PR072 » 无人驾驶的视觉感知系统设计
本课题旨在设计出一套基于视觉图像的无人驾驶系统。当今居民的生活质量日益提高,人们对物质生活的追求越来越丰富多彩,汽车也成为了人们生活中不可或缺的交通工具应用范围更广的智能产品。而且各种各样的道路的大力修建极大地方便了人们的出行与生活,但是随着大量的机动车涌入也加大了交通事故的发生,在巨大的市场与挑战面前,无人驾驶系统相关技术的研究显得迫在眉睫,但是经过研究,无人驾驶相关技术在嵌入式设备上的运行速率并不理想,而高质量显卡由于价格及功耗等问题,无法大面积普及。所以我们希望能够通过FPGA设计一套基本的无人驾驶系统。能够通过视觉图像完成车道检测、目标识别及路径规划等功能。
Along with the development of artificial intelligence, self-driving cars are becoming a reality and the means of transportation will be changed forever. In order to make the car have more autonomy, self-driving cars need to keep informed of its surroundings - first of all, through the perception (identification information and its classification), and then take some action through the control of vehicle's automatic computer, Therefore, we plan to develop an automatic driving visual control system, which can complete lane detection, object recognition, when the car is driving .
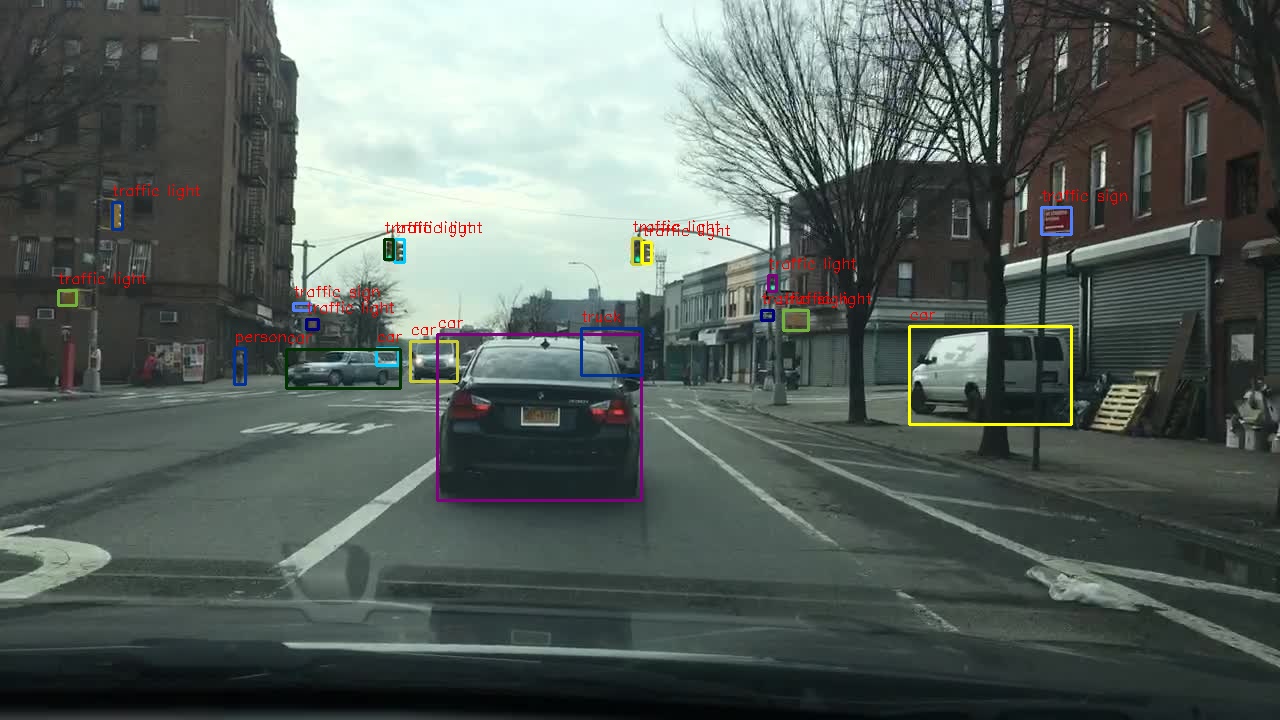
The image in front of the car is collected by the camera, and the collected image will be processed by the traditional image algorithm and the convolution neural network, which is accelerated through CPU+FPGA architecture. After the acceleration, the image can tell the lane in real time and display the identified target on the display screen, as shown in the following figure:

Figure 1. Algorithm operation result
As the core component of the whole control system, Intel FPGA relies on its advantages of high integration, low space occupancy and low power consumption. In the system it can speed up the CNN, making whole image process has more superior real time. Due to its high concurrency and high flexibility, it can greatly improve the rate of algorithm, providing a high possibility, for follow-up improvement. Because of its advantages of low power consumption, high performance and flexibility, Intel FPGA has gradually become an indispensable hardware part of deep learning now. With OpenVINO acceleration package provided by Intel, development efficiency and product performance can be greatly improved and enhanced.
