
PR039 » FPGA Implementation of Spiking Neural Network with SNN
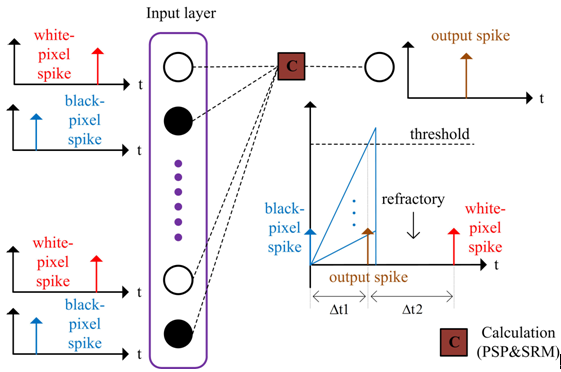
The traditional supervised learning algorithm of ANN, such as Back-Propagation (BP) algorithm based on gradient descent, is not suitable for SNNs because the information is propagated by a sequence of spikes which are not continuous and differentiable. The STDP learning algorithm represents a Hebbian form of plasticity that adjusts the strength of connections based on the relative timing of a particular neuron's output and input spikes. It simplifies the timing information of spikes by using discrete time models, such as the Spike Response Model (SRM) and Integrate-and-fire (I&F).
The overall design is divided into three major modules: spike input module, calculation output module and memristor-time module. First of all, the input images have to be spike coded as mentioned above. The black-and-white binary image is divided into two fires, the neurons corresponding to the black-pixel spikes being fired at the same time. After a certain period of time, the neurons corresponding to the white-pixel spikes fire at the same time. Enter the input layer after encoding is complete and it is the process of spike input module. In the calculation output module, the output data of the input layer in the previous module is calculated. The calculation process includes modified PSP and SRM rules. And we can get an output spike in the output layer. At this point we can get black-pixel spikes, white-pixel spikes, and output spikes (output spikes can be controlled between black-pixel and white-pixel spikes). According to the foregoing algorithm, inputting these three spikes into the memristor-time module can directly obtain two weight values that need to be updated corresponding to two time intervals. Each output spike corresponds to two memristor models. The first records the time interval between the black-pixel spike and the output spike and the other records the time interval between the white-pixel spike and the output spike. This process is controlled by an internal control module for each switch, so that different memristor models can record data for different periods of time and then convert them into updated weights. Then bring the updated weights into training and continue this cycle until the end of the training. The total hardware design process is shown as Fig. 1.
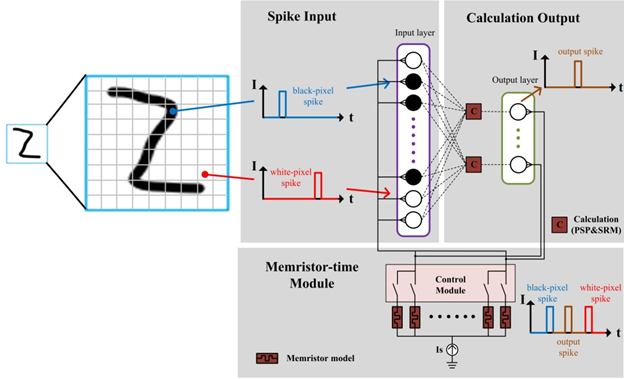
Fig. 1 Hardware design process of total networks
The function of memristor-time module is introduced before, which is mainly to convert the time interval information of pulse into the value of memristor as Fig.2.
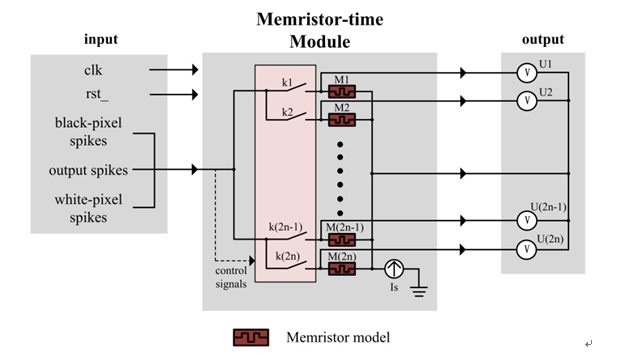
Fig. 2 circuit diagram of memristor-time module
The input to this module is black-pixel spikes, white-pixel spikes and output spikes and these spikes serves as signals for controlling all switches at the same time. The number of classifications in the figure is n, so the number of switches, memristors and outputs are 2n. Since the current is set to 1, we choose to set the output to the voltage across the memristor in order to obtain the value of the memristor conveniently.
