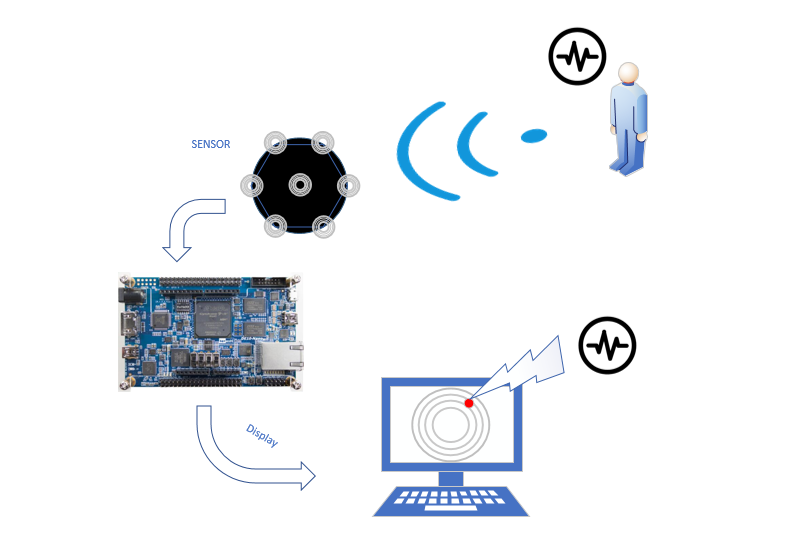
PR044 » 声源目标定位与识别系统
本设计基于FPGA实现了一种声源目标定位与识别系统。系统通过麦克风阵列感知环境声场,随后采用数字背景噪声抑制进一步提高信号的信噪比从而得到低噪声、宽动态范围的声场数据,为了补偿环境因素对测量的影响,系统还通过传感器测量当前环境下的温度和气压,用来调整用于计算的声速,最后采用麦克风阵列定位原理实现声源目标的空间定位,并借助特征提取和模式匹配方法进行声源目标识别。
1、介绍
阵列信号处理是数字信号处理领域的一大热点,基于麦克风阵列的声源定位是声学信号处理的一个重要问题,上个世纪七八十年代,麦克风阵列技术已经开始应用到语音技术的研究中,2000年左右,业界开始慢慢深入,进行麦克风阵列相关算法的专题研究,随后,市场的刺激和产品的需求推动了相关技术的发展,麦克风阵列技术开始在各个领域中得到应用。目前,市场上存在的麦克风阵列产品,主要用于视频会议、语音增强、噪声抑制和远场交互,但是产品价格相对昂贵,且产品应用方向单一,所以使用人数有限。
2、目的
本设计基于麦克风阵列,以FPGA作为控制核心,结合FPGA并行高速运算和配置灵活的特点,实现了一种声源目标定位与识别系统,可以捕获声源目标的位置并进行识别处理。本系统使用灵活,通过进行技术的扩展,可以延伸至其他各个领域的应用。
3、应用领域
声源目标定位与识别系统可用于包括安防、军事、远程视频通信和机器人视觉等。
声源目标定位与识别系统可与摄像头结合形成一套智能安防系统,目前的监控系统一般只由摄像头组成,通过拍摄视频图像进行环境监控,通过麦克风阵列进行语音拾取和目标定位,可以实现三维立体监控。在军事上,可通过声源定位进行目标侦查,实现定点打击。
在远程视频会议中,麦克风阵列通过语音录制和声源识别,协助摄像头定位到发声对象上,实现实时、可视、交互的通讯。
在机器人控制中,麦克风阵列模拟听觉系统,通过声场数据采集与分析,对目标进行定位与识别,弥补了机器人视觉系统的不足,可以极大地提高机器人与外界交互的能力,并完成如目标跟踪,环境识别等功能。
1、系统框图
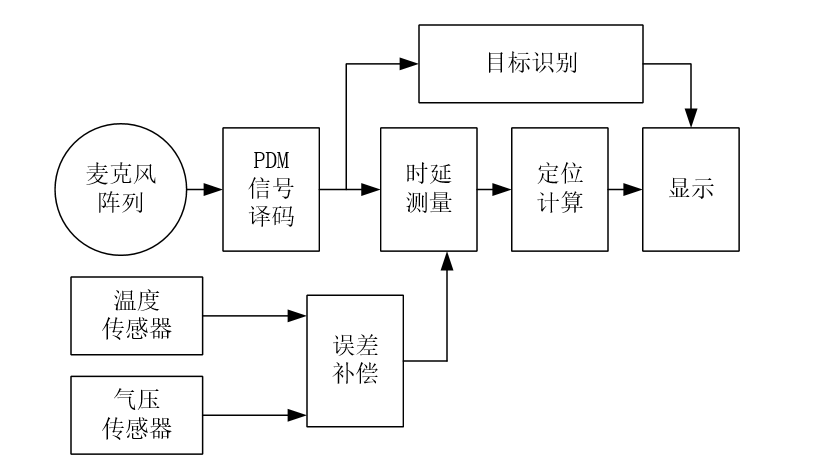
上图为本系统的实现框图,包括麦克风阵列、温度传感器、气压传感器、误差补偿、PDM信号译码、时延测量、定位计算、目标识别和显示模块。