The depth of the development of neural network algorithm is faster and faster while the related research also goes deeper. The relevant algorithm performance tests also show more superior performance comparing to traditional algorithm, but when using the algorithm in a real project, it meets obstacles probably because of the difficulty of a large amount of operation in deep neural network algorithm. The problem of computational force in image processing is particularly obvious.
The implementation of deep neural network algorithm mainly deploys and realize with graphics card or transfer relevant data to the cloud for possessing and returning results. But as for mobile terminal and real-time applications, the above methods are not recommendable. The design purpose of this project is to improve the computing speed of relevant algorithms through the high concurrency of FPGA, finally providing the possibility for the realization of deep neural network algorithm in the mobile terminal with high real-time performance.
Autonomous driving is one of the most important parts of artificial intelligence implement while the deep learning becomes widely used in autonomous driving because of its higher precision and effectiveness comparing to the traditional algorithm. Meanwhile, the autonomous driving is a wonderful carrier for verifying the cognitive computing capacity of audiovisual information. Our project focus on this, develops a visual perception unmanned platform with high performance, low power consumption and high flexibility based on CPU+FPGA heterogeneous platform, providing enough margin algorithm which can be applied to subsequent autonomous research and development localization, decision and control, etc.
As for the autonomous driving, the visual information is an important part in the whole system designing, which needs the high efficiency and instantaneity of information detection and recognition from road. This project uses BDD100K as training data to train the model, the tiny-yolo as target detection framework to optimize through the IOU-NET. Finally, the OpenVINO toolkit provided by Intel is used to transform the target model, so as to accelerate the model through the FPGA (Arria 10) provided by Intel, improving the instantaneity. Making the multitarget detection part of the system own the advantages of high accuracy, high efficiency (and instantaneity) and low power consumption.
