
PR061 » 基于深度学习的眼科疾病诊断系统
人工智能与眼科结合产生的疾病诊断平台,通过智能阅片,准确、及时地得出诊断结果,将有效协助医生的诊断,提高诊断效率。目前卷积神经网络广泛应用在图像识别领域,而FPGA具有并行计算和低功耗的特点,因此被广泛应用于卷积神经网络的硬件加速。我们采用摄像头采集眼部图片,在DE10-Nano平台上利用卷积神经网络进行计算,最终得到眼科疾病的诊断结果。另外,未来手持眼底检查设备的应用将大大加快该系统的使用。
介绍
先天性白内障会导致失明和视力损伤,在中国的发病率为0.05%。作为一种典型的罕见病,先天性白内障容易出现漏诊或误诊,因此我们选取先天性白内障疾病作为研究对象,将人工智能引入先天性白内障的诊断,以帮助医生减少诊断失误,提高效率。卷积神经网络的提出基于动物视觉神经的研究和发现,它使用多层的神经网络互联来处理数据,并且取得了极高的图像识别率。正是由于卷积神经网络特殊的结构,通用的处理器CPU 在卷积神经网络的计算方面并不高效,经常不能满足运算速度的需求。所以许多种类的卷积神经网络加速方案被提出,有基于通用图形处理器(GPU)、可编程门阵列(FPGA)甚至 ASIC 芯片的设计。在这些提案中,基于 FPGA 的加速器最为引人瞩目,因为 FPGA 具有极高的处理性能、灵活性以及低能耗的特点。卷积神经网络使用前向传播作为识别手段,反向传导作为学习手段。在应用领域,许多设计者直接使用训练完成的网络作为实时处理的工具。所以对于这些应用,前向传播的处理速度尤为关键。大部分基于硬件的卷积神经网络都是研究如何加快前向传导的计算速度、加大吞吐量等性能指标。因此我们采用基于Intel OpenCL FPGA硬件加速的卷积神经网络架构,用高质量的图片样本对其进行训练,最终建立一个具备先天性白内障诊断功能的系统。
目的
通过利用基于Intel OpenCL FPGA硬件加速的卷积神经网络,我们可以帮助医生分析和诊断眼科疾病,减少误诊率,提高诊断效率,更好地造福人类。
目标用户
医院,个人家庭,特别是医疗不发达的偏远地区。
系统框架图
SD Card中包含:
