

AS031 » BreXting : Brain Texting
This system records the brain activity, predicts the character that the user is thinking and prints it on a screen in real time. So, all the user has to do it is think what they want to type and voila! It is on the screen.
The interaction between humans and computers have changed a lot over the course of time. It started form simple keyboards, to mouse, touch screen and finally gesture recognition. Alongside, rapid advancements in machine learning has opened plethora of possibilities in every field. Through this project we plan to build a system using machine learning predicting techniques, which will make it possible to text just by thinking.
The human brain is a power house of computation. It is a complex system which emits minute radiations. Neuroscientists have been able to record and classify these signals albeit with limited success. Nevertheless, neuromapping systems are advanced enough to observe certain signals emitted from the brain. An custom built EEG cap is used to record the brain waves. It has 14 on board sensors which records the brain waves and transmits the raw EEG signals serially using Bluetooth. An Arduino connected to a Bluetooth receiver (HC - 05), receives the data. This data is arranged in packets by the Arduino and transferred to the INTEL DE-10 FPGA. The EEG data is processed in the FPGA. The need for an FPGA arises as the data needs to be converted and processed in frequency domain an that too in real time. Also, training of Convolution Neural Networks is a computation heavy process. Since FPGA devices offer the unique advantage of parallelism, the data can be processed in almost real time. There are various current implementations of such Brain Computer Interfaces. But, most of it is confined to laboratory environments requiring high power GPUs. As this system comprises of only an EEG cap, FPGA and microcontroller it is standalone and portable. With Elon Musk’s neuralink aiming to link human brains to computers and aid people with brain injuries, the race for building advanced low-power mobile brain-computer interfaces (BCI) is gaining steam.
We aim to use Electroencephalography (EEG) as it is one of the most elegant neuroimaging techniques. The major challenge lies in using EEG to decode the character the subject is thinking. To simplify the problem, we try to decode a digit thought by the subject from their EEG recording. We use custom EEG headset interfaced with arduino to record EEG over the occipital region while the subjects are looking at visual stimulus of different digits (0-9). The basic workflow includes:-
1. Discriminating event-related desynchronization (ERD) and synchronization (ERS) that occur during the onset and removal of the stimuli respectively from the resting state to mark the period when the subject thinks of one single digit. The raw data is transmitted from the headset’s bluetooth module to the receiver connected to an Arduino.
2. From the EEG data recorded between an ERD and ERS, the stimuli is decoded using deep convolutional networks (CNN). The deep CNN will be implemented on the Terasic DE-10 Nano Board`s Cyclone V FPGA.
3. We use Morlet wavelet components corresponding to frequency ranges of 8-30 Hz (alpha and beta bands) at each time point of the EEG recording. From the time-frequency maps, we aim to decode the digit using a deep feedforward network.
4. The decoded digit is displayed on an OLED display device.
This allows for a proof-of-concept for the method and this can be extended to all characters and then words to revolutionize the way people write texts on their devices. This could also allow people with disabilities to text like others, thus bridging the gap through technology. The method is valid for one particular subject for whom the network is trained. To apply the same to another subject, the training procedure has to be carried out once again.

Fig 1: Initial Overal Design
References: Terasic, Intel, https://www.emotiv.com/
The Intel DE-10 Nano board contains various Hardware feature which will aid the development of this project.
The major contribution of the design is a basic framework for implementing a Deep learning-based Brain-Computer Interface (BCI) system on FPGA. Present BCIs are mostly used in a research setup or require heavy computing platforms connected for efficient functioning. This restricts their mobility and hence usability to an average user. In this project we focus on designing a BCI where the subject can type using their EEG signals. Our primary goal was to move the mouse pointer using EEG signals from a subject. Once the subject is able to move the pointer, we plan to relay the output to a visual keyboard where the subject can control the pointer to type using the on-screen keyboard. Since the design is based on FPGA, it is supposed to be mobile and much more usable than current state-of-art machines.
