
PR034 » Controlling drone from mirroring sand table
Control the drone with no constructions but mirroring aerial model.
FPGA 大赛 参赛方案
Control of Drone from mirroring sand table
--无人机沙盘镜像指挥系统设计
《安德的游戏》作为一部科幻巨制,它的结局给人的震撼令人至今记忆犹新,几个孩子自以为在玩的战斗沙盘游戏却通过超距实时通讯“波塞冬”装置传导至几亿光年外同步指挥着一场星际战争,孩子们的游戏胜利在现实中却导致了星际异族的毁灭!!
.jpeg)
我们要做什么? —— 项目介绍
就如安德的游戏,在无人机沙盘镜像指挥系统中,无人机的操控不再依赖传统的指令控制,遥控器操作,而是利用在桌子上的小型沙盘中的引导球,来同步控制无人机。
操控者只需要简单的移动沙盘中放置的引导球,无人机会根据引导球的轨迹变化来模仿引导模型的移动。这样,无人机的操作就可以脱离遥控和指令!
我们怎么做? —— 项目结构设计
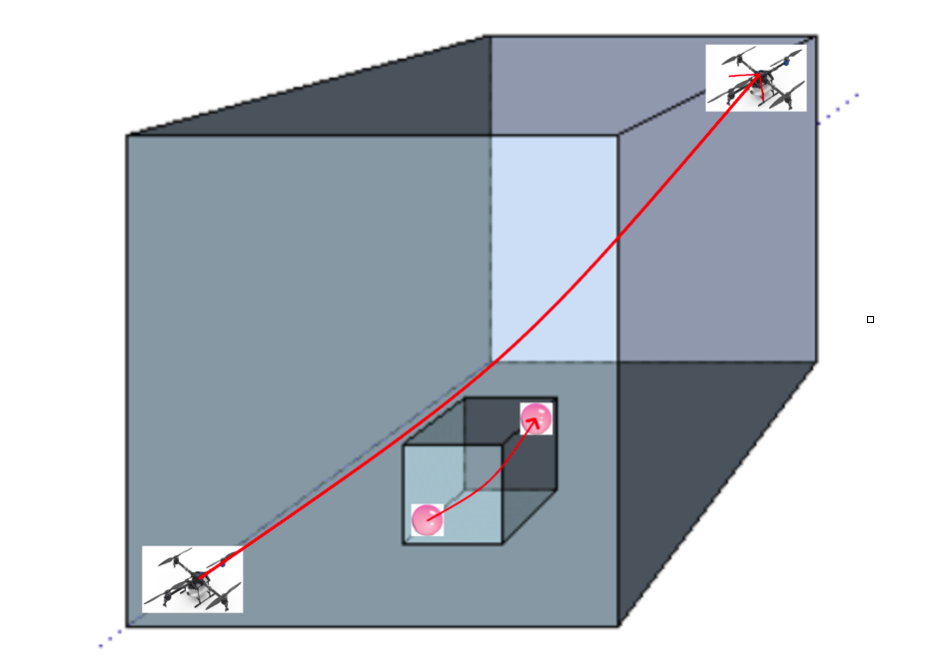
如图所示,用手移动地上小沙盘中引导球的位置,室内环境中的大无人机也会随之运动到相应位置(图中引导球从沙盘左下角飞到右上角,无人机也跟着从室内左下角飞到右上角)
在一个室内环境中,在地面上的桌面上放置我们的小沙盘(就是当前室内环境的缩小版模型,0.5m*0.5m*0.5m)并在其中放置一个浮空的可小规模移动引导球,通过人为对引导球在缩小版室内环境内移动,实现实际大室内环境(10m*10m*10m)中的无人机的镜像移动(比如沙盘里把引导球从沙发移到楼梯,那么真实环境中的无人机也会从沙发飞到楼梯)。
2. 无人机
我们使用一台无人机携带声波发生器,发射固定频率声源作为定位信息(无人机特性满足的情况下,我们可以使用无源无人机,利用无人机本身噪声作为定位信息)。
沙盘可以放置在桌面上,引导球可以用悬线/磁悬浮技术定位在沙盘中。桌面的沙盘是室内空间的缩小比例模型。
4. 麦克风阵列
室内空间和沙盘分别配置麦克风阵列,沙盘中的麦克风阵列实现对于引导球的定位。室内空间的麦克风阵列组可以放置在室内的不同位置以便于提高精度,每个麦克风阵列可以确定声源来向,因此麦克风阵列组视空间位置而定,数量越多精度越高,至少需要两个阵列形成麦克风组。
5. FPGA组件
FPGA组件放置在沙盘旁边作为控制中心,处理麦克风阵列接受的信号。FPGA分别对两组麦克风阵列进行信号处理得到引导球&无人机的位置信息,从而对无人机进行指令控制。
我们用什么实现? —— 项目原理
1.声源发射
引导球以及无人机各装载一个固定频率的声波发射器。引导球不断移动时搭载的声源也不断移动,通过地面上系统的计算实现对引导球的实时定位,这个定位信息再转化为对无人机的控制指令信息,再配合无人机上声源的实时移动实现对无人机的实时镜像控制。
2.麦克风阵列
