PR026 » FPGA realization of sign language interaction device using SVM/HMM
This proposal presents the implementation of the communication between deaf-mutes and the normal with a hardware design named sign language interaction device adopting SVM and HMM. On the one hand, gesture recognition system is to create a system which understands human gesture and translates them into texts and audio. On the other hand, our oral language can be interpreted into texts displayed on LCD. Ultimately, the system is designed to identify 20 Chinese sign language and also real time hand gesture signs. The proposed system is very convenient and high-efficiency due to FPGA implementation which is highly suitable for control of equipment by the handicapped people.
Introduction
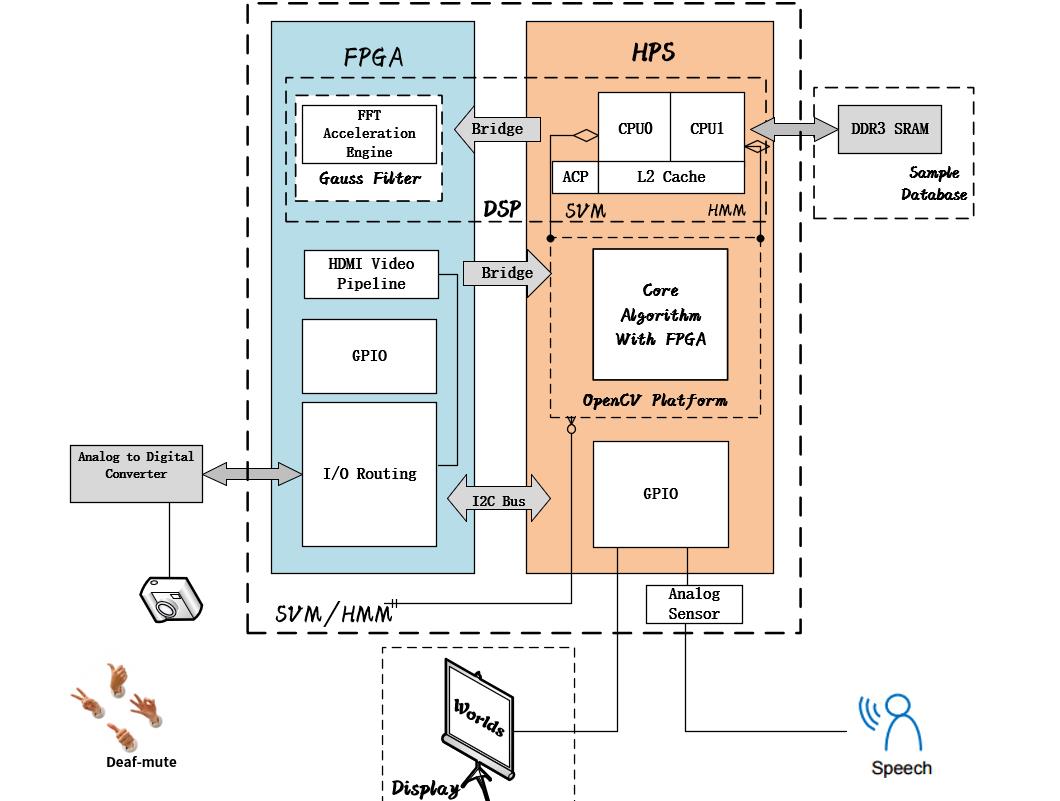
The main purpose of this project is to realize the conversion between sign language and text. The specific process is as follows: the gestures information which comes from camera goes through the decoder, image preprocessing , skin-color detection, edge recognition, SVM classification and HMM which can establish the state model to achieve the purpose of image recognition, and then matches the identified images with the templates that have been trained by SVM and HMM in advance. On the other hand, this project also comes with voice to text function, it can realize the communication between deaf and normal people. Some of the proper nouns used are explained as follows:
Support Vector Machine (SVM), a classifier, has a strong ability of classification. It can automatically find the sample with good distinctions of classification and use the optimal segmentation between the surface structure of these samples to maximize classes to achieve the classification of the interval static image, assisting to realize the HMM model and gesture recognition.