For a proof of concept and to judge the potential of our design, we used one of the datasets from the BNCI Horizon 2020 database, specifically the 4 class motor imagery dataset. We use this dataset because this aligns with our primary goal of mapping the 4 classes to 4 directions of pointer movement(up, down, left and right). Motor imagery is a well-explored paradigm in BCI and therefore it used for the proof of concept. A deep network is trained to classify each segment of EEG data into one of the 4 classes. Deep network allows better classification as compared to the P-300 method and also provides a robust method to classify without prior inspection of EEG data to extract features. Once a deep network is trained, we implement the network using the learnt weights on FPGA and run forward passes of the data. Since the network is trained on multiple trials of the same subject, it is expected to be robust to inter-trial variability and thus perform well on further scans from the same subject.
The combined powers of deep learning and FPGA pave the path for future mobile BCI platforms that would revolutionize the way people go about their daily lives. Our results are promising and indicate the scope of bringing BCIs to mobile platforms. With out current design, we can succesfully classify the 4 classes with about 80% classs-specific accuracy. Next up, we would be interfacing the output to move mouse pointers and enable typing using an on-screen keyboard. We would also be using the OpenBCI board to collect EEG data from subjects while interacting with this setup and therefore update the network weights to suit that particular subject. Hence in the upcoming steps, we would design a personalized system for individual subjects that allows them to type using their brain waves, or as like calling it - Brext.
Why Intel FPGA?
The main reasons for using an Embedded systems for this project is to make the sytems easily movable and real time. We use Intel FPGA in particular because:
i) Cyclone V SoC give an important advantange of Faster clock rates using the ARM processor and low power and targeted acceleration of the Intel Cyclone V FPGA.
ii) The tools provided by Intel such as Quartus, Qsys, Power Estimator allows fast development of the product.
iii) The IP Designs provided by Intel/Terasic, provide a great starting point to implement the designs.
Three key components of our project are -
The EEG datasets are downloaded from the BNCI Horizon 2020 website (http://bnci-horizon-2020.eu/database/data-sets), specifically the "Four class motor imagery (001-2014)" dataset. The data corresponding to the task is extracted using MATLAB scripts. We create time-frequency blocks for each electrode.
A deep network is trained to classify the time-frequency maps into one of the 4 classes on Torch. Since the ideal network is not known to us apriori, we train with different hyperparameters and architecture. Once the optimal network architecture and hyperparameters are found using 80-20 cross-validation technique, it is used for deployment. Currently the network has 23 Layers including the last LogSoftMax layer that's required only while training as we use a Negative Log Likelihood loss. The network is trained using adam optimizer. The network architecture details are shown in Figure below. 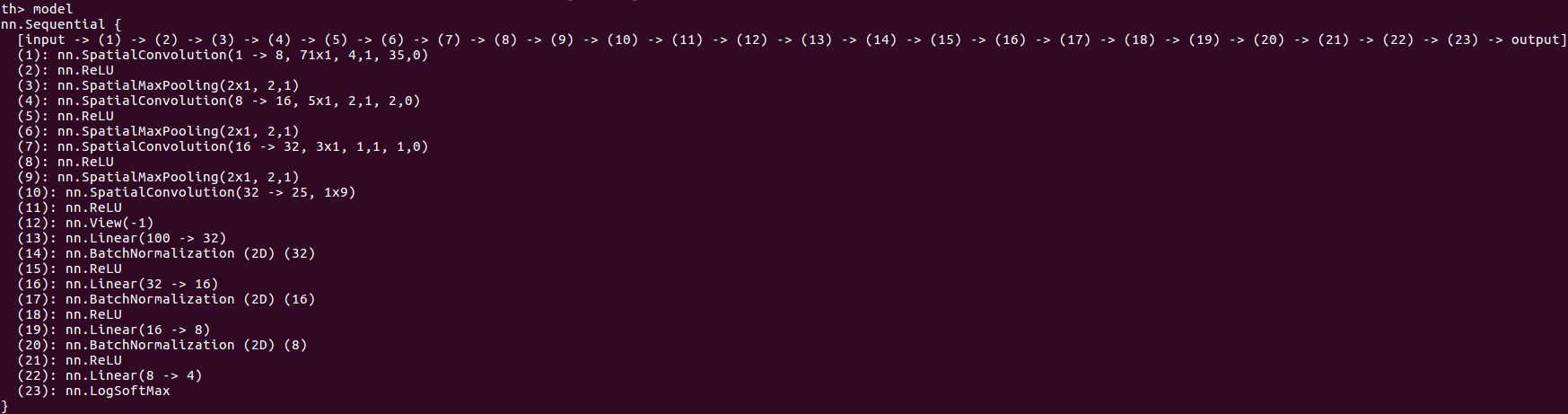
Fig 2: CNN Architecture
Once the network is trained, the weights are saved as matrices and exported to .h files to be used for forward propagation on FPGA.