放置在桌面上的两组麦克风阵列用于分别接收引导球以及无人机发射的信号,由于各个麦克风之间存在间距,因此接收到的各路信号都存在一个相位差(在远场模型下这个相位差只与声源位置的空间极坐标的theta,phi有关)。由于fpga只能计算数字信号,因此对麦克风接受的信号要先进行采样,采样率越高,精确度越高。
3.波束成形
利用 导向矢量 = 权重矩阵 的原则实现了确定空间域的位置的信号增强或者减弱。导向矢量是远场模型中声源到麦克风按空间域形成的矢量矩阵。权重矩阵使得波达方向的波束相位得到补偿,实现增强或减弱。算法将空间域根据精度进行划分,对于确定空间域设计权重矩阵,实现成形。
4.声源定位
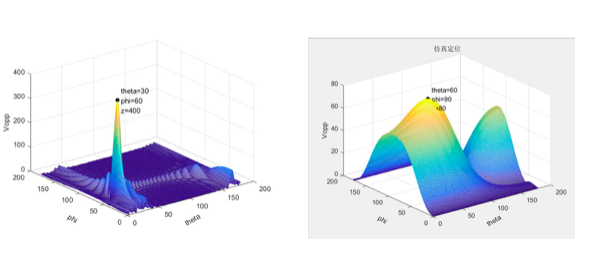
不同位置声源发送的信号被麦克风阵列接受后各路的相位差也不一样,先由公式计算空间中一定数量点(数量越多精度越高)的相位差,然后计算这些所有点对麦克风接收到的信号进行相位补偿,当相位补偿与实际信号相位差刚好相等时,各路麦克风信号的相位一致,采样后再叠加后的峰峰值会达到最大,那么这个时候的相位补偿对应的theta,phi就是声源位置的theta,phi。如图所示,计算所有点对应相位补偿的峰峰值后,只有实际声源位置对应的角度峰峰值最大。
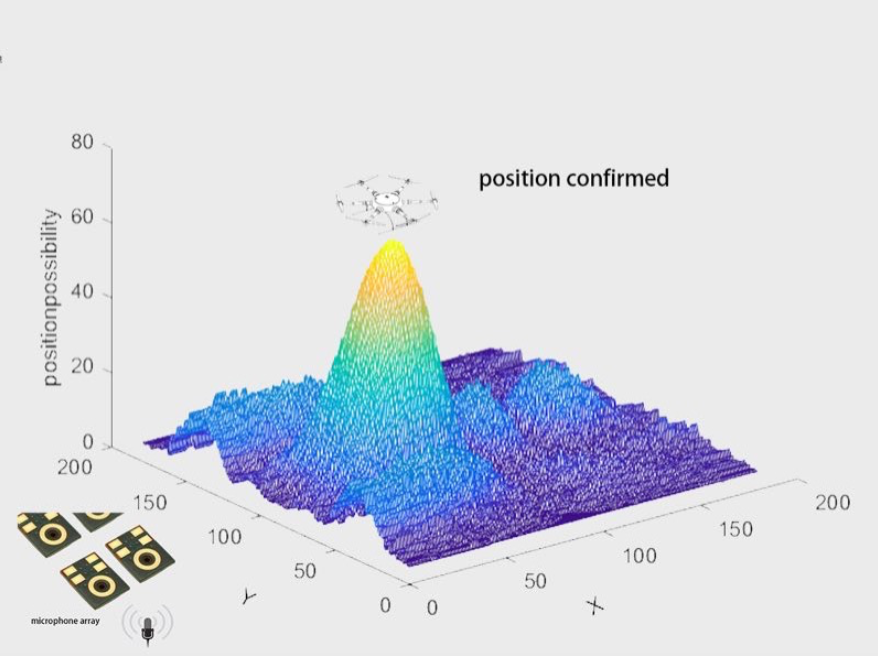
5.定位信息转化为指令
引导球定位之后,移动时定位坐标也会发生变化,通过信号处理将这一坐标变化转化为对无人机的指令信号,使其飞到室内环境中的对应坐标。
我们为什么这样做? ——项目优势以及参数要求
首先,声源定位对于室内定位任务来说,具有原理简单,可靠性高,成本较低等优势。声源定位可以利用无人机携带的固定频率声源来实现,固定频率声源的简易可靠大大降低了无人机定位的复杂实现过程。并且,如果无人机特性满足需求,利用无人机自身噪声特性实现的定位,更是使得定位变得简单。
其次,声源定位通过麦克风阵列组可以实现三维定位,而一般的无人机视觉定位只能依靠光电特性实现二维定位,并且受到地形因素制约;携带摄像头也会增加无人机的负担。GPS等其他常用技术对于室内精准定位也不适用,因此利用波束成形的声源定位具有很大的优势。
波束成形原理包含对于空间域的划分,划分越细,精度越高;但是同时计算要求越高。FPGA的特点是大量与或阵列具备高效的并行计算能力,因此对于可以实现并行计算的FPGA空间划分,使用FPGA进行计算,可以大大提高对于信号处理的速度,因此可以实现高效的实时声源定位。如图所示,在空间球坐标中,若是使用cpu只能同时计算少量的空间点,精度远远达不到要求。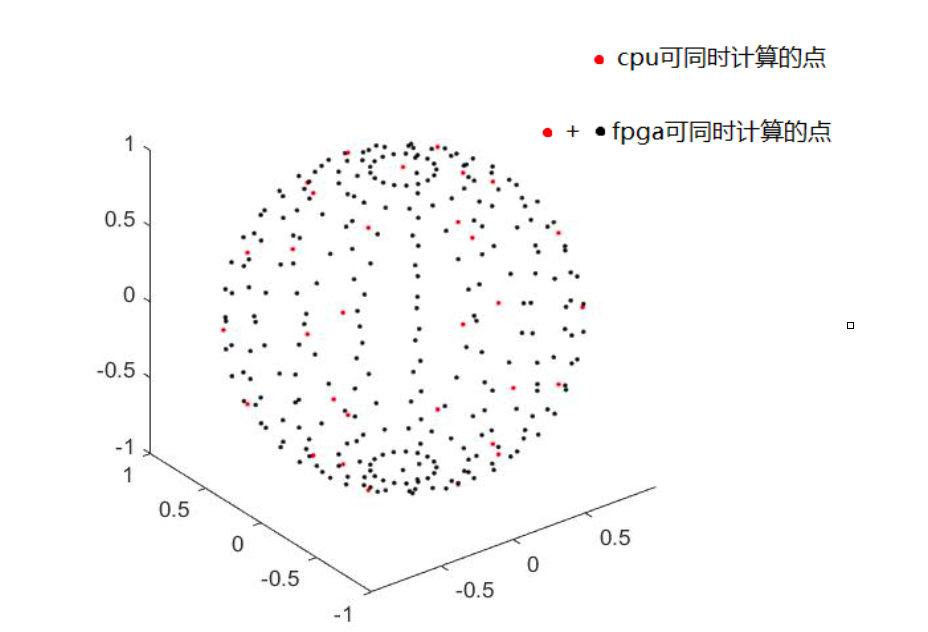
我们还能改进什么? ——项目优化
当能实现我们想要的沙盘镜像指挥效果时,我们的微型无人机当然是越轻巧越好,那么我们是否可以甚至是把上面的声波发生器也去掉呢?!答案是肯定的!无人机的桨叶以及马达的声音或许就可以成为我们想要的声源!
项目特点:
本项目是一个从硬件设计到软件实现到数据显示的完整系统,实现了对给定声源的室内定位
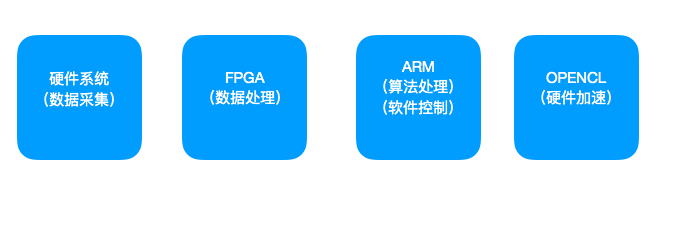