Hidden Markov Model (HMM), a statistical model, mainly used to translate SVM classification results into state transition probability distribution to get the information characteristics of the system to achieve the purpose of extracting image information.
Design Purpose
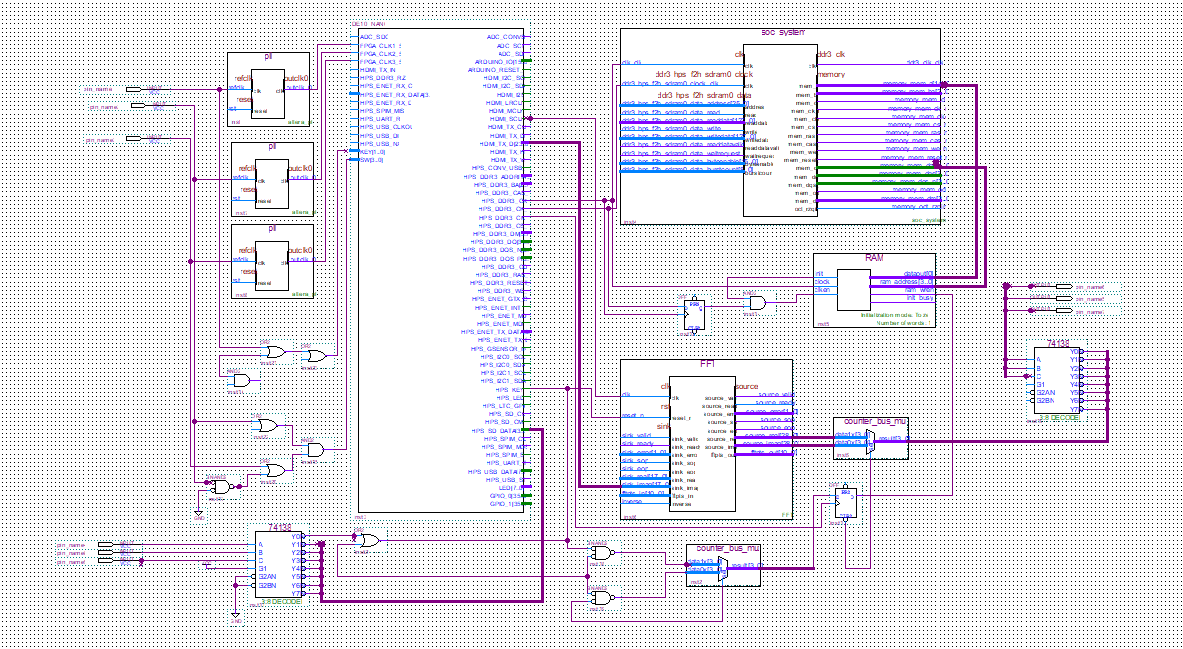
Our sign language translator is based on the DE10-NANO development suite to complete the design. Terasic DE10-Nano is a development kit based on Intel SoC, which integrates the capabilities of a Cyclone FPGA and a dual core ARM Cortex-A9 processor. HDMI data interface transmits efficiently frame image data from the video decoder to HPS CPU0 module through the Bridge cache, FPGA control circuit to achieve the completion of Gauss filtering, color recognition of image data, DDR3 SDRAM is applied to store the sign template and is parallel to HPS CPU1 for dynamic gesture track to achieve real-time gesture tracking and template matching. In addition, the SVM/HMM algorithm based on FPGA will also be completed in FFT Acceleration Engine module. GPIO interface on HPS part is expanded for text display on LCD. The speech reconstruction algorithm based on HMM realizes the matching of words and speech to maximize utilization of the hardware system and the optimization of the text analysis. The proposal is designed to remove the communication barriers between deaf-mute groups and normal people, our sign language translator offers an approach by hand gesture Chinese character, voice information, text information as a bridge between them to establish a harmonious communication environment.