First, for the deep neural networks, the diversity of data is particularly important for testing the robustness of the perception algorithm. Our team finally chooses the BDD100K provided by Berkeley which is the largest content by comparing to many autonomous driving open-sourcing dataset such as KITTI, GTTI, BDD100K whose data has three main characteristics: scale, in the real street collection and collecting with time information.
Among them, there are about 1.84 million calibration boxes in the data set labels, with 9 categories, respectively: bus, light bus, signal, pedestrian, bicycle, truck, automobile, train and motorcyclist. It has six different weather: sunny, overcast, cloudy, rainy, snowy, and foggy, covering three time phases: dawn, daytime and nighttime. Meanwhile, there are high definition and low definition pictures, large data scale and calibrated error which are highly integrated with application of our project, so we choose BDD100K as our training data. The following figure is the annotation result of a verification diagram in BDD100k. We can inform that the annotation result is very comprehensive and accurate.
Figure 2.BDD100K annotation result
In resent years, target detection algorithm has made a great breakthrough. We consider overall and choose the latest and most widely used yolov3-tiny model from YOLO, SDD one-stage algorithm for the target detection rather than the RCNN represented two-stage algorithm.
The yolo v3-tiny model is a simplified version of yolov3, the main difference between them is that it has no resnet residua, only 23 layers, containing 5 down samples and 2 up samples. There are two yolo layers which has 6 anchors each.
The specific structure is shown in the following figure:
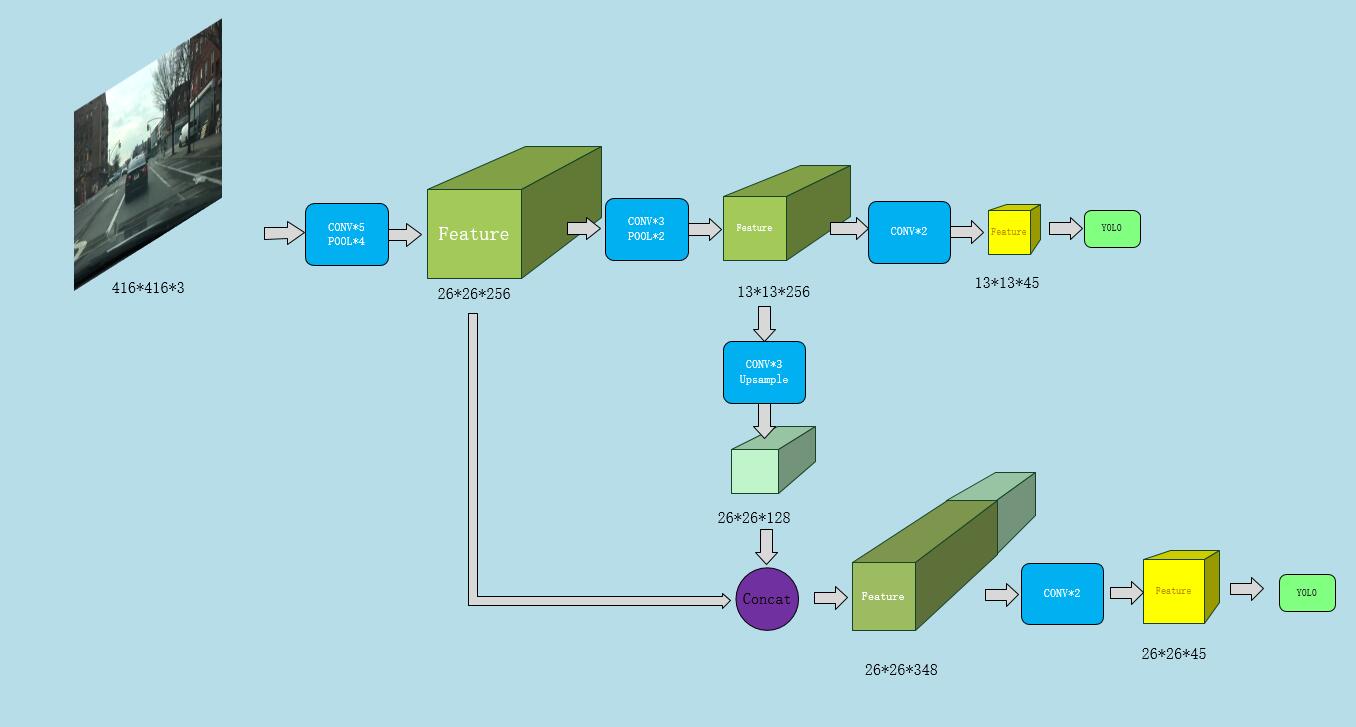
Figure 3. yolov3-tiny structure
The corresponding parameters and input-output relationship of each layer are shown in the following figure:
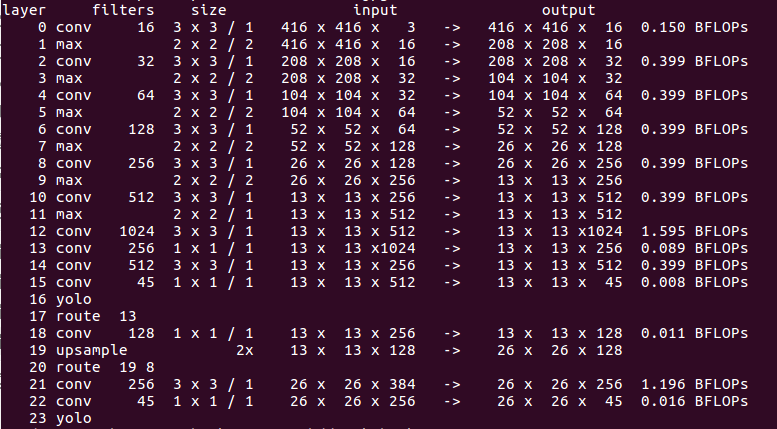
Figure 4. yolov3-tiny i/o diagram
The output tensor obtained from the model, processing by object confidence of threshold and the non-maximum suppression. We can obtain the detection frame of the target. However, the accuracy of detection results by using the yolov3-tiny model alone reaches about 91%, the output Avg IOU result is not high enough. This result is not accurate to reach the standard of the calibration of the test. As shown below:
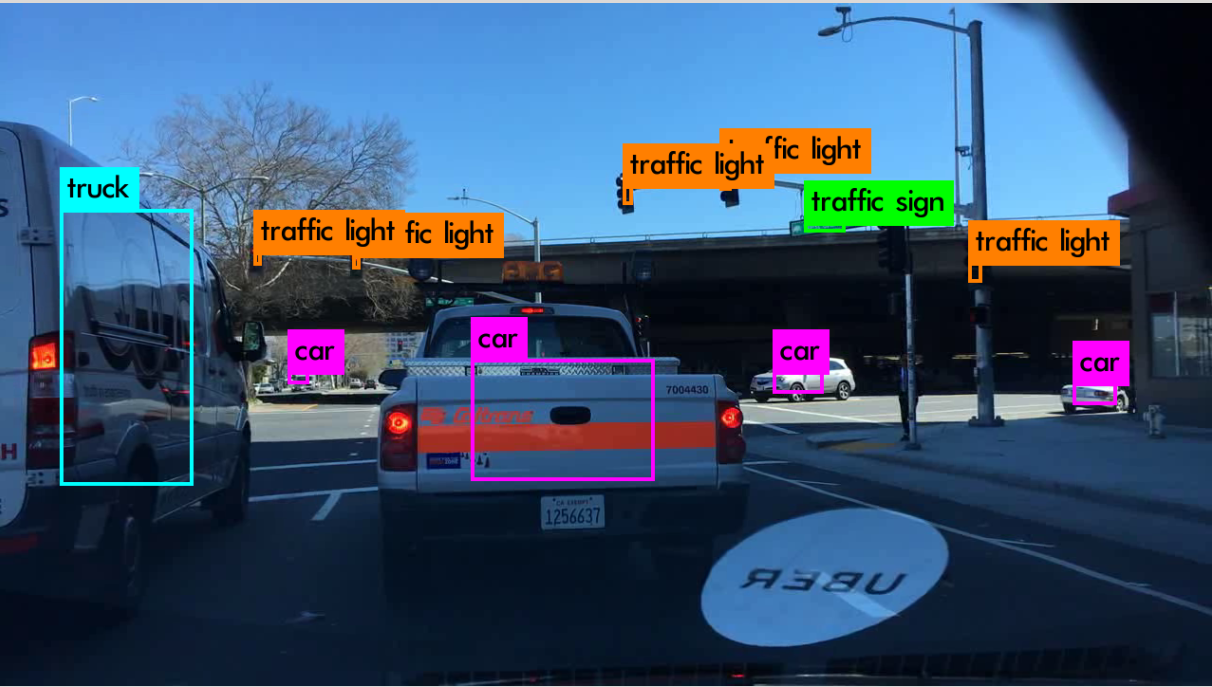
Figure 5. yolov3-tiny detection result after training
In this regard, we use Iou-net's idea of IOU optimization to optimize the detection output frame. The actual result after optimization is shown in the following figure. It is obvious that optimized calibration frame effect is more accurate comparing to the original model's calibration result.