The circuit diagram of neuron module which is added the weight sharing mechanism is shown as Fig. 3. The input to this module is clock, reset, spikes encode from training images and weight updating from memristor-time module, for we need to arrange all this process including adding, calculation and output with timing control. The weight updating add to old weight first, and calculate with spikes encode getting output fire. The number of classifications in the figure is also n so that the number of fires is n.
The output of neuron module is the main input of memristor-time module and the output of memristor-time module is the input of neuron module except spikes encode.
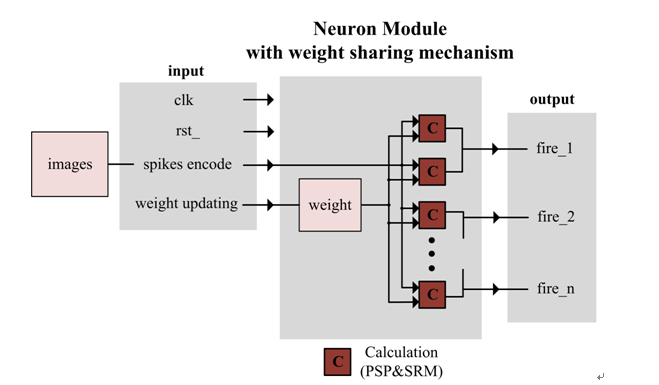 Fig. 3 Circuit diagram of neuron module with weight sharing mechanism
Fig. 3 Circuit diagram of neuron module with weight sharing mechanism
The biggest advantage of the neural network implemented in hardware is that because the hardware parallelism calculation is consistent with the neural network, the processing speed of the neural network on the hardware is much faster than that on the software. Therefore, we mainly analyze maximum clock frequency of different network scale in this section.
After many steps of optimization, the experimental results are as Table1.
Table 1
Maximum clock frequency of different scale network
|
Fmax(MHz) |
9*9*5 |
7*7*5 |
5*5*5 |
7*7*3 |
5*5*3 |
3*3*3 |
|
Stratix V |
247.52 |
243.07 |
256.54 |
248.51 |
250.69 |
270.12 |
As one of the main problems in hardware implementation of neural networks, resource occupancy has always been focused on. In the design used earlier in this paper, the weighted update value was calculated and stored using the memristor-time module. The number of memristors only requires the number of categories multiplied by 2. To a certain extent, the hardware resource occupancy is reduced. In order to further reduce resource occupancy and allow the hardware to accommodate very-large-scale networks, we designed a new weight sharing mechanism.
In Fig. 1, the firing time of the black pulse is the same, so if we set the initial value of the weight corresponding to the black pixel to be the same, the amount of change obtained by the memristor-time module is also the same. Then you can directly set the weights of all black pixels to a single value.
The corresponding weights for the white pixels are also the same. Using the weight sharing mechanism can reduce the number of weights to the number of categories multiplied by 2, as shown in Fig. 4. For instance, if the trained and tested images are 3*3 pixels and the number of categories is 3 (3*3*3 network, for short), then the required weights and the number of updated memristive weights are all six with weight sharing mechanism.
Fig. 4 (a) original MNNs (b) adding weight sharing mechanism
Table 2
Maximum clock frequency of different scale network with weight sharing mechanism
|
Fmax(MHz) |
9*9*5 |
7*7*5 |
5*5*5 |
7*7*3 |
5*5*3 |
3*3*3 |
|
Stratix V |
249.88 |
258.93 |
267.52 |
242.84 |
258.2 |
250.25 |
We hope to verify whether the algorithm can still maintain high recognition accuracy or not with the expansion of the network size. However, due to the complexity of hardware programming, 9*9*5 network are selected for training and testing as follows:
The five categories are Z, V, N, X and C in Fig. 5(a) The Fig. 5(b) and (c) shows the training process of the network. The abscissa is time, and the ordinate is the value weight update, that is, the value of memristor. Five training pictures are input one by one, which is a training cycle. So we can know that one cycle of training is 20us and after three cycles, the value of weight update has dropped to a very small value which indicates the training is over. The entire training period is only 60us. When we add the weight sharing mechanism, black pixels and white pixels respectively correspond to a certain weight. Therefore, the value of weight update calculated for each classification is the same, which can be seen in Fig. 5(c), while the value of weight update calculated for each classification is different in Fig. 5(b). In addition, the adding of weight sharing mechanism have no influence on the training time, that is to say, it can effectively reduce resource occupancy without affecting training efficiency.