CNN Parameter :离线训练的CNN模型参数文件
Preloader
BootLoader
soc_system.rbf
系统工作原理:
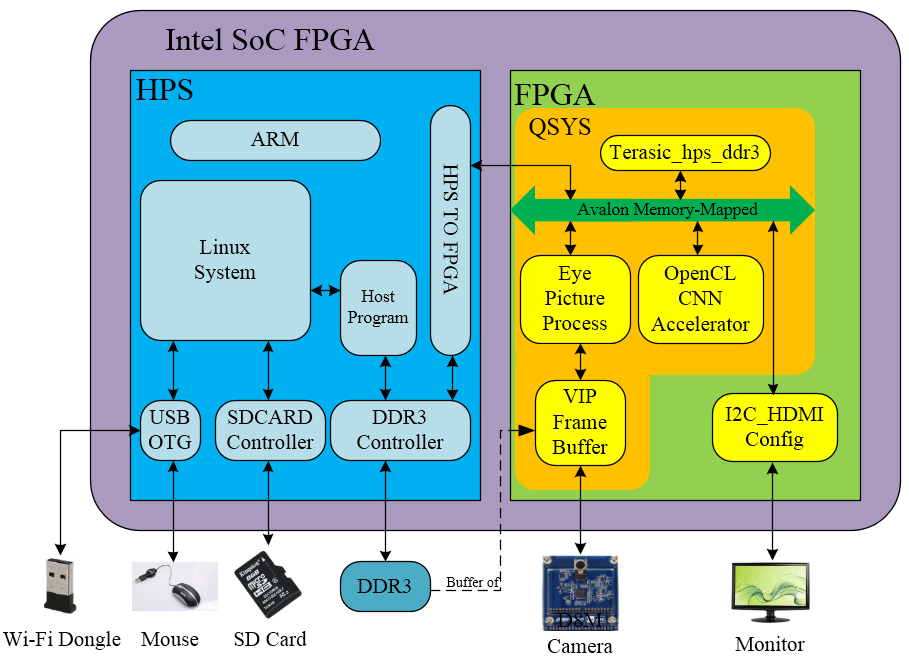
在HPS区域,Preloader,Bootloader和soc_system.rbf程序从SD卡载入,并被执行用来初始化HPS和DDR3内存。Bootloader将会点亮HPS LED,用来表示DDR3已经就绪,然后即可运行soc_system.rbf来配置FPGA。DDR3主要用来缓存CNN模型参数以及CNN运算的中间结果。Wi-Fi Dongle可以将系统接入互联网。
在FPGA区域,利用QSYS集成开发工具连接IP和子系统,自动生成互连逻辑,减轻了FPGA设计工作量。由友晶科技提供的terasic_hps_ddr3是一个子系统,它是FPGA和HPS DDR3之间进行通信的桥梁。HPS DDR3被用作VIP Frame Buffer II的缓冲器。帧缓冲数据通过FPGA-to-HPS接口和SDRAM Controller送达DDR3。FPGA-to-HPS接口是一个128比特的Avalon双向存储器映射端口。Eye Picture Process模块包含眼部拍照,眼球定位,图像增强等功能。
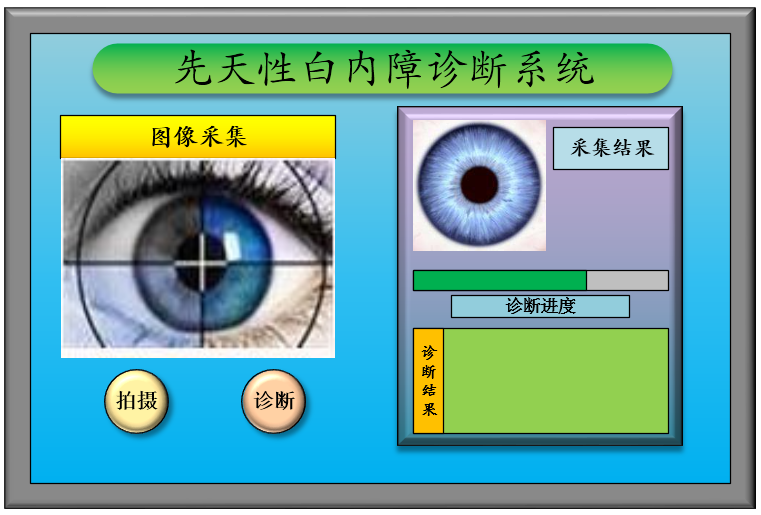
在人机交互界面中显示摄像头拍摄到的患者眼部的视频,用户可以看到眼部图像的最佳效果,校准位置之后点击鼠标即可拍摄到合适的眼部图片,将图片送入基于OpenCL的卷积神经网络进行运算,最终将得到的诊断结果显示出来。人机交互界面如下图所示:
卷积神经网络框架图:
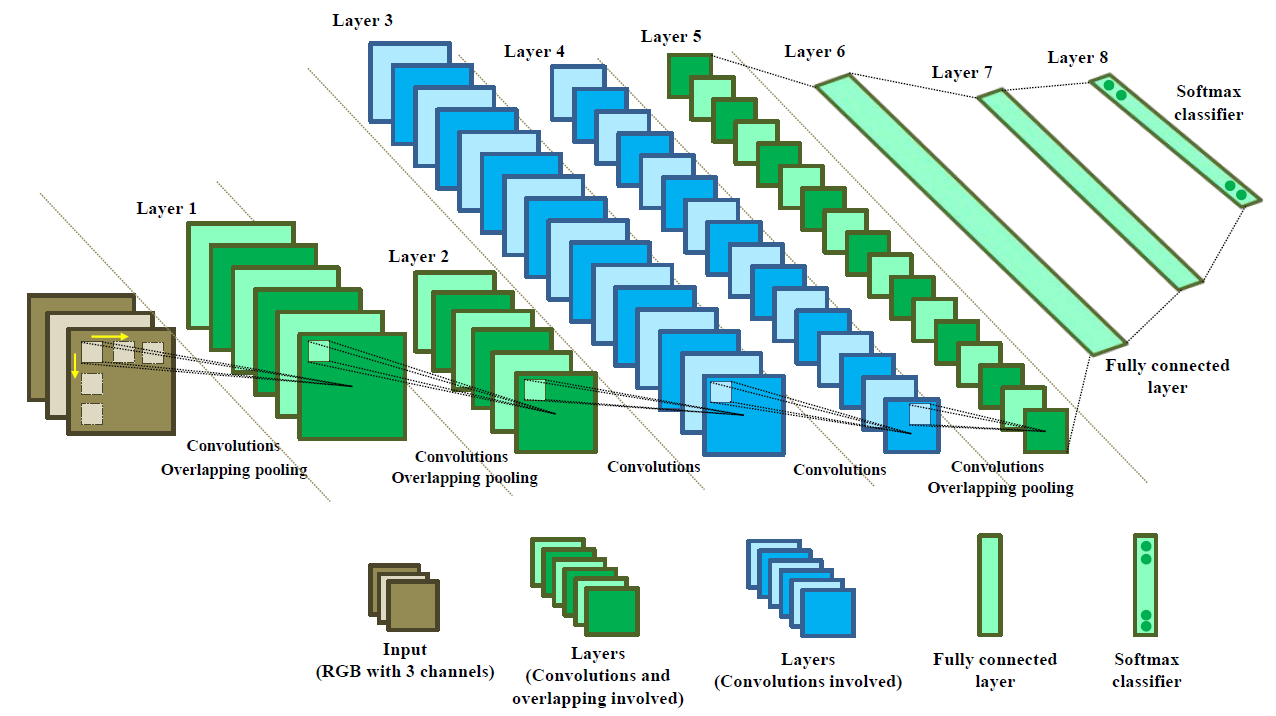
图像的灰度值通过RGB三个通道作为输入;网络包含五个卷积层和三个重叠池化层,其中绿色的层次表示该层中同时包含卷积和池化,蓝色的层次表示该层只包含卷积;最后是三个全连接层;Softmax分类器对最后一层进行分类。
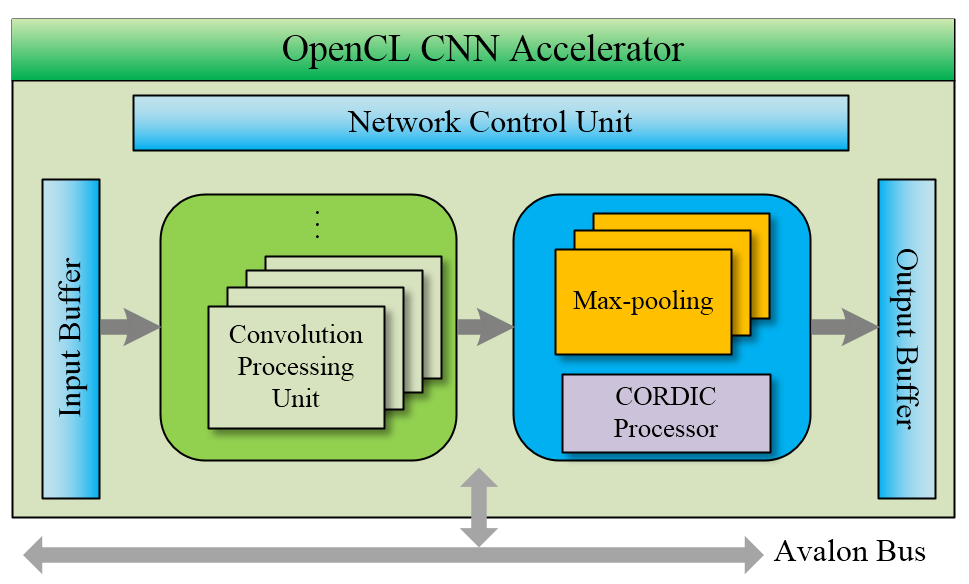