Forward Propagation on FPGA
The forward propagation of CNN networks consists of 4 main layers.
i) Convolution layer- This layers involves convolution between the weight kernesl and the input image represeantations spread across various channels. This involves Repeated multiplications and additions of floating point numbers.
ii) Maxpooling layer- This layer involves finding the maximum value among the neighbourhood pixels. This provides a type of down sampling. It requires comparators.
iv) Activation layer - The activation used in this network is a Rectified Linear Unit or ReLU. It is y = max(0,x) for every pixel. There are no computions involved.
v) FullyConnected layer - The fully connected layers at the most basic level are floating point matrix multiplications. Hence this involves matrix multiplications and additions. This layer has many weights which are stored in the DDR3 memory. Hence, data reading from the DDR3 memory to the the FPGA using the avalon bus takes a lot of time.
vi) Batch Normalization layer - This layer subtracts each pixel by the mean of the image and divides it by the variance. Hence this requires floating point divisions. This layer consumes the most amount of computation time.
All the codes for each stage of the pipeline can be found on the github repo of the project at - https://github.com/arnaghosh/Brexting
The performance parameter for the application includes:
i) Development Time: The time required to develop a design on an embedded systems is an important factor. Creating a soft core NIOS II processor and integrating other components such as Timer, Memory using QSYS reduces the devlopment time drastically. Also, in-built IPs such as floating point hardware/divider aides in the development of the designs.
ii) Number of desisions processed in 1 second : An important aspect of using FPGA is to accelerate the forward propagation of Convolutional Neural Networks (CNN). CNNs involve huge computing overhead of floating point additions, multiplications and division. Hence, it is necessary to have custom hardware which can make these calculations in realtime. In general FPGA have slower clocks. But in the Cyclone V SoC due the presence of ARM processor allows the designs to run at higher clock frequency. Thus the throughput increases. Currently, the entire program is run on the NIOS-II softcore processor and can process decsions per minute.
iii) Power consumed : The power consumed by the device is an important factor in embedded systems. It is also necessary to measure the power required by the design. The Early power estimator by Quartus allows us measure a almost correct estimate of the power consumed by the device.
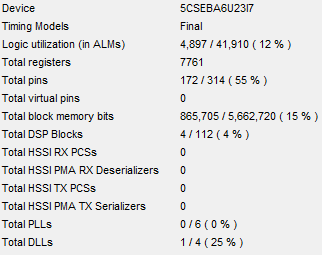
iv) Area of the hardware on the design : It is important that the design fits in the hardware present.