系统通过麦克风阵列感知环境声场,得到的声场数据为经过脉冲密度调制(PDM)的信号,此信号经过PDM信号译码后可得原始声场数据,对原始声场数据进行数字背景噪声抑制,进一步提高信噪比,得到低噪声、宽动态范围的声场数据。
一方面,利用所得声场数据可计算每两个麦克风的声达时延差,温度传感器和气压传感器用于测量当前环境的温度和气压,进而对用于计算的声速进行误差补偿,然后通过声达时延差进行定位计算。
另一方面,利用所得声场数据可通过特征提取和模式匹配方法进行声源目标识别。
最后,将声源目标定位与识别的信息进行显示。
2、麦克风阵列模型图

本系统采用圆周6个麦克风和中心1个麦克风的形式组成环形阵列。
3、定位算法
本系统采用的二维麦克风阵列位均匀圆阵(UCA, Uniform Circle Array)。将6个麦克风等间角度摆放在一个半径位r的圆周上,就组成了均匀圆矩阵。
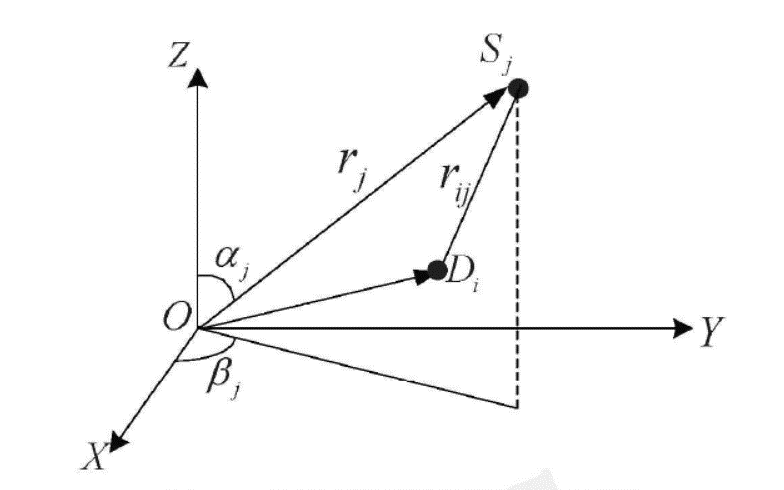
设6个(M=6)阵元均匀分布在以原点位圆心,半径位r的xOy平面上,则阵元坐标为:
可以得到均匀圆矩阵的信号接收模型:

其中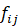 表示第在绝对无噪声 的情况下j个传感器收到的第i个声源发出的声音的频谱,
表示第在绝对无噪声 的情况下j个传感器收到的第i个声源发出的声音的频谱,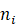 表示第i个传感器收到声音的噪声的频谱。进而可以得到均匀圆阵的波数模式为:
表示第i个传感器收到声音的噪声的频谱。进而可以得到均匀圆阵的波数模式为:
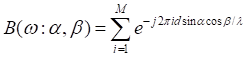
λ是声波波长。
MUSIC算法的实现步骤如下
(1)根据天线各阵元测得的N次快拍数据得到下列协方差矩阵的估计值:
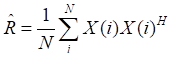
(2)对该协方差矩阵进行特征值分解:
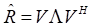
(3)对分解得到的特征值大小进行排序,把与信号个数p相等的特征值所对应的特征向量作为信号的子空间,把剩下的(M-P)个特征值对应的特征向量作为噪声子空间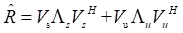 并确定
并确定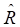 的最小特征值的个数