受限于DE10-Nano逻辑资源,我们的深度学习训练采用离线训练方式,在计算机上进行训练,DE10-Nano直接读取训练后的模型参数,单纯地使用FPGA硬件是无法满足这个设计需求的,所以我们采用软件和硬件结合的形式。 HPS ARM软件端完成卷积神经网络的搭建,包括系统界面、鼠标、网络结构的设计。FPGA硬件端采用OpenCL完成前向传播运算,主要包括 :卷积运算、池化采样、激活函数计算和Softmax分类回归设计。
OpenCL CNN Accerelator:
USB Wi-Fi Dongle:
USB Wi-Fi Dongle系统如下图所示:
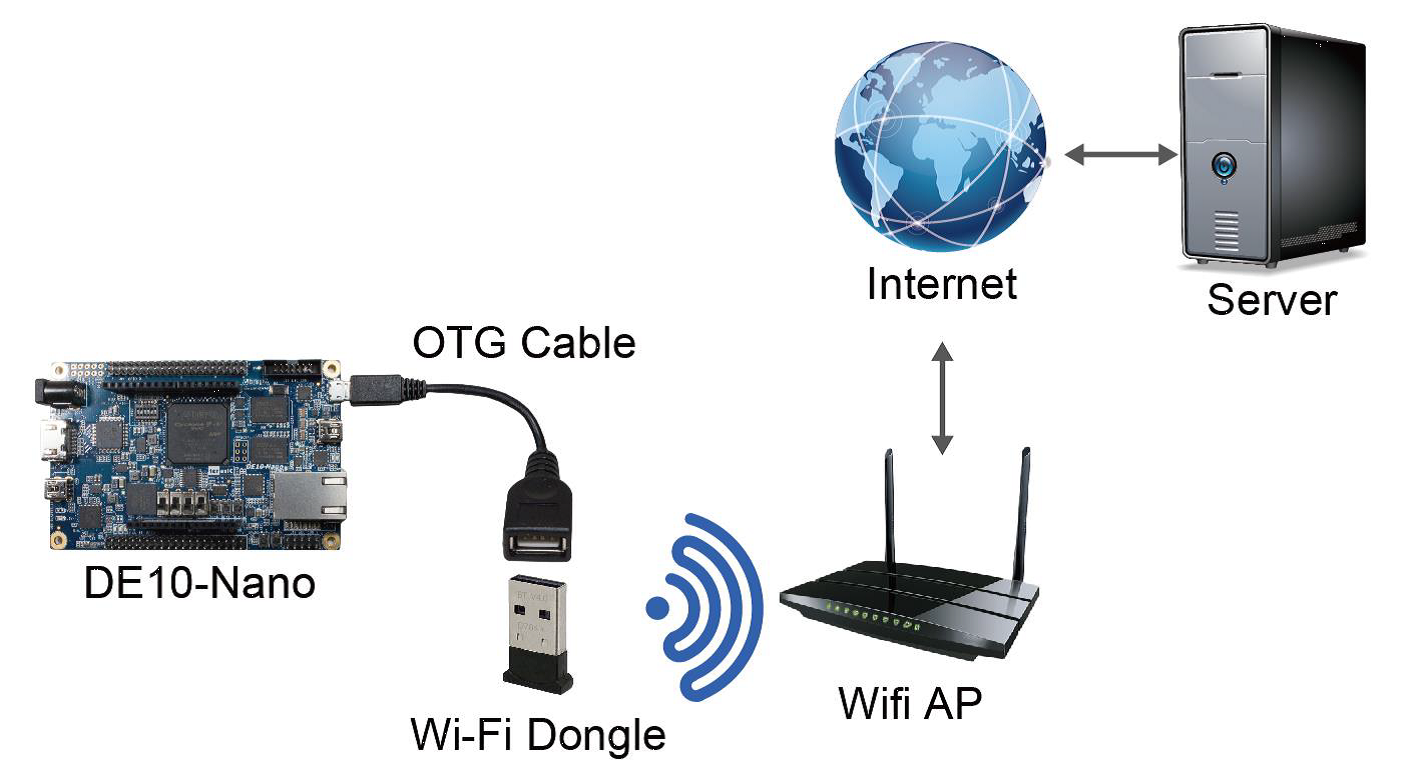
Wi-Fi AP含有DHCP服务器功能,并且已经接入局域网或因特网。USB Wi-Fi Dongle连接到Wi-Fi AP,且被分配了IP地址。通过Wi-Fi AP,USB Wi-Fi Dongle可以和连接到局域网或因特网的设备进行交互。
DE10-Nano开发板功能区块图:
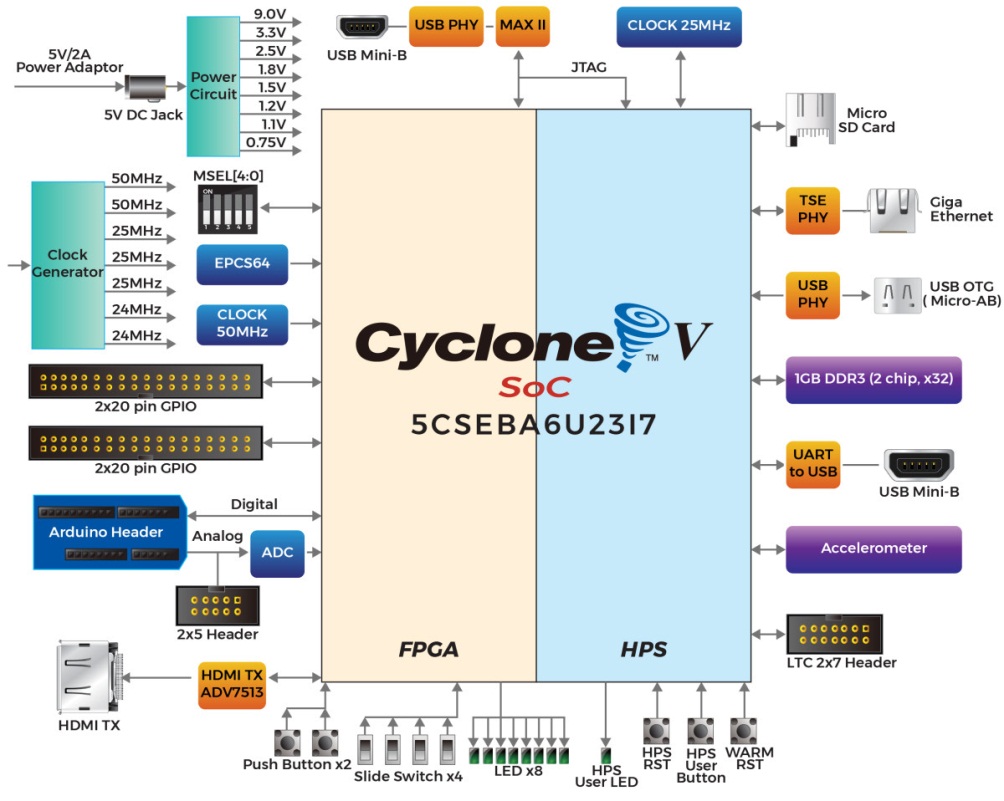
硬件:
FPGA提供了大量的设计资源,具有可重构的特点,能够灵活配置。FPGA具有比CPU、GPU更高的能效。并行计算的特点使得FPGA在每个时钟周期内能完成更多的处理任务,可以很好地实现卷积神经网络加速。Intel的SoC系统结合了以ARM为主的HPS架构处理器,周边及内存接口与使用高带宽互联骨干结构的FPGA无缝接合。DE10-Nano开发板同时也配备了高速的DDR3内存、模拟数字功能、以太网络等应用功能。
软件:
OpenCL 标准是首个开放式、免费许可的统一编程模型,能够在异构系统上加快算法速度。OpenCL 支持在不同的平台上使用基于 C 语言的编程语言开发代码,例如 CPU、GPU 及 FPGA。OpenCL 的主要优势在于它是一个可移植、开放式、免费许可的标准,这是它与专用编程模型相比的一个关键优势。
Intel 是OpenCL规范的第一家FPGA公司。面向OpenCL的Intel FPGA SDK支持各种主CPU,包括SoC器件中的嵌入式ARM Cortex-A9处理器内核。