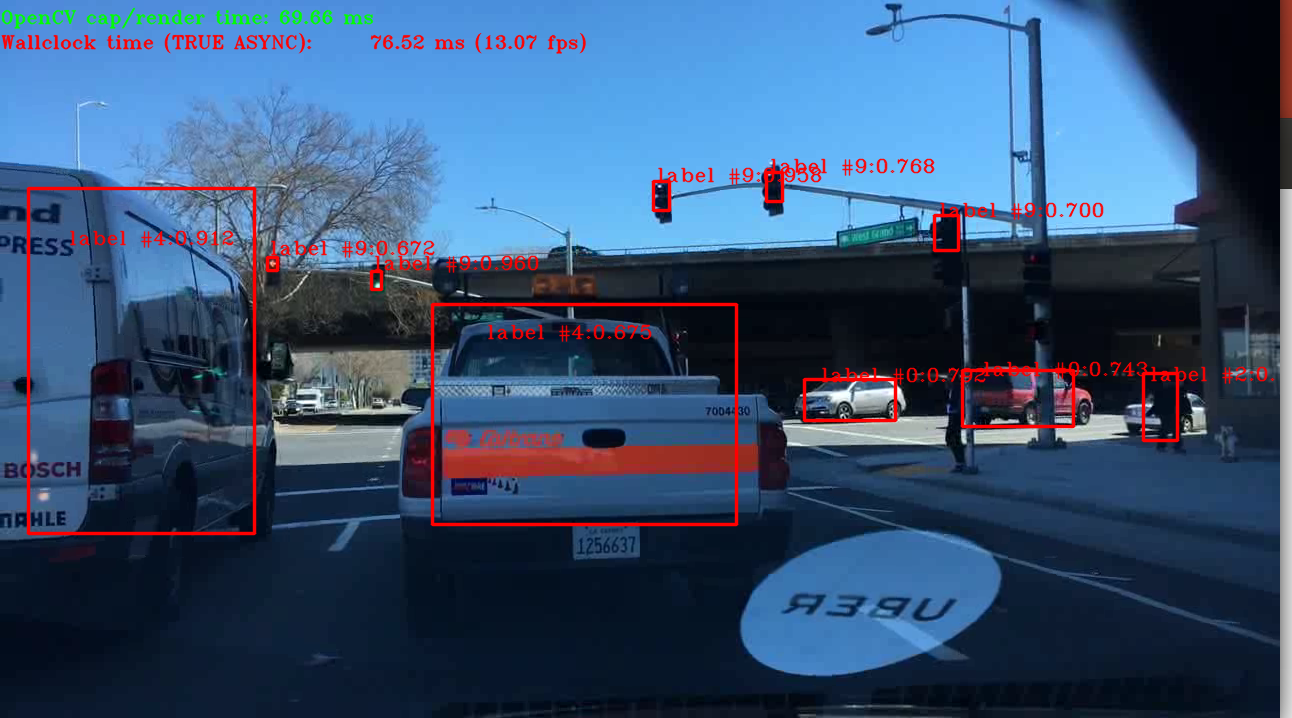
Figure 6. yolov3-tiny algorithm optimization diagram
After successfully finishing model generating and optimizing, it is capable to make relevant deployment by OpenVINO from Intel and accelerate by FPGA.
OpenVINO is a latest open-sourcing toolkit provided by Intel for deep learning model deployment, allowing us to optimize models and accelerate inference from multiple devices. It consists two core components, Model Optimizer and Inference Engine. Its structures are shown in the following figure:
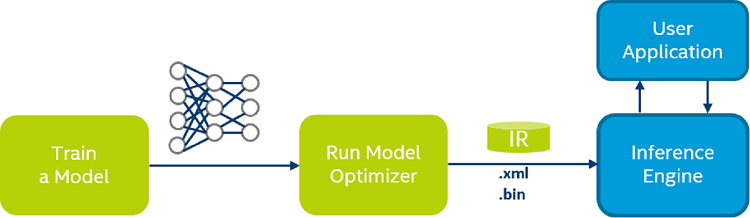
Figure 7. OpenVINO structure
First, our team use the OpenVINO to optimize our CNN model, the Model Optimizer mainly success the function of FP quantization, model compression and model analysis. The optimized model saves the network file in the .xml file and the weight file in the .bin file.
After finishing model transformation, we need to use the API of the inference engine provided by OpenVINO to call(调用) the model, setting up the model acceleration component. Finally complete the non-maximum suppression and output the frame optimization.
As for the model inference acceleration, we choose FPGA which based on the DLA architecture for acceleration. The FPGA plug-in runs by loading s series of API of DLA software. When the DLA is running, it is built on the top of the Intel FPGA OpenCL Runtime. The OpenCL Runtime loads the board card support package of the FPGA motherboard, which contains the device driver. Finally, the FPGA motherboard interface is used to communicate with the DLA FPGA IP, containing all the CNN primitives accelerated on the FPGA.