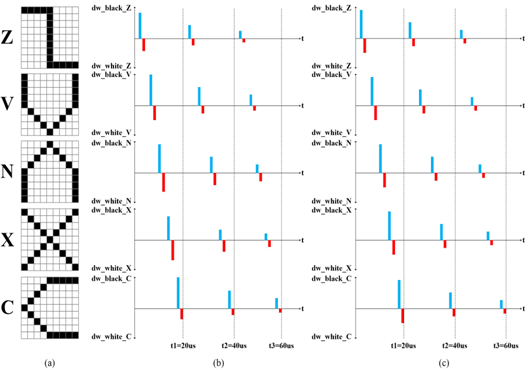
Fig. 5 (a) 9*9*5 network training images (b) change of memristor value in training process without weight share mechanism (c) change of memristor value in training process with weight share mechanism
Table 3
Test results of 9*9*5 networks
|
|
Expectation |
|||||
|
Z |
V |
N |
X |
C |
||
|
Experiment results |
Z |
149 |
0 |
0 |
1 |
0 |
|
V |
0 |
149 |
0 |
0 |
1 |
|
|
N |
1 |
0 |
148 |
0 |
1 |
|
|
X |
0 |
1 |
0 |
149 |
0 |
|
|
C |
0 |
1 |
1 |
0 |
148 |
|
In order to test the optimization of the hardware resource occupancy by this weight sharing mechanism, we selected six different-scale networks from small to large to carry out experiments on FPGA, which are 3*3*3 network, 5*5*3 network, 7*7*3 network, 5*5*5 network, 7*7*5 network and 9*9*5 network. And then we take 3*3*3 network as an example to verify that the resource occupancy on three different hardware platforms is in line with expectations. The two experimental results are as Table 4.
Table 4
Resource occupancy of different network scale on Stratix V
|
Network scale |
Without weight sharing (in ALMs) |
With weight sharing (in ALMs) |
|
3*3*3 |
199 |
122 |
|
5*5*3 |
395 |
214 |
|
7*7*3 |
516 |
237 |
|
5*5*5 |
869 |
428 |
|
7*7*5 |
1309 |
475 |
|
9*9*5 |
1917 |
540 |
It’s clear that the use of weight sharing mechanisms reduces hardware resource occupancy a lot. From the above data growth situation, the relationship between the increase in resource occupancy and the number of categories is greater than the correlation with the number of input neurons. Set the number of input neurons be neuron2(N2) and the number of classifications be type(T). So we set the abscissa to N*T2 and the ordinate to the resource footprint to do the fitting curve as Fig. 6.
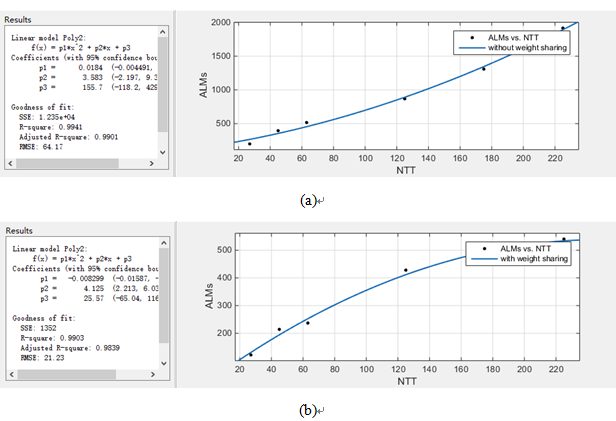
Fig. 6 Resource occupancy growth curve (a) without weight sharing mechanism (b) with weight sharing mechanism
From the fitting curve, we can easily know that such a design can greatly reduce the hardware resource occupancy with the expansion of the network scale. Under the original design, the increase of resource occupancy with the expansion of the network scale is more than a linear increase while the growth rate was less than linear growth with adding the weight sharing mechanism. From the experimental results, it can be seen that this mechanism has great potential when it comes to implementing very-large-scale networks in hardware.