Intel Opencl FPGA SDK主要特性:
Microsoft* Visual Studio 或基于 Eclipse 的面向 OpenCL API 的英特尔代码构建工具(现在支持 FPGA)
采用英特尔编译器技术的快速 FPGA 模拟
创建 OpenCL 项目快速启动向导
语法突显和代码自动完成特性
假设内核性能分析
快速静态 FPGA 资源和性能分析
支持快速和增量 FPGA 编译
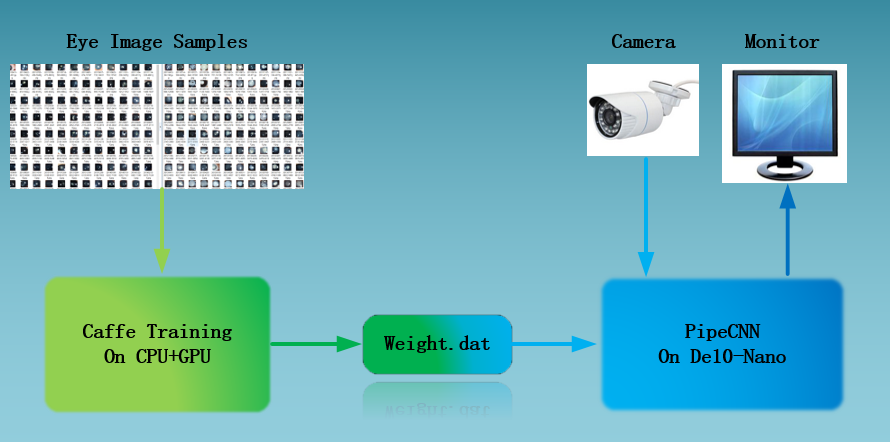
The diagnosis system of Ophthalmology based on deep learning uses a convolutional neural network on the basis of Intel OpenCL FPGA hardware acceleration as the forward operation framework. We have done the system on De10-Nano development board. It combines the high quality picture samples of congenital cataract with Caffe to trains the AlexNet deep learning model and replaces the trained weight files to the convolution neural network. The eye samples were collected through the camera and sent into the neural network to make binary classification results. Finally, a system with congenital cataract diagnosis function was established.