的最小特征值的个数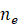 ,利用与最小特征值对应的特征向量构造噪声子空间
,利用与最小特征值对应的特征向量构造噪声子空间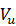 :
:
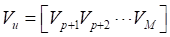
(4)计算空间谱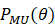 :
:
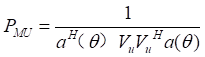
的最大值所对应的θ就是所需要估计的方向。
4、定位计算示意图
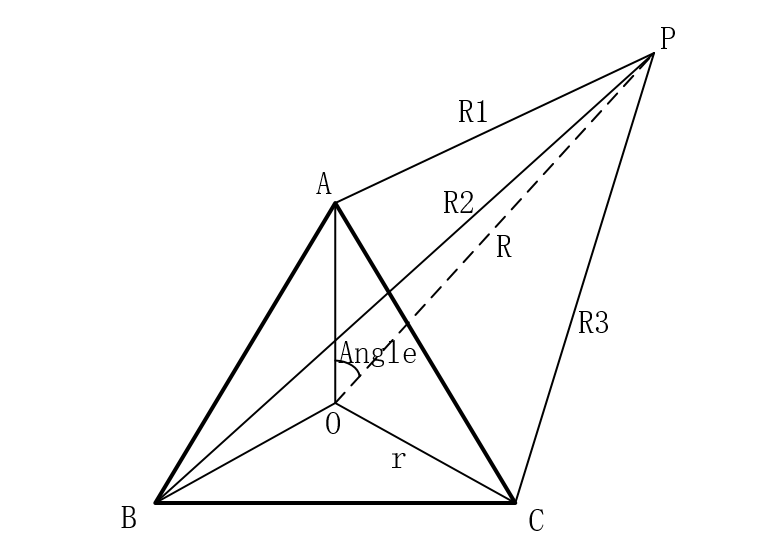
本系统基于空间几何定位的方法进行定位计算。
其中,A、B、C为3个麦克风,成等边三角形排列,O为第4个麦克风,位于圆心位置,P为声源的位置,R1、R2、R3分别为P到A、B、C的距离,R为P到O的距离,r为麦克风A、B、C到O的距离,Angle为PO连线与垂直方向的夹角。此角通过MUSIC算法得到。
1、并行计算
麦克风阵列有多个信号输出,可以充分利用FPGA硬件并行计算的能力,将复杂的算法利用硬件逻辑实现,可以提高运算速度,节省CPU资源。
2、优秀的性能
FPGA具有充足的资源,具有可重构、配置灵活的特点,并且可以利用其扩展性进行系统的延伸应用。例如可以通过配置摄像头实现音视频同步监控,通过探测环境因素(气压、温度等)以适应不同的环境。
1 设计目的
阵列信号处理是数字信号处理领域的一大热点,基于麦克风阵列的声源定位是声学信号处理的一个重要问题,上个世纪七八十年代, 麦克风阵列技术已经开始应用到语音技术的研究中,2000年左右,业界开始慢慢深入,进行麦克风阵列相关算法的专题研究,随后,市场的刺激和产品的需求推动了相关技术的发展,麦克风阵列技术开始在各个领域中得到应用。目前,市场上存在的与麦克风阵列相关的产品,主要应用于视频会议、语音增强、噪声抑制和远场交互等方面,但是产品价格相对昂贵,且应用方向单一,所以使用人数有限。
本文基于麦克风阵列,以FPGA作为控制核心,结合FPGA并行高速运算、配置灵活和IO资源丰富的特点,设计了一种声源定位系统,可用于识别声源的方向,通过后期的技术扩展,可以延伸至各个领域的应用。
2 应用领域
麦克风阵列声源定位系统可用于包括安防、远程视频通信和机器人视觉等领域。