Applications
People who are not able to speak and hear, called deaf-mute, are one of the special population group in our community. The fact that few normal people know about sign language would become a difficulty that impede the development of relationship between these two social groups. The interpreter that we hope to design realizes a two-way communication between them. The combination of FPGA and the HMM&SVM algorithm makes it much easier to implement. The target users are those normal people who want to talk to the deaf-mute, or people who are interested in sign language and want to learn more about it. This machine can be trained to be better when more and more samples of sign language are captured by various people.
 Outline
Outline
Detail Description
Flowchart
Gesture recognition
The video information was collected from D8M-GPIO and converted into image sequences using the frame extraction. The FFT Acceleration Engine module of FPGA is utilized to realize preprocessing by gaussian filter algorithm. The CPU0 module in HPS is used to obtain the characteristic image by using the Canny operators to realize the image binarization. The feature image is classified by the CPU1 module in HPS, and the results are stored in SDRAM. The matching results are transmitted to the HMM module to predict the probability of the next gesture, then they are transmitted to the LCD by GPIO to get the corresponding text information.
Speech recognition
The voice information of the speaker is transmitted through the speech sensor to the HMM module in CPU1 and recognized and transmitted to he LCD.
Hardware Platform
1.Combination between FPGA and HPS to provide a complete system development environment facilitates the compatibility and integration of each module, meanwhile, we adopt the top-down the successive refinement method to improve the efficiency.
2.Based on the look-up table design and parallel operation mechanism, we can quickly implement the DSP algorithm, optimize memory with FFT, and provide operation space for real-time data operation at the same time. it can also provide hardware support for sign recognition design combined with SVM and HMM algorithm.
3. 1 GB DDR3 SDRAM template database provides a 32-bit data transmission, implements fast data processing between HPS and two pieces of CPU, as well as dynamic sign recognition and tracking.
4. HDMI (High Definition Multimedia Interface) is applied to transmit the high definition video and high fidelity audio data to improve the effectiveness of the SVM/HMM algorithm.
In order to realize the function of this translator, apart from this development board, we also need a keyboard to input the command of Linux, a mouse to control the system, a displayer to display our outcomes, as well as a USB flash disk to import video. Some details are shown in the picture below.
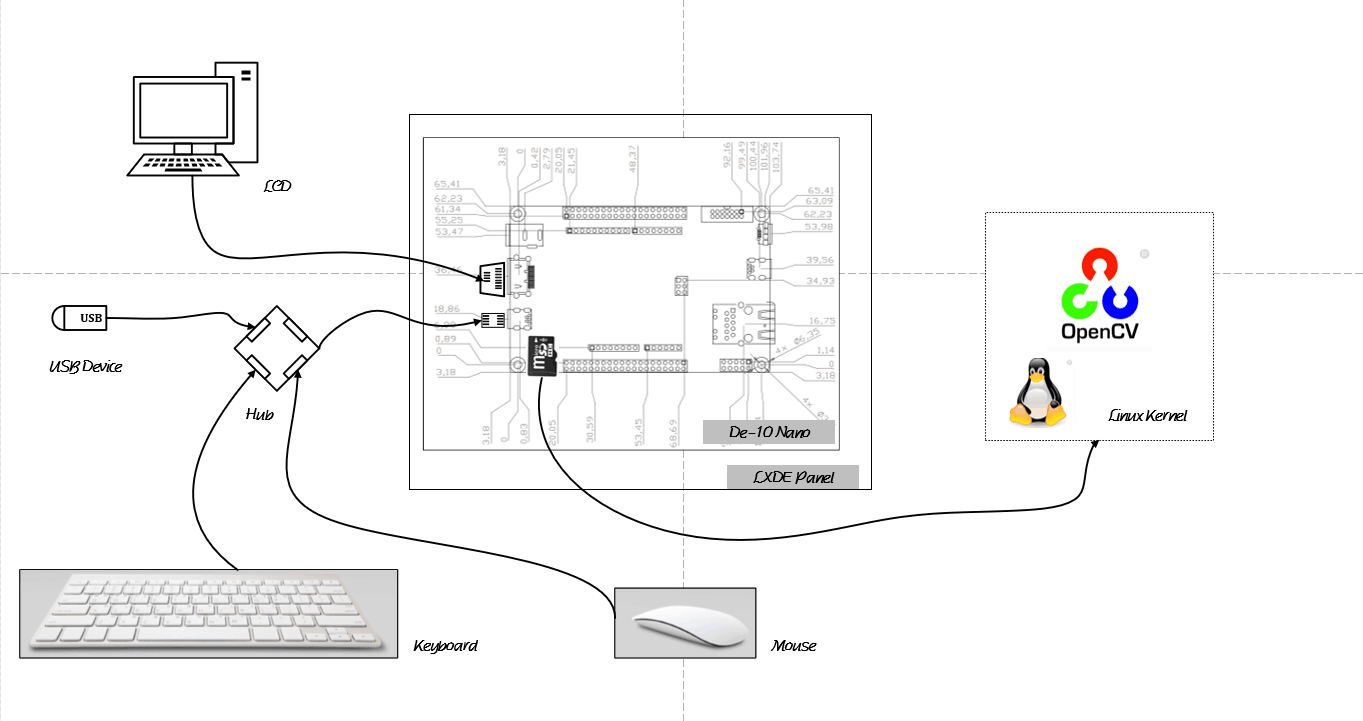
The whole project is based on the hardware support and powerful software algorithms. The details of these two aspects are listed below.