This project is mainly done in OpenCL and C++, where all the kernels are written in OpenCL and host code running on the ARM in C++. The Altera OpenCL SDK allows a programmer to use high level code to generate an FPGA design with low-power consumption and good performance. Alrera’s AOCL compiler is used to compile the Kernel code to FPGA design and automatically generates System Verilog code for the developer.
By using the convolution neural network based on Intel OpenCL FPGA hardware acceleration, we can help doctors to analyze and diagnose ophthalmological diseases, reduce the rate of misdiagnosis, improve the efficiency of diagnosis, and benefit human better. Our target user are hospitals as well as individual families, especially in remote areas where health care is not developed.
The realization of the whole system can be divided into four main aspects: the transplantation to the De10-Nano of the forward network, the training of network parameters, the collection of image samples and sample image enhancement and denoising.
Forward Network
The convolution neural network modifies the network structure of the open source engineering PipeCNN: An OpenCL-Based Open-Source FPGA Accelerator for Convolution Neural Networks, in order to fully adapt to the training results of AlexNet based on Caffe, improve accuracy as well as reduce the accuracy loss caused by fixed-point neural network. The convolution neural network based on OpenCL is partly generated by kernel file configuration on FPGA. There are two main advantages. The cascaded kernels form a deep pipeline, which can execute a serial of basic CNN operations without the need of storing interlayer data back to external memory. It significantly relieves the demand on memory bandwidth which is essential for embedded FPGAs. The area of FPGA uses a single hardware kernel to implement both the convolution and FC layers which further improves the efficiency of hardware resource utilizations. The top level of architecture is shown in Figure.1.
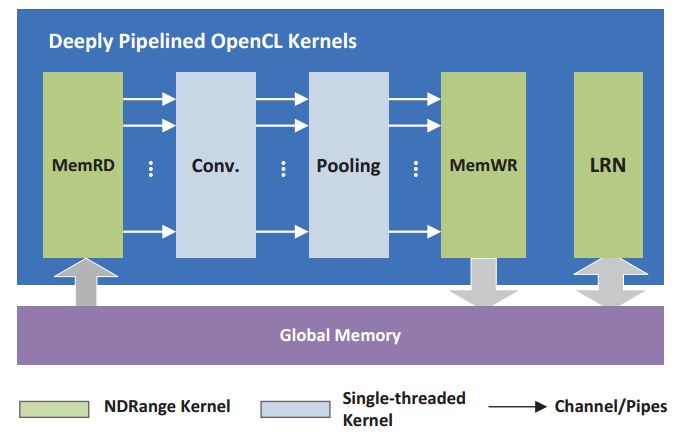
Figure.1 The top level architecture of PipeCNN
PipeCNN is a convolutional neural network based on OpenCL. It uses the AlexNet architecture. The host program runs on CPU, and the convolution operation, pool sampling and memory reading and writing of the convolution neural network are accelerated through FPGA. The structure of the AlexNet convolution neural network model is shown in Figure.2. We do some modification to the architecture of PipeCNN by changing the last 1024 outputs to 2, and retraining for the diagnosis of eye diseases.
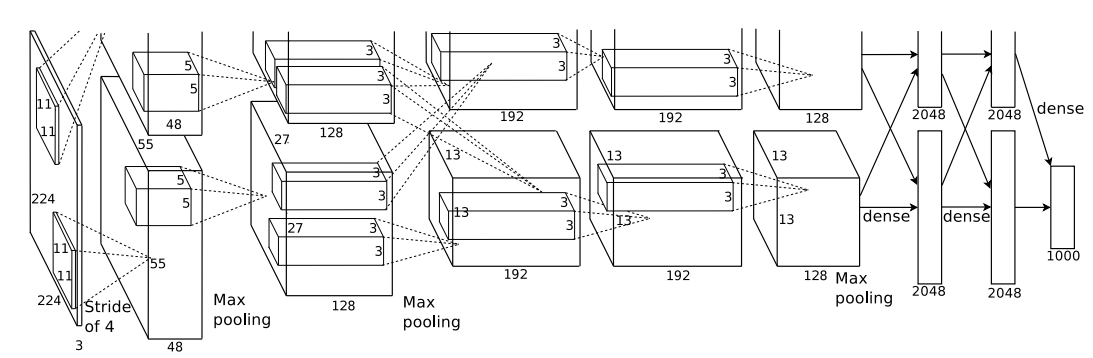
Figure.2 AlexNet neural network model
Network parameter training
Data collection and labeling before agent training.