Current Device Area Summary (Fig 3) :
Timing Summary from TimeQuest Timing Analysis:
Fast Model :

Fig 4a: Setup Time

Fig 4b: Hold Time
Slow Model

Fig 5a: Fmax Summary

Fig 5b: Setup Time

Fig 5c: Hold Time
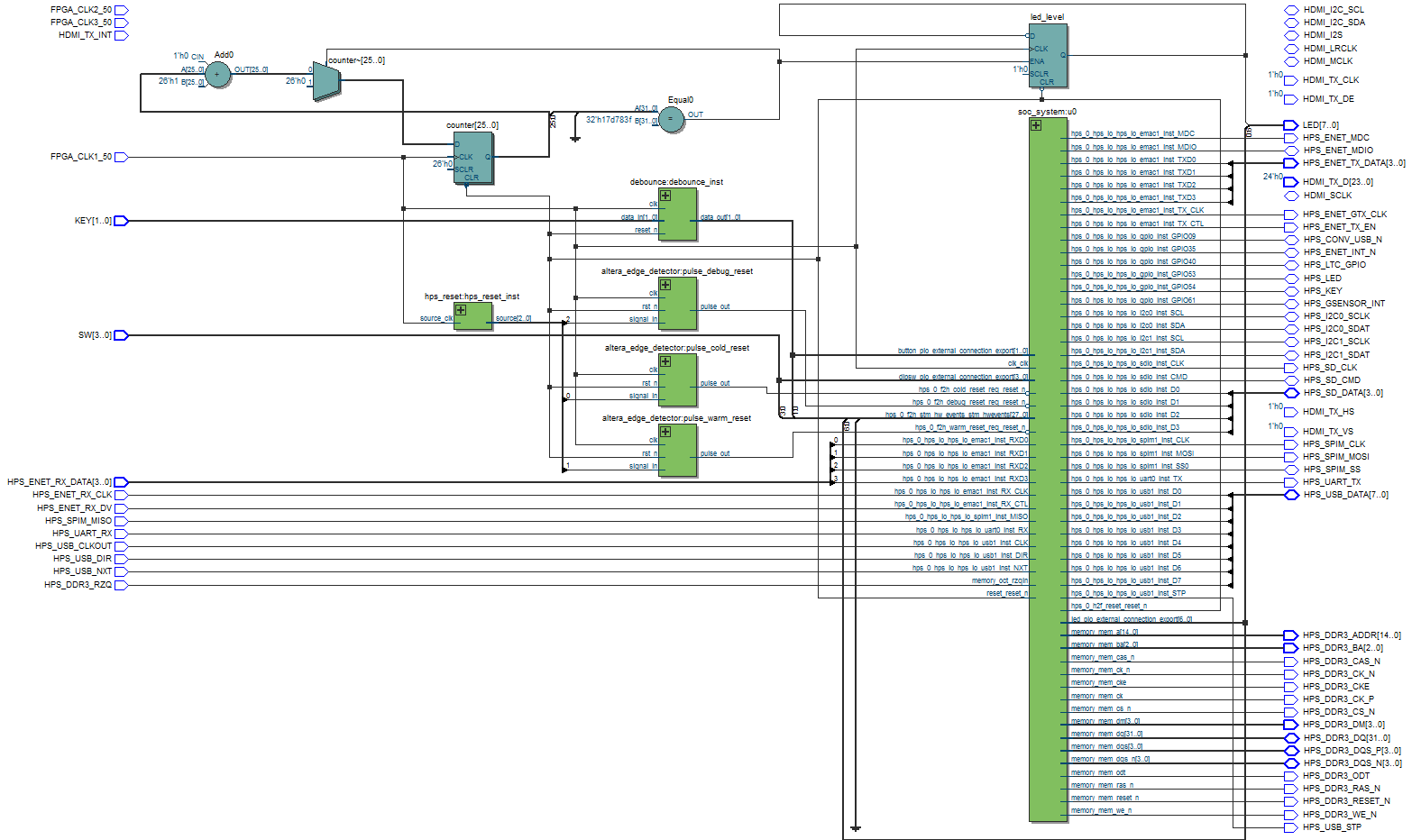
Fig 6: Top Module
Currently, the design architecture was trained on a GPU. The weights and praraments were obtained. These weight were converted into C arrays. The forward propagation of the convolutional neural network was implemented from scratch.