1.Hardware
A whole development board can be divided into two major parts: FPGA and HPS. There are several functional modules on each parts, which play vital roles to realize various functions. In FPGA, we choose to use FFT Acceleration Engine and HDMI Video Pipeline. FFT Acceleration Engine allows the speed of data processing much more faster, while HDMI Video Pipeline serves as a channel to connect the development board and displayer through which we can observe the outcomes easily. In HPS, SDRAM, USB OTG PHY and SD Card are listed in our consideration. SDRAM is connected with CPU0 and CPU1, as well as 12cache, finishing the controls of the whole system. USB OTG PHY helps us to import live video to the development board. SD Card is used to complete the startup of Linux system and hardware initialization by using Boot Loader.
2.Software
We write several algorithms by using C programming language on opencv platform to complete our functions. The algorithms we use are listed below:
1. Frame Extraction
2. Gauss Filter
3. Image Binaryzation
4. Gesture Tracking
5. Feature Extraction
6. Template Training
7. Template Matching
8. Sign Recognition
More details about these algorithms are explained in next section.
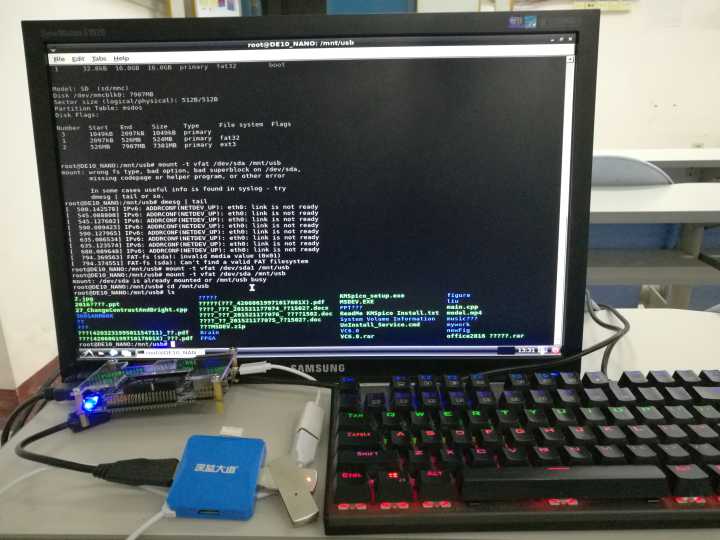
In order to realize this function,we use some functions as the following shows
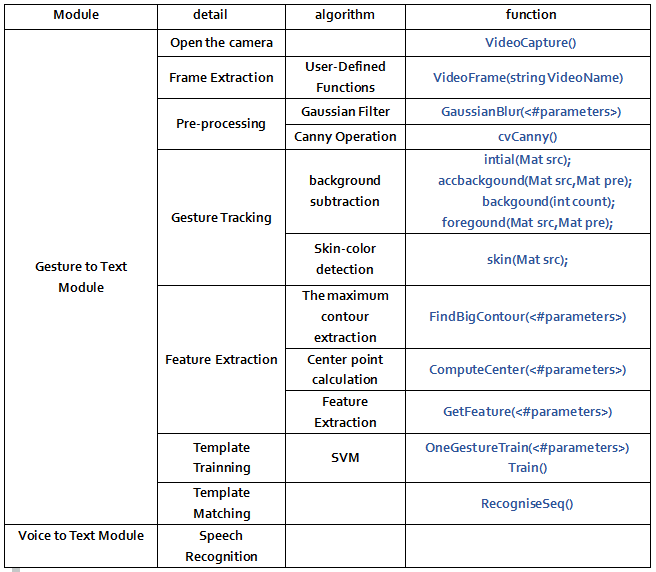
Function Explanation
VideoCapture():The invoking of camera
VideoFrame(string VideoName)
GaussianBlur(InputArray src, OutputArray dst, Size ksize, double sigmaX, double sigmaY=0, int borderType=BORDER_DEFAULT )
InputArray src: The input image can be the Mat type, and the image depth is CV_8U, CV_16U, CV_16S, CV_32F, and CV_64F.