Its software architecture stack is shown in the figure below:
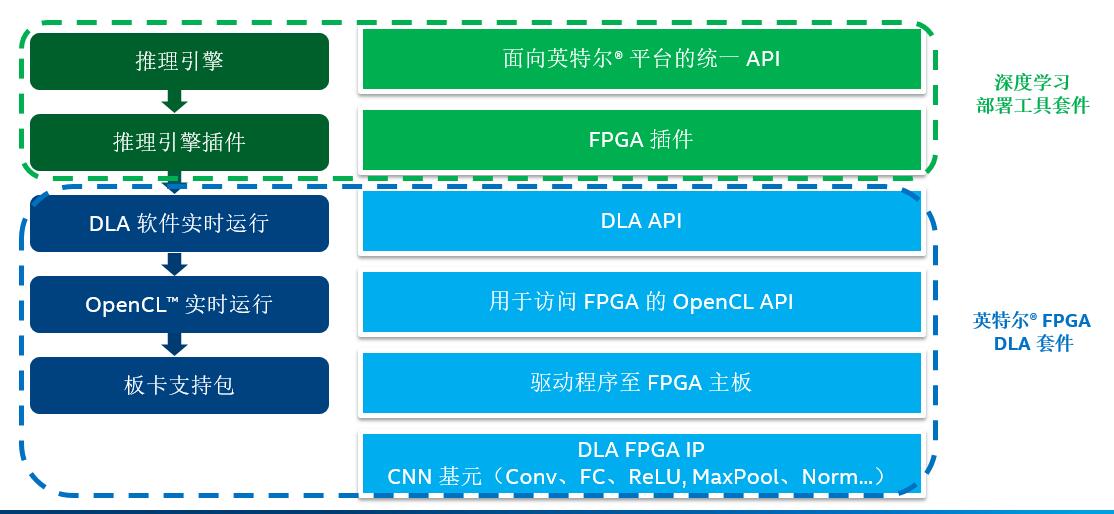
Figure 8. DLA software architecture diagram
The mapping schematic diagram in the DLA architecture is shown below:
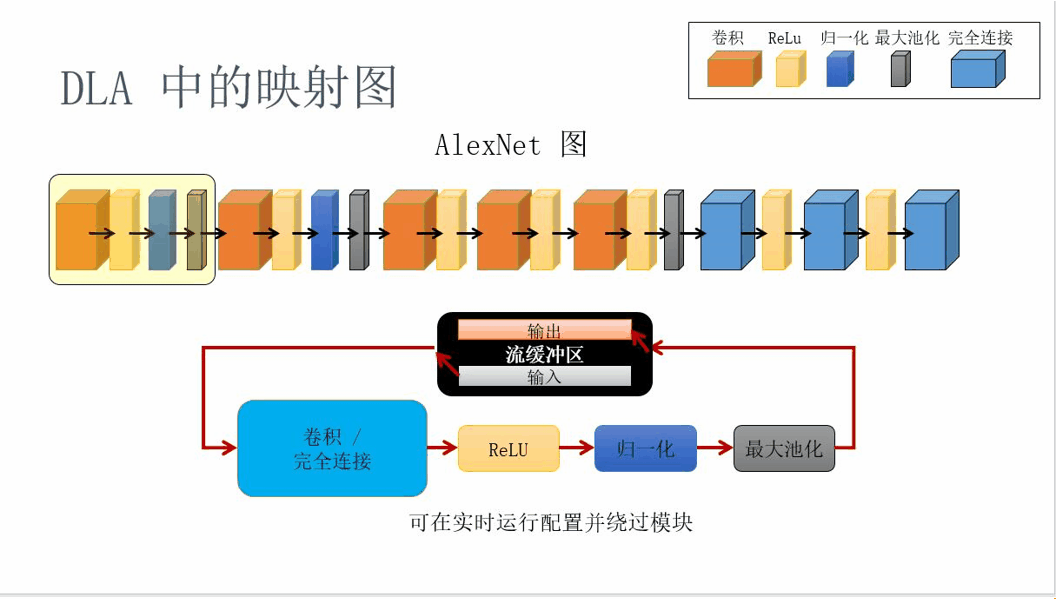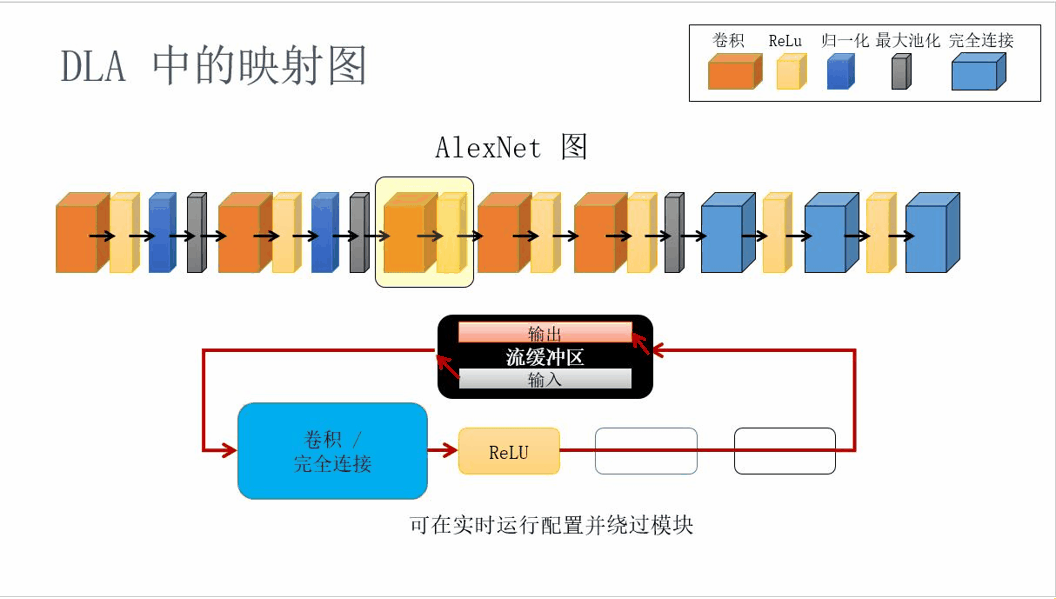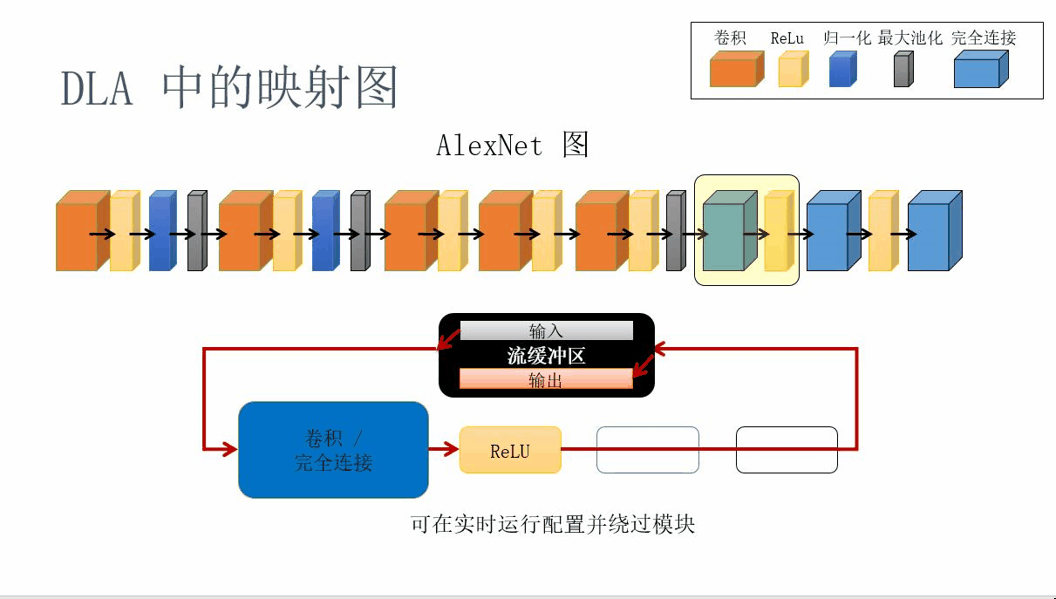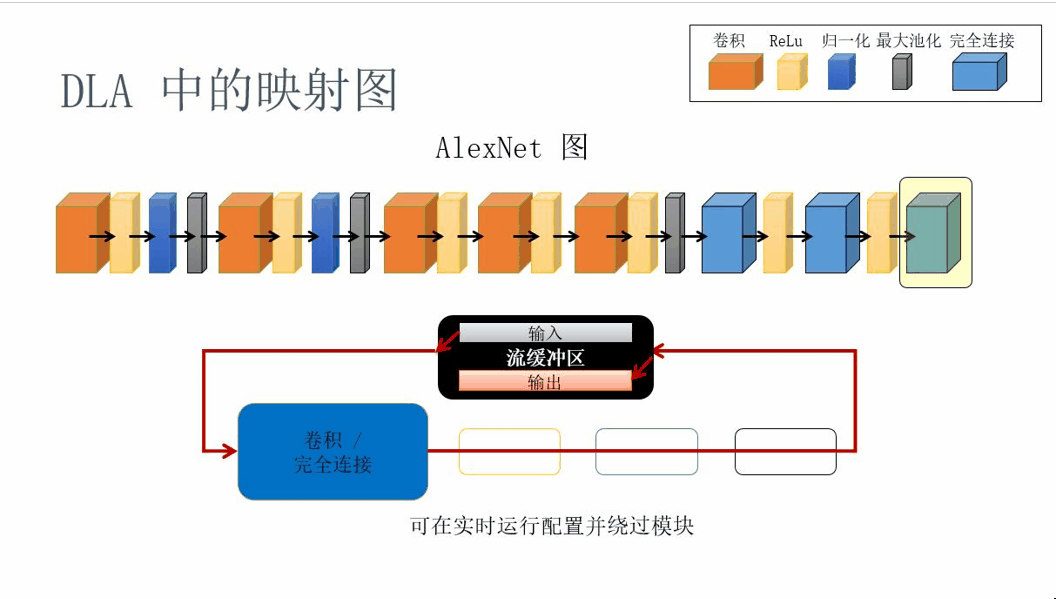
Figure 9. DLA mapping principle diagram
In conclusion, the design and operation process of the whole model is shown below:
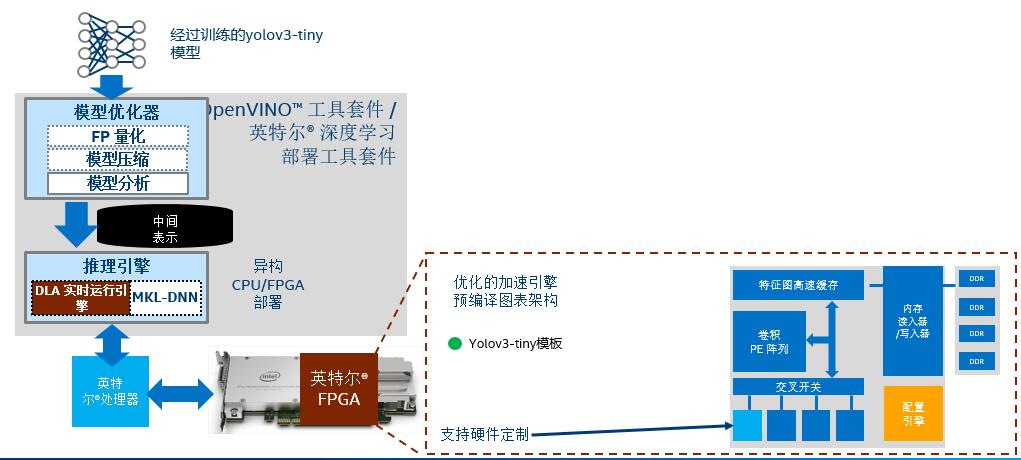
Figure 10. Model design operation structure diagram
For lane line detection, traditional algorithm is applied for detection, and the main steps are as follows: 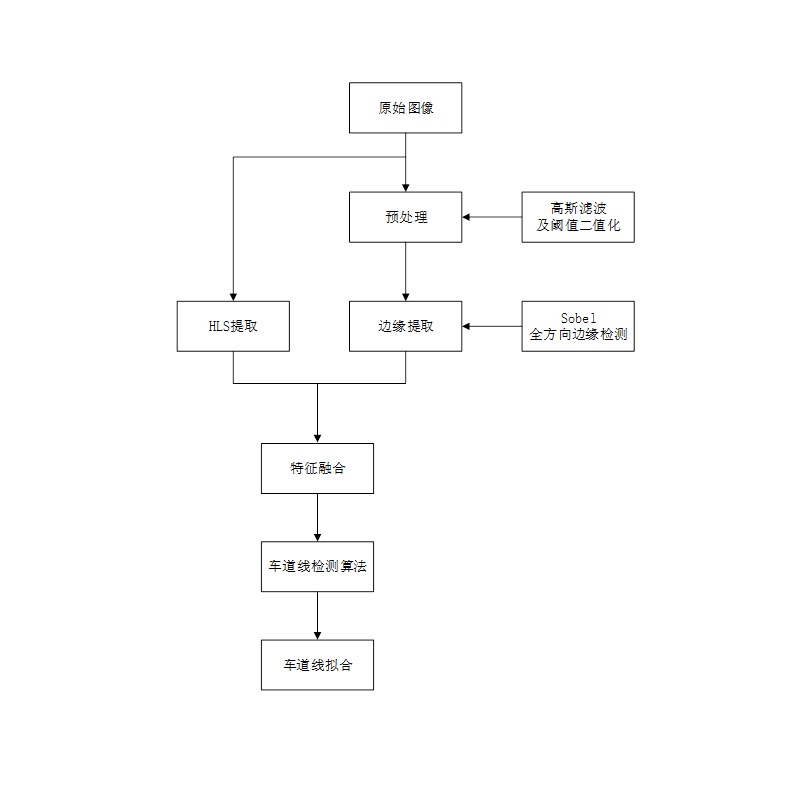
Figure 11. Lane line detection flow chart
For the original images, we mainly extracted the luminance saturation (LS) features and edge features of the image to complete lane line detection. Through several experiments, we found that after the images were converted to HLS space and thresholding for LS, the features that extracted by original image were most extracted. The original image and the image after extracting LS features were shown in the following figure11and figure12:

Figure 11. Unextracted lane line image

Figure 12. Extracted LS features result image
As for the edge features of the images, we can extract the edge features of the pixel gray with step changes or roof-like changes in the image and eliminate the irrelevant information in the image, so as to carry out the following straight line extraction. Here, the most commonly used Sobel operator is adopted for edge detection, and the detection results are shown as follows:

Figure 13. Extracted edge features result image
By integrating common features, we can obtain a relatively ideal detection image, as shown in the figure below:

Figure 14. Integrating common features result image
As for the lane line, since the Hough transform result is not stable, a more stable method is adopted for lane line detection. Firstly, the perspective of the front lane line in the image is transformed into an aerial view, and the transformed image is shown below.