麦克风阵列声源定位系统可与摄像头结合形成一套智能安防系统,目前的监控系统一般只由摄像头组成,通过拍摄视频图像进行环境监控,通过麦克风阵列进行声音拾取和目标定位,可以实现三维立体监控。
在远程视频会议中,麦克风阵列通过声源识别和语音录制,协助摄像头定位到发声对象上,实现实时、可视、交互的通讯。
在机器人控制中,麦克风阵列模拟听觉系统,通过声场数据采集与分析,对目标进行定位,弥补了机器人视觉系统的不足,可以极大地提高机器人与外界交互的能力,并完成如目标跟踪,环境识别等功能。
3 使用Intel FPGA进行设计的原因
本系统需要采集麦克风阵列输出的6路数据率很高的PDM(脉冲密度调制)信号,为了保证定位计算的准确性,需要对数据进行同时处理,且要求计算速度快,从而保证定位的实时性,这是我们选择使用Intel FPGA进行设计的原因,Intel FPGA具有并行高速运算、配置灵活、IO资源丰富、存储容量大和性能强大等优点,能很好地满足本系统的设计要求。
1 系统组成及功能说明

图1 系统流程图
图1所示为本系统的实现流程图,包括麦克风阵列、PDM信号解码模块、定位计算模块和显示定位模块。系统通过麦克风阵列感知环境声场,得到的声场数据为经过脉冲密度调制(PDM)的数据,通过对此数据进行PDM信号解码可以得到原始声场数据,为了提高原始声场数据的信噪比,扩展其动态范围,在进行定位计算之前,需要对数据进行数字信号处理操作,最后进行目标位置的计算,定位显示采用LED阵列进行模拟。整个系统的数据处理部分在Intel FPGA上实现。
2 核心模块介绍
2.1 麦克风阵列
麦克风阵列是指由若干麦克风按照一定的方式布置在空间不同位置上组成的阵列。麦克风阵列具有很强的空间选择性,在不移动麦克风的情况下也可以获得声源信号。
麦克风阵列的排列方式一般包括线形、环形和球形。线形排列的麦克风阵列多用于检测远场(指说话人距离麦克风很远)的情况下,此时可认为人说话的波形为平面波,平面波到达每个麦克风与阵列直线的夹角可认为是相等的,这时可利用声音信号到达每个麦克风的时延差计算出声源的位置和距离;球型的麦克风阵列需要的麦克风数量更多,相应的成本更高,结构更复杂,一般用于三维立体的声源定位;考虑到成本和系统的复杂度,本系统采用平面环形的麦克风阵列,实现二维平面下的声源定位。
原则上,采用3个麦克风组成的环形阵列就可实现360度的位置测量,为了提高定位的精度和准确性,本系统采用6个麦克风组成均匀分布的环形阵列,环形阵列的半径为4.5厘米。 图2所示为本系统的麦克风阵列:

图2 麦克风阵列