OutputArray dst: The output image has the same type and size as the input image.
Size ksize: Gauss kernel size, this size is different from the previous two filter kernel sizes, ksize.width and ksize.height can not have to be the same, but these two values must be positive odd numbers, if these two values are 0, their values will be calculated by sigma.
double sigmaX:The standard deviation of the Gauss kernel function in the direction of the X.
double sigmaY:The standard deviation of the Gauss kernel function in the Y direction, if sigmaY is 0, then the function will automatically set the value of sigmaY to the same value as sigmaX, and if sigmaX and sigmaY are 0, the two values will be calculated by ksize.width and ksize.height. Specifically, you can refer to the getGaussianKernel () function to see the details. It is recommended that size, sigmaX and sigmaY be specified.
int borderType=BORDER_DEFAULT: To deduce some convenient mode of the image external pixel, there is a default value of BORDER_DEFAULT. If there is no special need to change, you can refer to the borderInterpolate () function.
cvCanny( const CvArr* image,CvArr* edges,double threshold1,double threshold2, int aperture_size=3);
Image:The input single channel image (which can be a color image) can be modified by cvCvtColor ().
Edges:The output edge image is also single channel, but it is black and white.
threshold1: A first threshold threshold2: A second threshold
aperture_size Sobel: The size of the kernel operator
intial(Mat src)

accbackgound(int count);

backgound(int count);
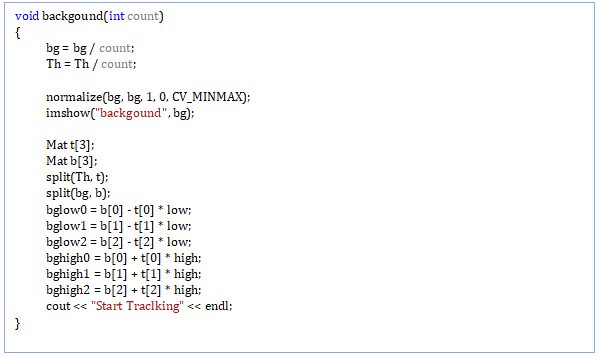
foregound(Mat src,Mat pre);
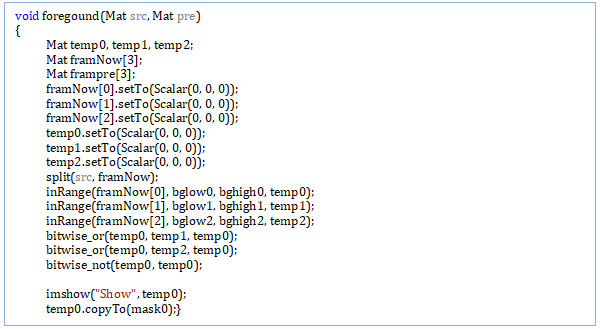
skin(Mat src): Using YCrCb space to realize skin-color detection
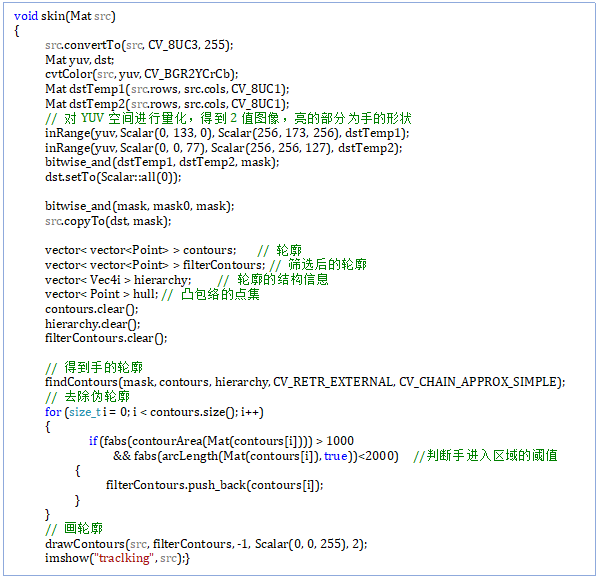
FindBigContour(IplImage* src,CvSeq* (&contour),CvMemStorage* storage)
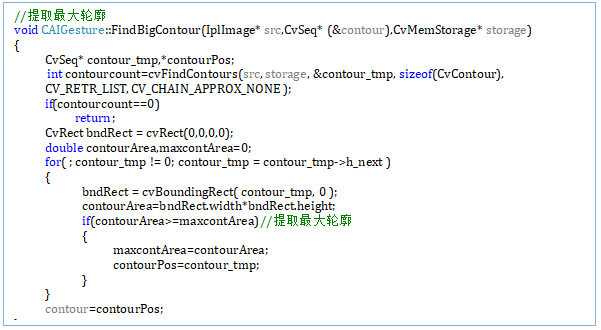

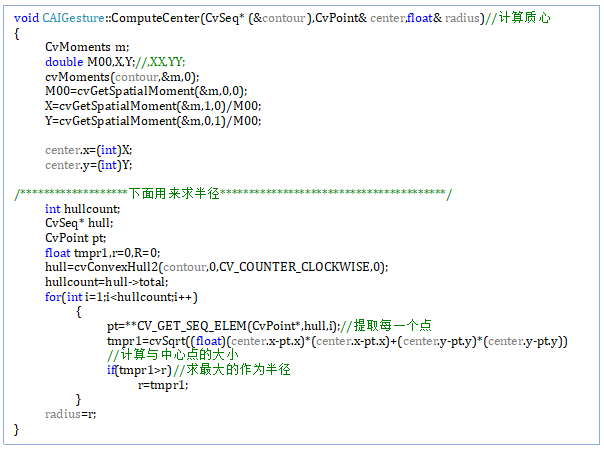
ComputeCenter(CvSeq* (&contour),CvPoint& center,float& radius)
GetFeature(IplImage* src,CvPoint& center,float radius,float angle[FeatureNum][10],
float anglecha[FeatureNum][10],float count[FeatureNum])

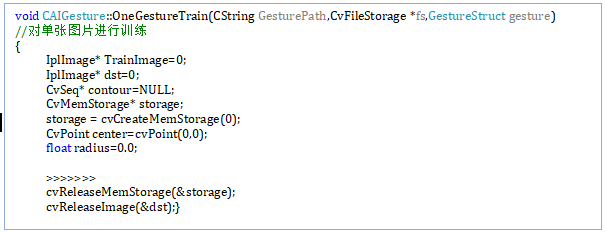
OneGestureTrain(CString GesturePath,CvFileStorage *fs,GestureStruct gesture)
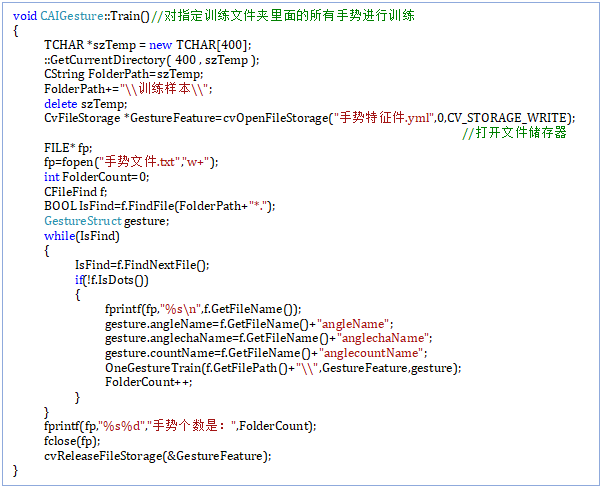
Train()
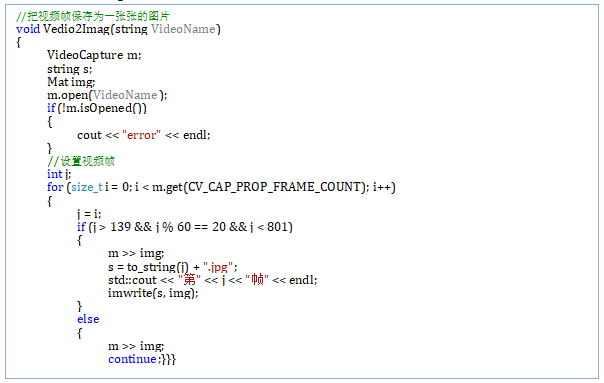
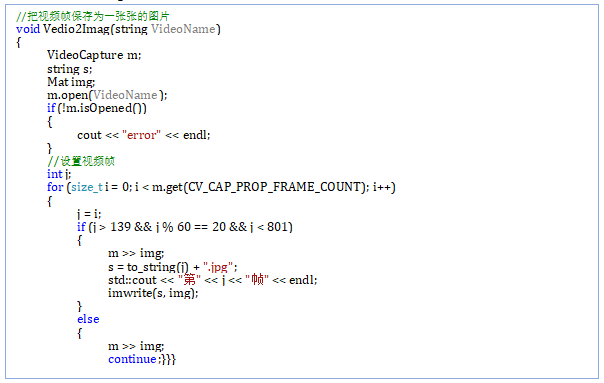
Train() Vddio2Img (String VideoName)

Considering the time cost and hardware performance, we perform Support Vector Machine (SVM) training on 6 static gestures.
1.50 training sets and 50 test sets. The results are as follows:
|
Gesture |