项目的优势在于利用了FPGA +ARM的组合,在数据的采集与处理,数据运算的软件控制,以及算法的并行优化等方面具有创新性。
FPGA在数据采集与处理,以及并行运算上的优秀表现,加上ARM在C语言软件实现的优异性能,在本项目中得到了极大的发挥。
我们设计的利用波束成形算法实现的定位算法,需要进行较大量的并行运算,因此在FPGA下的运算,性能可以得到极大的提升,这也是我们利用DE10 开发板进行此项目的初衷。
 硬件实现
硬件实现
麦克风选择
本次项目选用SPM0423麦克风,这是一款pdm麦克风,输出为pdm信号,其优势在于高采样率,单比特,抗干扰能力强。使用pdm麦克风可以使布线更加方便。

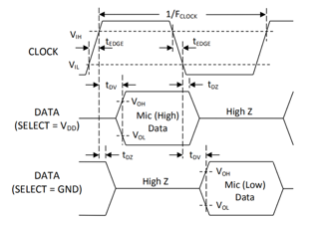
pdm麦克风除了电源引脚以及数据引脚之外,还有有一个选择引脚,通过这张时序图可以看出,该麦克风可以选择在时钟沿上升沿采样或者在时钟沿下降沿采样,利用这一特性可以将阵列中4个麦克风的输出用两根线引出,在处理时分别用上升沿和下降沿采样即可。
PCB设计
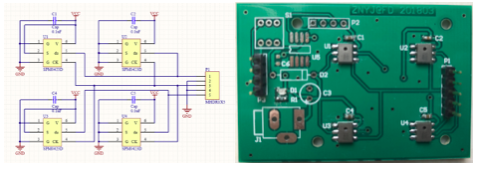
使用altium designer设计电路图以及pcb板,设计时可以看见四路麦克风只需要引出5个排针,包括电源,地,两根信号线,这样做毫无疑问节约了空间,减少系统的繁琐性,做成pcb更有利于麦克风间距的一致性与稳定性。对应于信号频率的8khz,两个麦克风的间距必须大于340/2*8000=21.25mm,因此在设计pcb时将4个麦克风间距取为20mm,这样4路信号才不会混叠。设计时还要注意用地线把信号线以及时钟线包裹起来减少干扰。
PDM解码
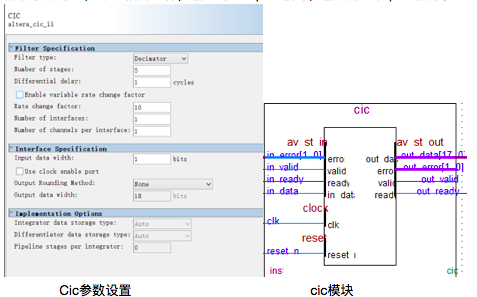
麦克风输出的pdm信号并不能直接用来计算,必须解码成为相应的pcm信号成正弦波的样子才可以用以计算,由于pdm为过采样信号,过采样技术将调制器里的1bitADC带来的大量量化噪声分散到数十倍于原始频率的频带中,对pdm信号的解码就是对信号进行数字抽取滤波,获得原始信号量化后的pcm信号,因此解码时将pdm信号经过一个cic降采样抽取滤波器处理即可以输出pcm信号,这里选取cic阶数为5,抽取系数为10,即10倍降采样,输入为1bit pdm信号,输出为18位pcm信号。
FIR滤波
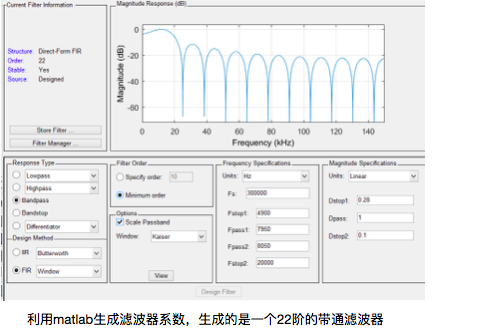
由于项目中所使用的声源为8khz正弦信号,在pcm解码后还需要一通带为8khz的fir滤波器,设计时利用matlab里的fdatool工具来生成fir系数,生成的系数导出到txt文件中。选择模式为带通滤波器,fir,窗函数法,设置采样率30whz通带以及截止频率,以及衰减系数,可以看到幅频特性,通带确实是8khz,由于fpga dsp资源有限衰减不能设置很高,但是由于pdm本身抗干扰能力强的特性这样的幅频特性已经足够了。
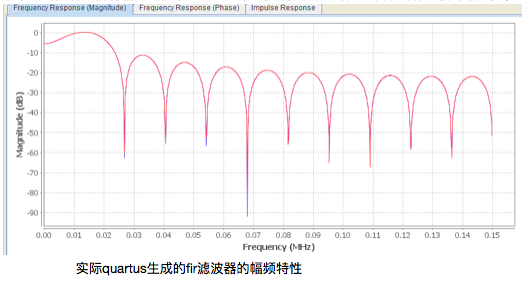
