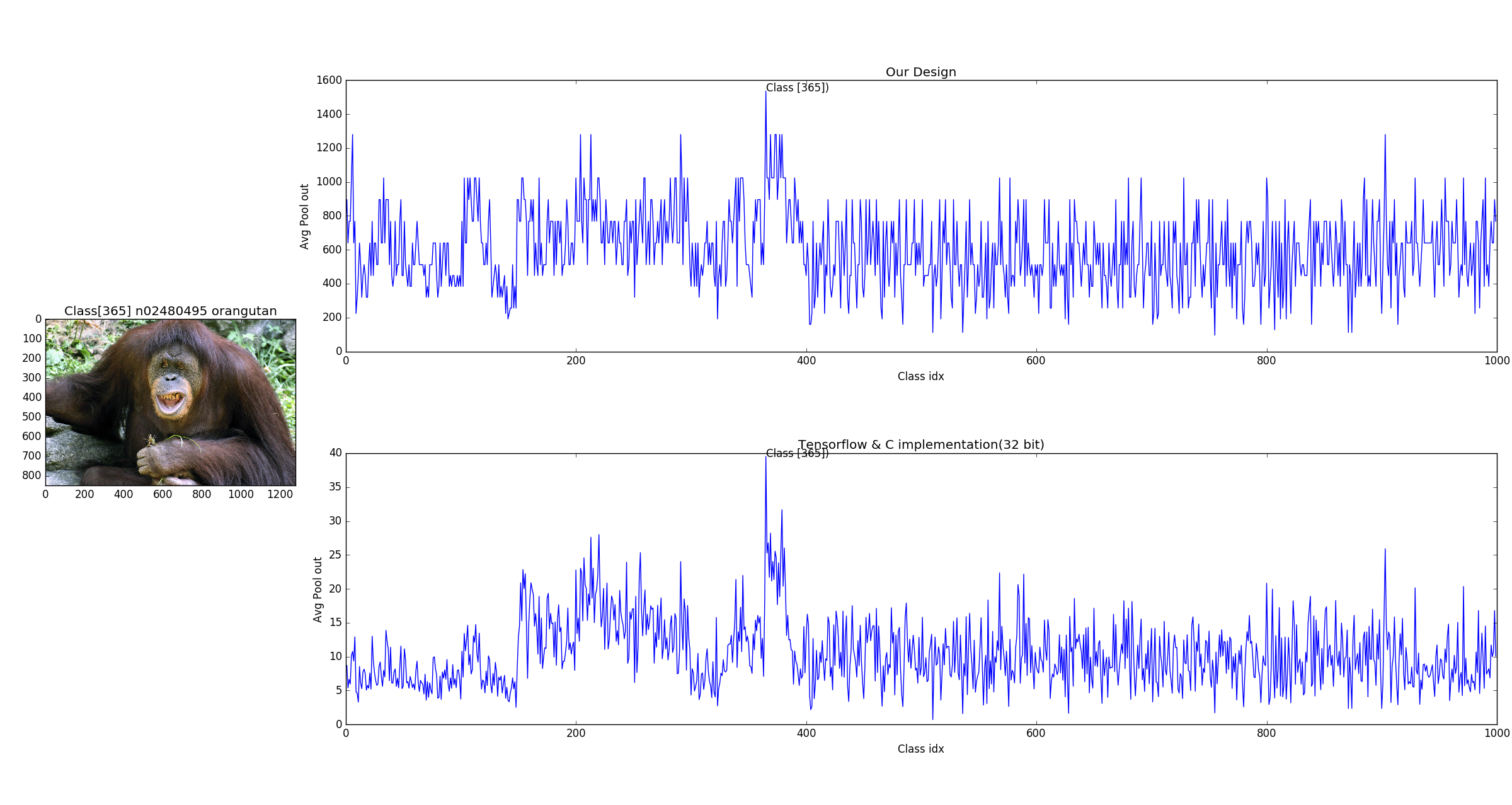
link :- https://github.com/Nathees/Neural_processor
 Architecture")