如图3所示为本系统使用的Knowles公司生产的MEMS(微机电系统)麦克风SPH1668LM4H-1,SPH1668LM4H-1是一种PDM数字输出的微型声音传感器,声音采集的频率范围为100Hz-10kHz,灵敏度达-29dB±1dB,理论上采集的声场数据信噪比可达65.5dB,满足本系统实现近距离声源定位的要求。为了保证数据的准确性和稳定性,降低电路噪声对声场数据的影响,麦克风阵列PCB板上对每一个麦克风都做了去耦处理。

图3 麦克风SPH1668LM4H-1
2.2 PDM信号解码模块
MEMS麦克风PH1668LM4H-1内部集成了射频放大器和sigma-delta调制器,采集到的声场数据经过了64倍的过采样和量化操作,输出为高速率的1bit数据流,所以需要对其进行解码处理,还原得到原始声场数据。具体操作可分为三步:第一步使用 CIC(Cascade Integrator Comb)滤波器,实现16倍的数据抽取;第二步使用补偿滤波器,实现前级衰减的补偿和2倍的降采样;第三步使用半带滤波器,实现2倍的降采样。
公式(1)为CIC滤波器系统函数:
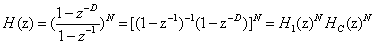 (1)
(1)
由公式可知,CIC滤波器是每输入D个采样值后求一次平均值,经过一个D次降采样器,将平均值输出。其中D为CIC滤波器的阶数,即抽取倍数,N为积分和梳状滤波器级联的级数。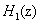 为积分器部分,
为积分器部分,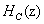 为梳状滤波器部分。在本系统中,具体设置D和N的值分别为16和5,经MATLAB仿真验证其可行性后,调用FPGA中的IP核可以进行具体的设计。
为梳状滤波器部分。在本系统中,具体设置D和N的值分别为16和5,经MATLAB仿真验证其可行性后,调用FPGA中的IP核可以进行具体的设计。
补偿滤波器和半带滤波器可以通过使用MATLAB的fdatool工具中的“Inverse Sinc Lowpass”和“Halfband Lowpass”低通滤波器进行设计,在FPGA根据MATLAB生成滤波器的参数进行具体的滤波器设计。
通过以上三步操作后,可以从2.4MHz(初始时钟频率决定)的PDM数据流得到64倍降采样后37.5kHz的数据流,37.5kHz即为声音信号的奈奎斯特采样频率。
2.3 数字信号处理模块