FIR core:得到fir系数后,使用quartus里的fir ip核生成fir滤波器,打开后将采样率设置为30whz,再将fir的系数文件fir8.txt导入,可以看到幅频特性是我们想要的。生成的fir滤波器输入18位,输出为33位,基于系统的限制我们将输出截位取24-9共16位(这样选是因为实验发现这样的信号最好)。
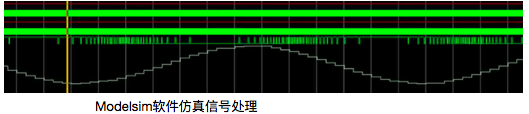
Cic与fir滤波器都生成完毕之后,利用modelsim仿真cic以及fir滤波器,将仿真的pdm信号事先存在rom模块里,以3M时钟频率读出,依次经过cic滤波器10倍降采样得到30whz的pcm信号以及时钟为30whz的fir滤波器,得到仿真波形如图,可以看到1bit的pdm信号在幅度大时1的频率也大,幅度小时1的频率也小,经过降采样抽取滤波以及带通滤波后确实得到了8khz正弦pcm信号。
在验证了cic滤波器以及fir滤波器可用之后,就需要用实际的麦克风来测试了,利用quartus的signaltap工具抓取输出的pcm信号,由于fpga资源有限,不能同时看到4路麦克风的信号,这里可以在电路中设计一个4选1选择器,用2个开关控制,就可以调节开关来观察4路的信号了。用外部声源播放8khz声波信号,得到的pdm以及解码滤波后的pcm信号就是这样,可以看出确实解码成了正弦波。

数据传输
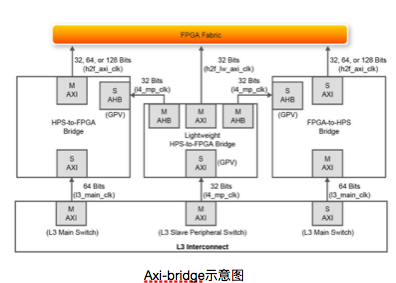
为了实现fpga将信号传递给hps端,这里采用axi-bridge实现数据传输,总共有三种桥,包括f2h_axi(32-64-128位),h2f_lw_axi(32位),h2f_axi(32-64-128位),由于需要传输4路麦克风的16位信号,因此需要使用h2f_axi bridge,在qsys中将各路需要传输的信号与桥相连,并同时引出到fpga侧,与wire_signal连接,即可实现数据传输。
在数据传输时,我们采用ram来实现4路信号的同时并行传输,分为两个状态,写状态以及读状态,写时将fir的输出写1000个点在ram里,写完后计数器的进位信号置1,触发状态机进入读信号,将4路1000个数据读出并通过桥传到hps端。在hps端设计程序读取桥传过来的数据,一共有6个数据,包括4路信号,一个地址信号,一个状态信号.当状态信号为1时说明ram在读数据出来,hps端写程序将信号存入数组,当状态信号为0时说明ram在写,不进行操作。
硬件部分利用FPGA和PCB板进行操作,软件部分的算法实现基于ARM,双方通过AXI进行通信
算法实现
算法实现部分,基于波束成形算法,生成source权重补偿矩阵,进行信号补偿,根据最大峰峰值原则,判断声源位置。
波束成形算法原理:
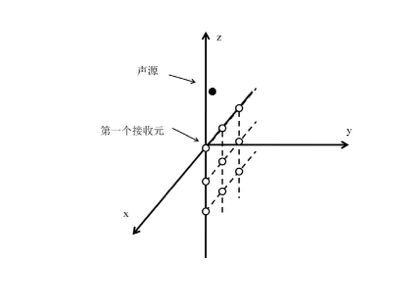
如图坐标系,e行f列的麦克风的坐标为(-(f-1)d,0,-(e-1)d) d为麦克风间距。
可以得到声源到麦克风接受元的距离
Ref = (e-1)*d*cos(theta)+(f-1)*d*sin(theta)cos(phi)
设第n路麦克风的输入信号的权值为w,组成向量W = transpose(w1,w2,w3…)