The training data set, which included 410 ocular images of CC of varying severity and 476 images of normal eyes from children, was derived from routine examinations conducted as part of the CCPMOH, one of the largest pilot specialized care centers for rare diseases in China. Images covering the valid lens area were eligible for training. There were no specific requirements for imaging pixels or equipment. Each image was independently described and labeled by two experienced ophthalmologists, and a third ophthalmologist was consulted in the case of disagreement. The expert panel was blind and had no access to the deep-learning predictions. The identification networks involved two-category screening to distinguish between normal eyes and those with cataracts. There were no agreed-upon gold-standard criteria for CC assessment due to the complexity of the morphology of opacity. For pre-processing, auto-cutting was employed to minimize noise around the lens, and auto-transformation was conducted to save the image at a size of 256 × 256 pixels.
Figure.3 Eye image samples
Deep learning convolutional neural network.
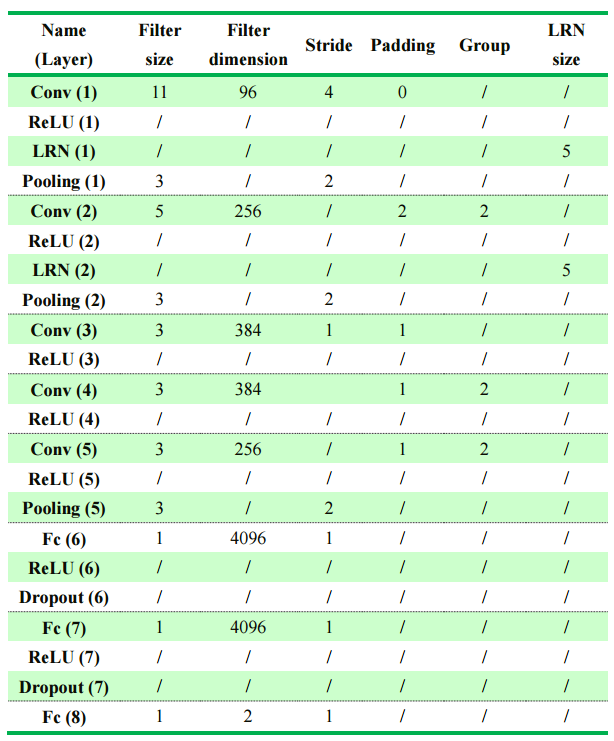
A deep convolutional neural network, AlexNet, derived from the championship model from the ImageNet Large Scale Visual Recognition Challenge of 2012 (ILSVRC2012), which is considered to dominate the field of image recognition, was used for training and classification. This model contained five convolutional or down-sample layers in addition to three fully connected layers, which have been demonstrated to show adaptability to various types of data. The first seven layers were used to extract 4,096 features from the input data, and Softmax classifier, was applied to the last layers. Specifically, several techniques, including convolution, overlapping pooling, local response normalization, a rectified linear unit and stochastic gradient descent, were also integrated into this algorithm. Dropout methods were used in the fully connected layers to reduce the effect of overfitting. A summary of the detailed parameters of each layer is presented in Table.1. All codes employed in the study were executed in the Caffe (Convolutional Architecture for Fast Feature Embedding) framework with Ubuntu 16.04 64bit + CUDA (Compute Unified Device Architecture) 8.0.
Table.1 Summary for the detailed parameters of each layer
From the following diagrams, we can see that with the increase of iterated algebra, the error between training results and real results will quickly converge. The test step is 1000 iterations, and the accuracy of the test is eighty-five percent.
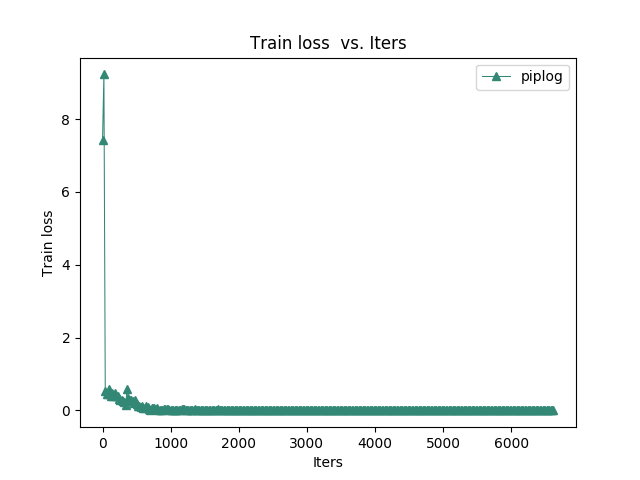
Figure.4 Train loss vs. iters
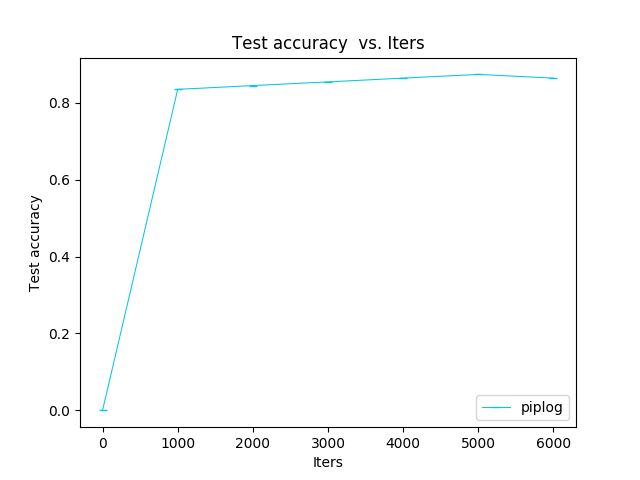
Figure.5 Test loss vs. iters
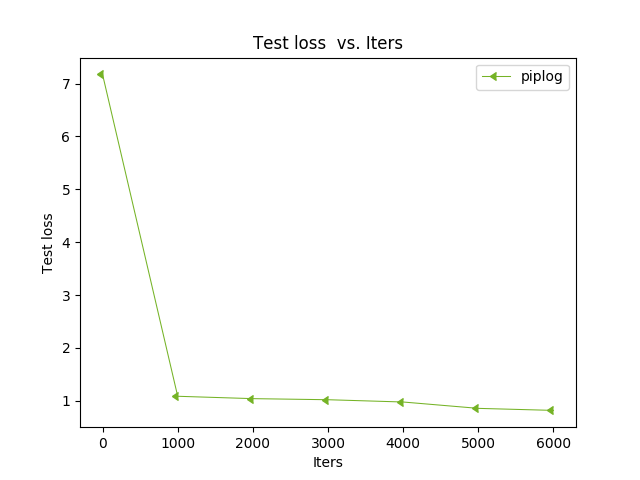
Figure.6 Test loss vs. iters
Prepare the CNN models
As training finished, use matlab script to extract the CNN model. Quantize the exacted mode to fixed-point weight and bias. The word lengths and fractional bit length and set according to the Table2. The weights are quantized with 8-bit precisions presented as N*2^-m, where N Is a fixed-point integer with n-bit word length, and m denotes the fractional bits of the quantized weight. The pair of integers (n,m) are the quantization parameters in Table.2.