Correct Num |
Error Num |
Accuracy |
Total time for 50 Images /s |
|
“你” |
47 |
3 |
94% |
2.3~2.4 |
|
“好" |
48 |
2 |
96% |
2.2~2.5 |
|
“F” |
49 |
1 |
98% |
2.2~2.4 |
|
“P” |
47 |
3 |
97% |
2.3~2.4 |
|
“G” |
47 |
3 |
94% |
2.1~2.5 |
|
“A” |
48 |
2 |
96% |
2.2~2.4 |
2 .60 mixed gesture recognition, statistical results and time efficiency table:
|
Gesture |
Correct Num |
Error Num |
Accuracy |
Total time for 60 Images/s |
|
“你” |
9 |
1 |
90% |
3.1~3.5 |
|
“好” |
8 |
2 |
80% |
2.8~3.0 |
|
“F” |
9 |
1 |
90% |
2.6~2.8 |
|
“P” |
9 |
1 |
90% |
2.7~3.0 |
|
“G” |
8 |
2 |
80% |
2.5~2.7 |
|
“A” |
9 |
1 |
90% |
2.6~2.9 |
(note that all Models are trained in MATLAB platform)
Since the training data come from the indoors scene the test also needs to be trained much enough data . It can be seen from the data that static recognition achieves better performance than mixed identification.It has a great relationship with the training data , and it also reflects some shortcomings of the SVM in the classification mechanism in terms of the efficiency for dynamic recognition. In addition, the introduction of HMM will greatly improve the performance . Due to the limited time, the research on HMM is still in the commissioning stage. We will submit corresponding evaluations in the follow-up process to further improve the solution.