则输出信号z(t) = transpose(W)y(t)
由上文原理描述 z(t) = transpose(W) *a(r,theta,phi)*s(t)+ transpose(W)*e(t)
e为噪声。
因此可以看到z(t)的信噪比与W向量的方向有关,W的方向可以约束接收信号的信噪比
数学上有多种方法在此情况下使得W向量对于信号信噪比的影响有明确映射。比如最大信噪比准则,信号幅度最大,功率谱密度准则等等。
在我们的算法中我们简单的通过信号幅度最大作为W的取值设计。
因此我们通过导向矢量 a = W 作为线性代数计算得到最大值的条件,此时使得z(t)的值有最大。
该算法的本质是通过W矢量对于某一波达方向的声音进行麦克风阵列的相位补偿,使得该方向的声音得到增强/削弱。
MATLAB仿真:
MATLAB设置高斯白噪声,图为4*4个麦克风组成阵列的仿真,2*2麦克风阵列的仿真
source权重矩阵设计:
source权重利用matlab生成source.c
生成原理:按照Ref = (e-1)*d*cos(theta)+(f-1)*d*sin(theta)cos(phi),将每路信号在对应的theta,phi位置补偿到无相位差
软件实现
ARM c程序:
func_getsig : 该函数使用了AXI桥进行了数据的获得,将麦克风阵列的四个麦克风在连续1k个点中
的声音序列幅度信息以4*1000的二维数组存储,并设置全局数组,在调用该函数后设
置声音序列
func_getsrc : 该函数直接利用python脚本将src矩阵的代码写入c文件,在全局数组中调用。
func_calculate : 利用src和sig矩阵进行四个麦克风的序列峰峰值叠加,寻找一个周期内的最大峰峰
值进行判定,返回声源信息的theta,phi角度
显示模块实现:核心代码利用python实现对串口的处理,json文件的读写
serial port 利用python处理串口传输的byte型的数据流,转为int型的定位信息
json python将位置信息存储为json文件,统一的格式便于ajax读取
js & ajax 利用JavaScript ajax得到json文件的数据格式,利用html的canvas画布绘制模
拟的3D场景。利用直线显示定位声源轨迹。
apache 利用XAMPP工具包实现apache服务器在本地使用html浏览器浏览
OpenCL实现
综述:
1.为什么使用OpenCL
OpenCL是由非盈利性组织Khronos Group组织发布的针对异构设备(如如CPU,GPU,FPGA)进行并行化计算的一套开源的API以及程序语言。面向 OpenCL 的英特尔 FPGA SDK 支持充分利用 FPGA 的独特功能提升性能,实现高能效和低延迟。使用它的优势主要在于以下两点:
第一,它提供两种并行化的模式,包括任务并行以及数据并行。
我们在实现过程中参考到友晶科技官网给出的VectorAdd历程,该代码包实现的功能是并行展开100000个加法运算,这为我们的代码提供了模板与其启示。如在循环遍历空间角度θ和φ时,我们需要并行展开关于两者的180*180种排列组合情况,提高计算效率。具体包括收集信号源数据及偏置补偿数据的数据并行,与计算波形峰峰值的任务并行。