Table.2 AlexNet weights’ quantization
|
Layer Name |
Input |
Output |
Weight |
|
Conv1 |
8,0 |
8,-4 |
8,8 |
|
Relu1 |
8,-4 |
8,-4 |
|
|
Lrn1 |
8,-4 |
8,0 |
|
|
Pool1 |
8,0 |
8,0 |
|
|
Conv2 |
8,0 |
8,-2 |
8,8 |
|
Relu2 |
8,-2 |
8,-2 |
|
|
Lrn2 |
8,-2 |
8,0 |
|
|
Pool2 |
8,0 |
8,0 |
|
|
Conv3 |
8,0 |
8,-1 |
8,8 |
|
Relu3 |
8,-1 |
8,-1 |
|
|
Conv4 |
8,-1 |
8,-1 |
8,8 |
|
Relu4 |
8,-1 |
8,-1 |
|
|
Conv5 |
8,-1 |
8,-1 |
8,8 |
|
Relu5 |
8,-1 |
8,-1 |
|
|
Pool5 |
8,-1 |
8,-1 |
|
|
Fc6 |
8,-1 |
8,0 |
8,11 |
|
Relu6 |
8,0 |
8,0 |
|
|
Drop6 |
8,0 |
8,0 |
|
|
Fc7 |
8,0 |
8,2 |
8,10 |
|
Relu7 |
8,2 |
8,2 |
|
|
Drop7 |
8,2 |
8,2 |
|
|
Fc8 |
8,2 |
8,2 |
8,10 |
Eye Image Sampling
The collection process of the picture includes calling the camera, taking pictures and displaying picture data. The program is written in the C++ language based on OpenCV. The picture collected by the camera is a file format of three channels and 5 million pixels. In the program, the scale of the picture is reformed, and the three channels are split and then signed. Finally, the three channels are merged as a whole, and they are written into symbolic 8BIT files and put into the corresponding directory. The file size is 227*227*3Byte, which satisfies the input needs of AlexNet neural network.
Image enhancement and denoising
Using the 8 neighborhood Laplasse operator with a center of 5, convolution with the image can achieve sharpening the purpose of enhancing the image. Laplasse operator can enhance local image contrast.
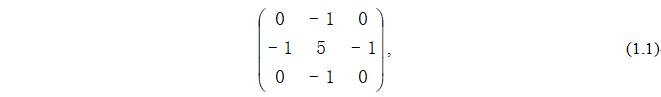
Hardware
The hardware mainly includes Logitech C310 camera, De10-Nano development platform and AOC display.
Logitech C310 camera: 5 million pixels, maximum resolution of 1280x720, no drive, USB2.0 interface, photosensitive element CMOS, participate in sample collection function.
De10-Nano development platform: the HPS part runs the host program and the sample collection program. The FPGA part accelerates the convolution operation, pool sampling and memory reading and writing of the convolutional neural network.
AOC display: real-time display of photo taking process, showing desktop system as well as photo results.
Software
The software includes host program and Linux image.
Host program: First part achieves camera video acquisition, enhances eye photo and completes image sample collection and image format conversion. In the program, the scale of the picture is reformed, and the three channels are split and then signed. Finally, the three channels are merged as a whole, and they are written into symbolic 8BIT files and put into the corresponding directory. The file size is 227*227*3Byte, which satisfies the input needs of AlexNet neural network. The second part realizes the main structure and data scheduling of the convolutional neural network AlexNet, including five convolution layers and three fully connected layers, and finally the Softmax output is 2 classes, making the normal or abnormal judgment of the picture sample.