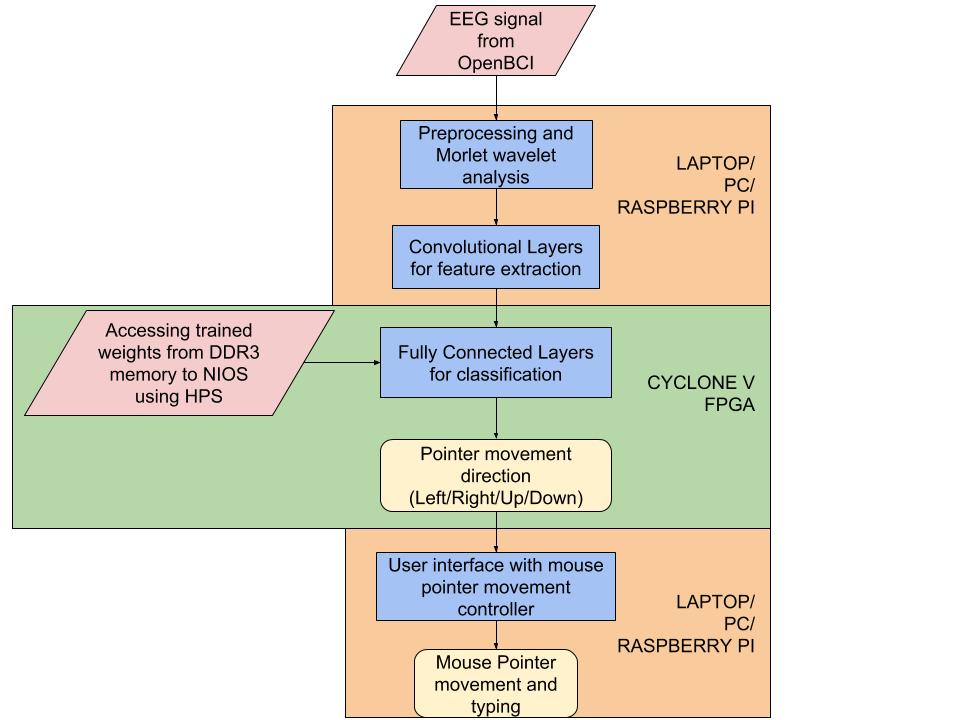
Fig 7 : Flow Chart Illustrating the Input to Output information flow
A video of the working demostration can be found here:
Conclusion
Current Delivarables:
1) Implementation of Fully Connected, Batch Normalization and Activation layers on FPGA using NIOS II softcore processor. Current design has 862 floating point parameters in the FPGA.
2) DDR3 Memory access using HPS.
3) Acceleration (14.3% reduction in time) using the In-built floating point hardware module.
4) Recognizing left, right, up, down movement direction from EEG signal to move the mouse pointer which selects the letters on on-screen keyboard .
Future Deliverablies:
1) The current system is not real time. The data is first preprocessed then loaded into the FPGA manually. Automating this process would be the next step.
2) Replacing laptop/PC with Arduino/RaspberryPi to create a standalone system.
Reference
1) GHRD project – NIOS DD3 Interface : http://www.terasic.com.tw/cgibin/page/archive.plLanguage=English&CategoryNo=205&No=1046&PartNo=4
2) NIOS II Reference- https://www.altera.com/en_US/pdfs/literature/tt/tt_my_first_nios_sw.pdf
3) NIOS Profiling - https://www.altera.com/content/dam/alterawww/global/en_US/pdfs/literature/an/an391.pdf
4) NIOS Custom Instruction: https://www.altera.com/en_US/pdfs/literature/ug/ug_nios2_custom_instruction.pdf