第二,OpenCL API是按照 C API定义的,由C和C++封装而成。使用OpenCL C语言编写的代码可以在支持OpenCL的设备上运行。这为我们的编写和调试过程提供了方便。
2.OpenCL优化对象详述
本设计中的OpenCL优化对象集中在定位算法calculate上。我们先来看下其C语言概述:
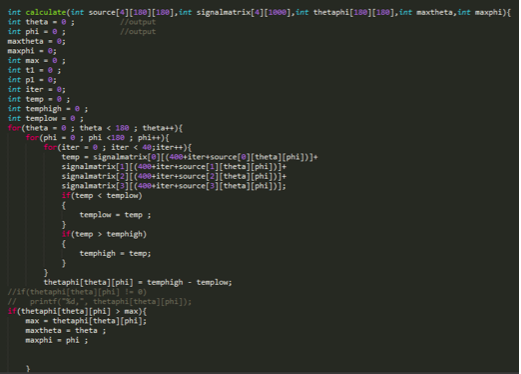
该算法的核心是第一步先对某一固定θ和φ波源角度组合,计算其位置上(假定为此位置)得到的40个波形采样数据。由于有四个采样麦克风,在此步骤中我们需要并行展开40个采样点上的信号数据四向量加法计算,然后比较找出其中某个采样点所对应的峰峰值。第二步我们通过循环结构遍历180*180中θ和φ的排列组合,每种组合计算一个峰峰值,再比较得出实际最大峰峰值,它对应的就是波源位置(θ,φ)。
即从总循环体外的角度看,优化所实现的过程应该是,并行展开180*180种位置组合,串行比较峰峰值,此峰峰值由并行展开40个采样点偏置计算,再串行比较最佳采样点得到。
3.如何实现OpenCL优化
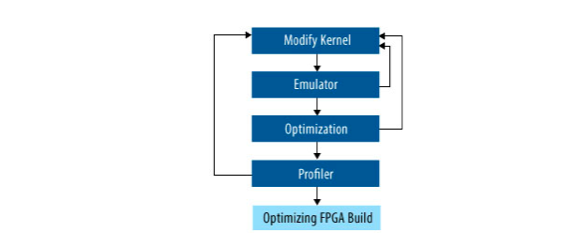
第一步,撰写编译.cl代码为核文件.aocx(kernel)。
面向OpenCL的Intel SDK™ for FPGA提供了全套开发工具及说明白皮书。我们依照上面的步骤可以顺利进行编译。在大循环体的180*180种组合中,采用以下核文件进行编译处理,注意将θ和φ定义为指针形式实现并行查找,A为偏置补偿矩阵延展所得一维向量source,B为麦克风采集到的信号大小数据signal:
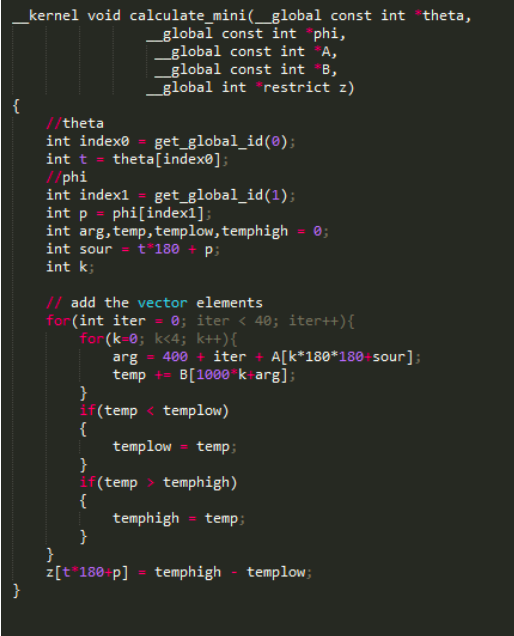
当然,内部小循环的四向量加法运算本身可以继续优化,比如采用如下核文件:
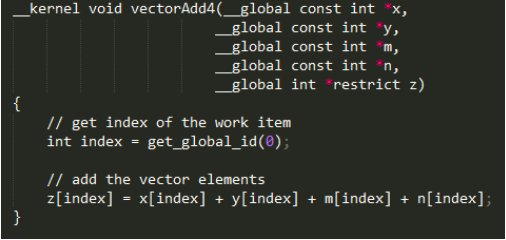
我们在实验中发现,大循环的并行优化对结果影响较大(即处理速度),因此采用的是前者。Cl核文件编译报告见下图:
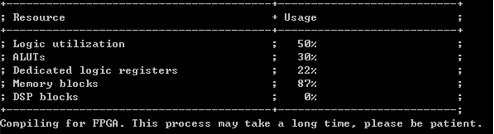
编译好的二进制核文件为.aocx文件,我们将通过host文件的执行在FPGA板上调用执行核文件(kernel)

第二步,撰写编译.cpp为host执行文件,供FPGA进行算法实现。
我们将在main.cpp中实现这个程序流程,其过程示意图如下,接下来逐一分布解析:
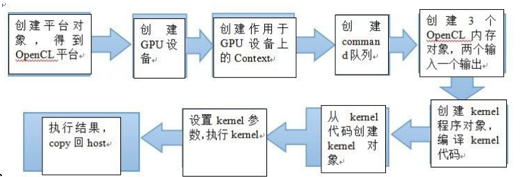
// Get the OpenCL platform.
platform = findPlatform("Intel(R) FPGA");
// Query the available OpenCL device.
getDevices(platform, CL_DEVICE_TYPE_ALL, &num_devices)