Linux image-c5soc_opencl_lxde_all_in_one_180317.img: support opencv3.1, opencl 16.1 and 17.1 as well as LXDE desktop environment.

Figure.7 The whole system
Selected target board:
de10_nano_sharedonly_hdmi
OpenCL version:
aocl 17.1.0.590 (Intel(R) FPGA SDK for OpenCL(TM), Version 17.1.0 Build 590, Copyright (C) 2017 Intel Corporation)
Table.3 Estimated Resource Usage Summary
|
Resource |
Usage |
|
Logic utilization ALUTs Dedicated logic registers Memory blocks DSP blocks |
90% 59% 37% 97% 31% |
Average time for processing an image:
0.186s
camera resolution:
640 * 480
Accuracy of CNN:
92.45%
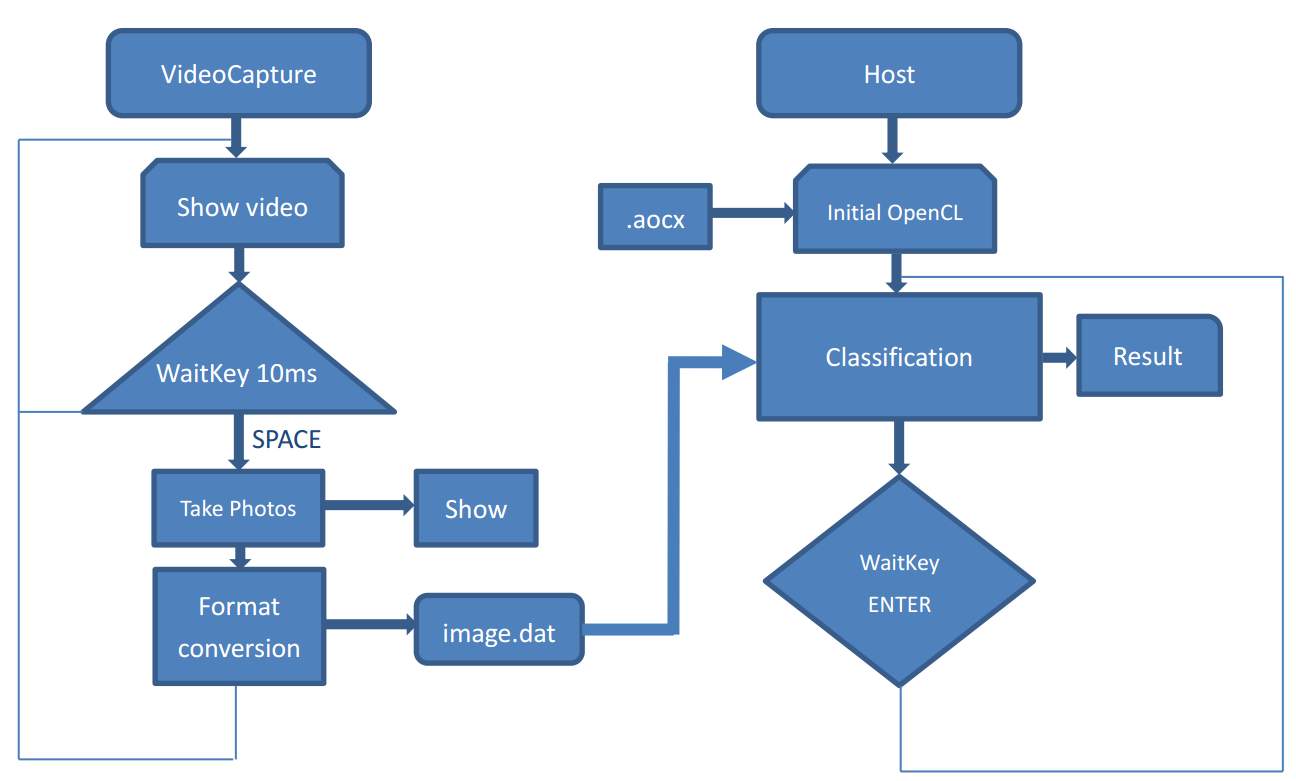
Figure.8 Software flow
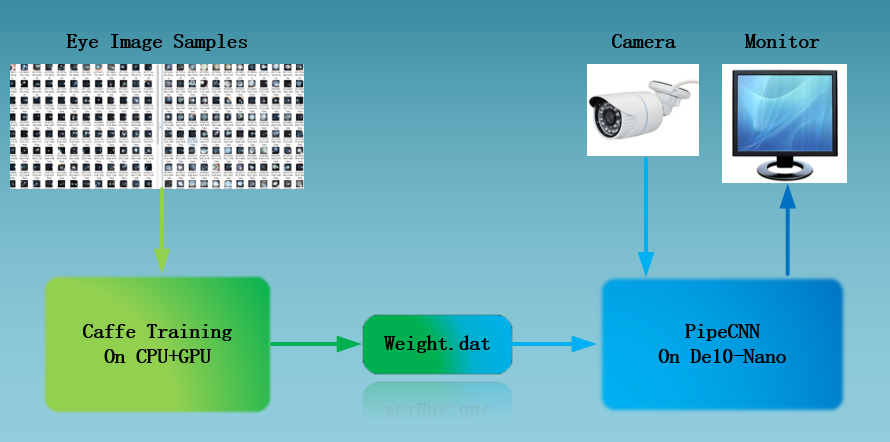
Figure.9 Hardware design