解码后得到的声音数据具有很大的直流分量,而且频谱的范围很宽,为了提高信号的信噪比,扩展其动态范围,需要在定位计算前进行预处理。
麦克风SPH1668LM4H-1采集声音信号的频率范围为100Hz-10kHz,而在这一范围之外的频率信息可以认为是解码、电路噪声或周围环境的电磁干扰产生的,本系统采用数字椭圆低通和椭圆高通滤波器级联的方式对信号进行滤波,设置截止频率分别为100Hz和8000Hz,经过测试,滤波器的性能良好,可以实现带外噪声的去除。
为了进一步提高信号的信噪比,在滤波后还需对其进行加窗处理。
2.4 定位计算
本系统使用MUSIC算法进行目标声源的定位计算。
MUSIC算法是多信号分类算法(Multiple Signal Classification)的简称,基本思想是将任意矩阵输出数据的协方差矩阵进行特征值分解,从而得到与信号分量相对应的信号子空间和与信号分量正交的噪声子空间,然后利用这两个子空间的正交性来估计信号的方向。具体实现步骤如下:
首先,计算协方差矩阵的估计值,如公式(2)所示:
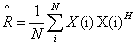 (2)
(2)
然后,对协方差矩阵进行特征值分解,如公式(3)所示:
(3)
接着,对分解得到的特征值大小进行排序,把与信号个数p相等的特征向量为信号子空间,把剩下个数为(M-p)的特征值对应的特征向量作为噪声子空间,构造噪声子空间,如公式(4)所示:
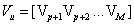 (4)
(4)
最后,计算空间谱,如公式(5)所示:
 (5)
(5)
进行360度谱峰搜索,使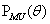 有最大值对应的
有最大值对应的 则为声源的估计方向。
则为声源的估计方向。
1 实验结果
按照一开始设计的方案,我们计划实现目标声源的定位,包括方向和距离,但是由于在声音的时延测量上我们遇到了一些问题,不能得到有效解决,导致距离的计算存在较大的误差,所以目前我们只完成了声源对于方向上的检测。
经过多次实验,我们发现对于声音信号方向上定位的准确率较高,偶尔会出现定位出错的情况,我们猜测这是因为在测试环境中存在回声以及其他的干扰的影响。
2 改进方向

图1 作品实物图
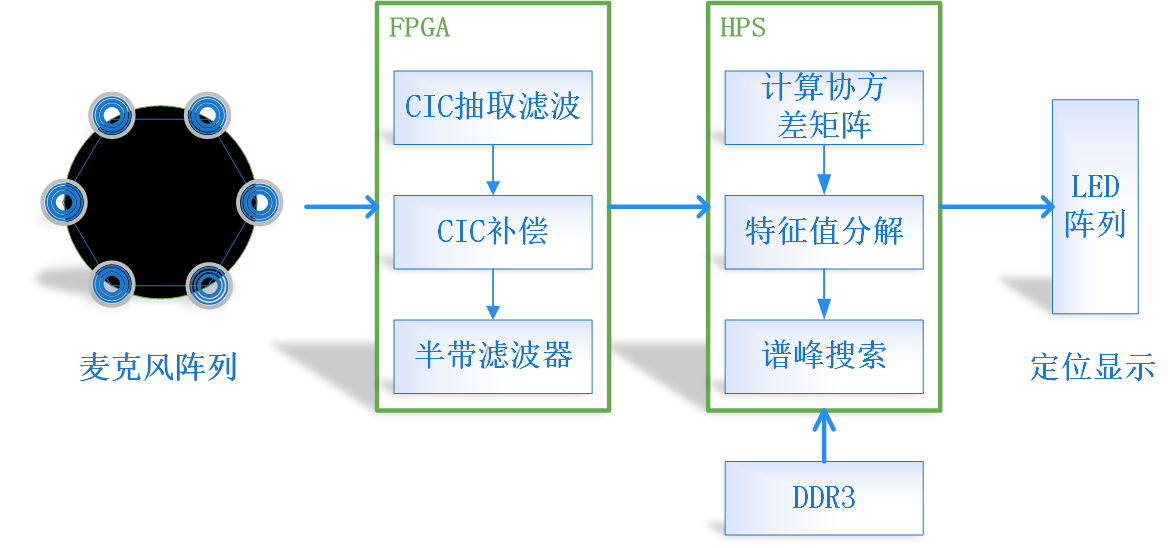
图2 系统结构图
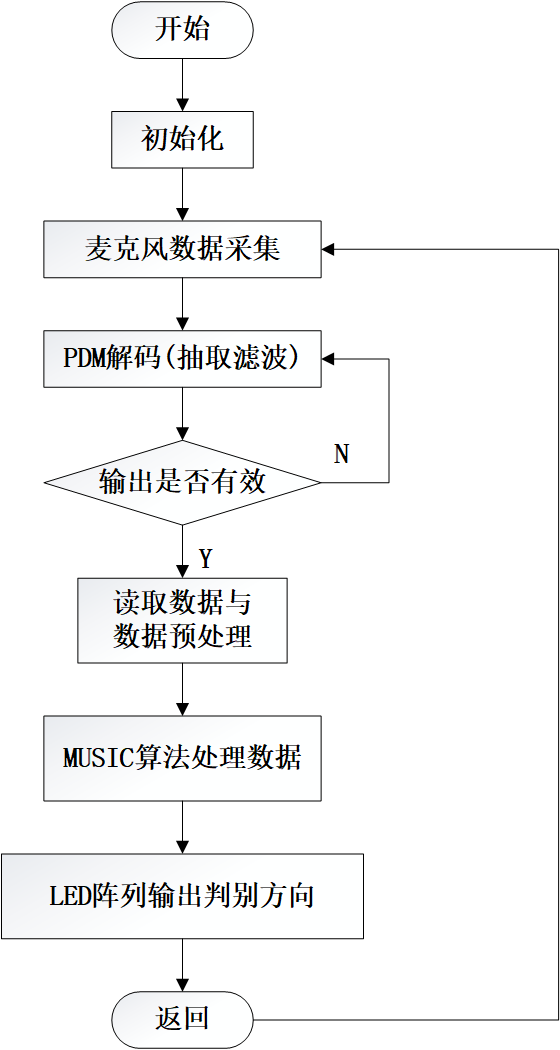
图3 系统流程图