本项目中,num_devices始终为1
③ 创建上下文
我们理解,Context 是指管理 OpenCL 对象和资源的上下文环境。为了管理 OpenCL 程序,下面的一些对象都要和 Context 关联起来:
• 设备(Devices): 执行 Kernel 程序对象。
• 程序对象(Program objects): kernel 程序源代码
• Kernels: 运行在 OpenCL 设备上的函数
• 内存对象(Memory objects): 设备上存放数据
• 命令队列(Command queues): 设备的交互机制
• 内存命令(Memory commands)(用于在主机内存和设备内存之间拷贝数据)
• Kernel 执行(Kernel execution)
• 同步(Synchronization)
// Create the context.
context = clCreateContext(NULL, num_devices, device, NULL, NULL, &status);
该Command队列作为请求在设备上执行的一种机制。在 Kernel 执行前,我们一般要进行一些内存拷贝的工作,比如把主机内存中的数据传输到设备内存中。命令队列在 device 和 context 之间建立了一个连接。
for(unsigned i = 0; i < num_devices; ++i) {
// Command queue.
queue[i] = clCreateCommandQueue(context, device[i], CL_QUEUE_PROFILING_ENABLE, &status);
}
// Input buffers.
input_a_buf[i] = clCreateBuffer(context, CL_MEM_READ_ONLY,
4*180*180 * sizeof(int), NULL, &status);
input_b_buf[i] = clCreateBuffer(context, CL_MEM_READ_ONLY,
4*1000 * sizeof(int), NULL, &status);
input_theta_buf[i] = clCreateBuffer(context, CL_MEM_READ_ONLY,
180*180 * sizeof(int), NULL, &status);
input_phi_buf[i] = clCreateBuffer(context, CL_MEM_READ_ONLY,
180*180 * sizeof(int), NULL, &status);
// Output buffer.
output_buf[i] = clCreateBuffer(context, CL_MEM_WRITE_ONLY,
180*180 * sizeof(int), NULL, &status);
⑥ 创建程序对象
for(unsigned i = 0; i < num_devices; ++i) {
// Kernel.
const char *kernel_name = "calculate_mini";
kernel[i] = clCreateKernel(program, kernel_name, &status);
}
// Create the program for all device. Use the first device as the
// representative device (assuming all device are of the same type).
std::string binary_file = getBoardBinaryFile("calculate_mini", device[0]);
printf("Using AOCX: %s\n", binary_file.c_str());
program = createProgramFromBinary(context, binary_file.c_str(), device, num_devices);
// Set kernel arguments.
unsigned argi = 0;
status = clSetKernelArg(kernel[i], argi++, sizeof(cl_mem), &input_theta_buf[i]);
status = clSetKernelArg(kernel[i], argi++, sizeof(cl_mem), &input_phi_buf[i]);
status = clSetKernelArg(kernel[i], argi++, sizeof(cl_mem), &input_a_buf[i]);
status = clSetKernelArg(kernel[i], argi++, sizeof(cl_mem), &input_b_buf[i]);
status = clSetKernelArg(kernel[i], argi++, sizeof(cl_mem), &output_buf[i]);
const size_t global_work_size[2] = {180*180, 180*180};
printf("Launching for device %d (global size: %zd, %zd)\n", i, global_work_size[0], global_work_size[1]);
status = clEnqueueNDRangeKernel(queue[i], kernel[i], 1, NULL, global_work_size, NULL, 4, write_event, &kernel_event[i]);
⑨执行结果拷贝回主机
// Read the result. This the final operation.
status = clEnqueueReadBuffer(queue[i], output_buf[i], CL_FALSE, 0, 180*180 * sizeof(int), output[i], 1, &kernel_event[i], &finish_event[i]);
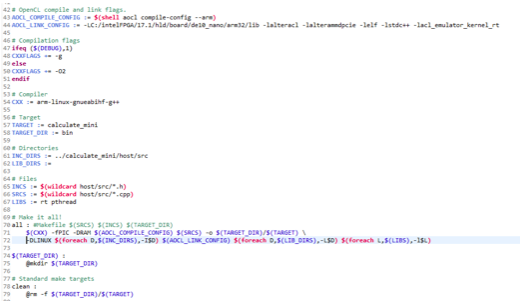
综上,在c++文件编译host的过程中我们运用Eclipse for DS-5 v5.27.1平台进行编译调试。由于windows环境问题,起初未能依照操作手册成功编译。在学习相关知识并重写了Makefile文件后得到host文件,如下:
项目总结与展望
项目的完成,在前半段时间由李林阳和文柯宇负责了软硬件的设计 ,在后期李小龙加入进来负责OpenCL硬件加速部分的设计。我们的项目存在了许多不足,比如定位的时间和精确度还不够理想,以及信号的处理仍然与能够实际投入应用,与市面上的商品级阵列有很大差距,不过从项目开始到结束, 我们项目组的成员从比较陌生的知识领域一步步做下来,积累了相当多的经验,也学习到了相当多的知识,所以在此特别感谢指导老师林青老师,以及Intel比赛方的大力支持。
calculatino time of ARM
1s-2s/per cycle
( using simply ARM without Opencl acceleration )
refresh rate of html page : 1s
with Opencl:
calculation speed : 20mS/cycle
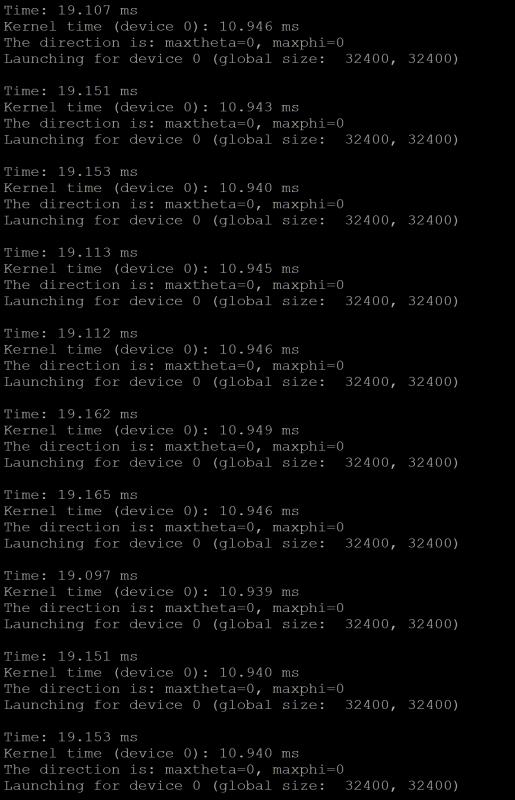
so with OpenCL acceleration , our performance will get much better .