Figure 15. Transformed image
We selected and filtered the lane line that project on the X-axis and used the filtered point to fit the two quadric fitting curves which are related to the lane line,next color the middle points of the two quadric curves. The processed result is shown in the figure below

Figure 16. Fitted out lane line result image
Finally, we transform the aerial view back to the original picture to obtain the detected lane line and the current lane.

Figure 17. Fitted out lane line on original image
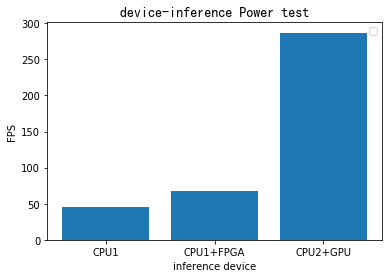
Figure 18. Device-inference power test contrast
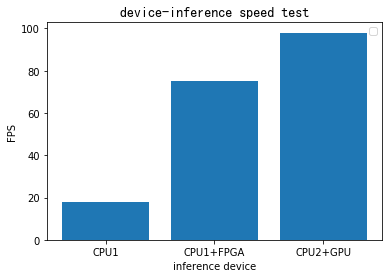
Figure 19. Device-inference speed test contrast
HERO(Heterogeneous Extensible Robot Open Platform)is a heterogeneous expandable robot platform composed of CPU+FPGA designed by Intel. It uses an Intel i5-7260u as the main processor, carrying an Arria10 GX series 1150 FPGA as the acceleration card. With the high concurrency, low power consumption and high flexibility of FPGA, it is able to complete the acceleration of various algorithms.
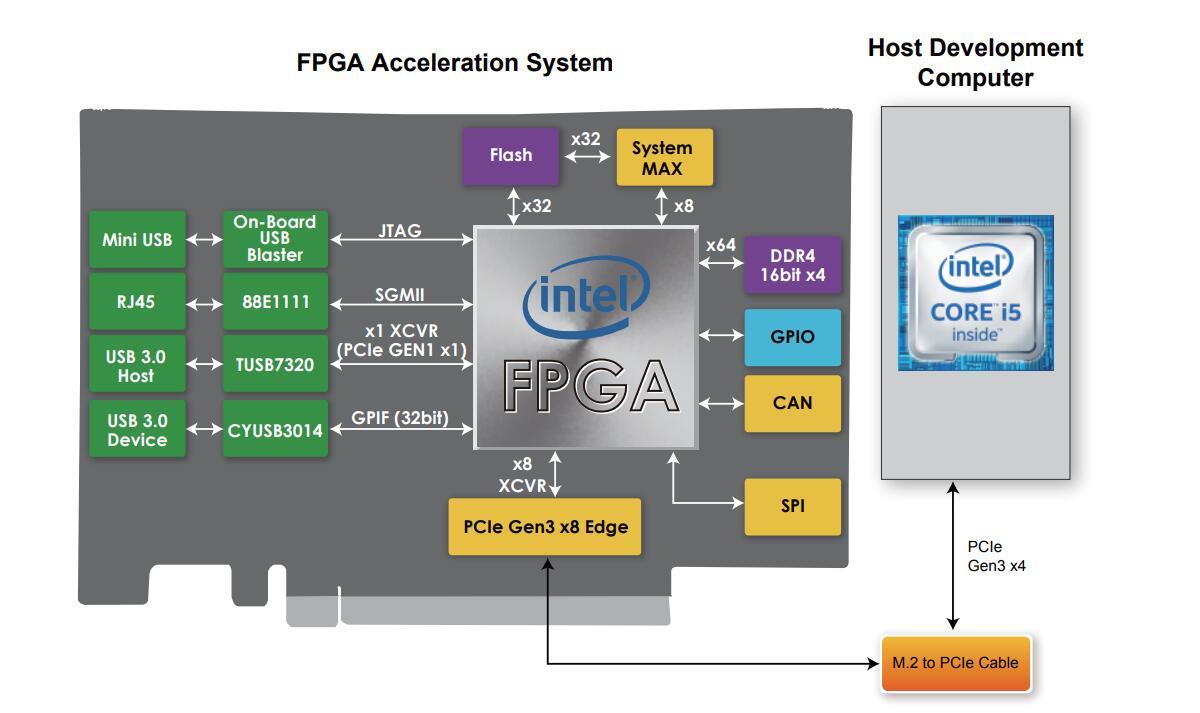
Figure 20. HERO platform structures diagram
|
FPGA Device |
Intel Arria 10 GX 10AX115S2F45I1SG |
|
CPU Device |
Intel® Core™ i5-7260U |
|
Logic Elements |
1150K |
|
Memory |
8GB DDR4-2133 SO-DIMM and 256G GB SSD |
|
Peripheral interfaces |
USB 3.0/2.0 /Gigabit Ethernet/UART/GPIO/CAN |
|
Expansion |
One USB Type-C port, support Thunderbolt 3 , USB 3.1 Gen 2 and DP 1.2 |
This platform uses a heterogeneous environment for software development, and the software part is executed on different platform architectures. The software execution platform is shown in the following figure, in which FPGA is mainly accelerated by using DLA architecture:
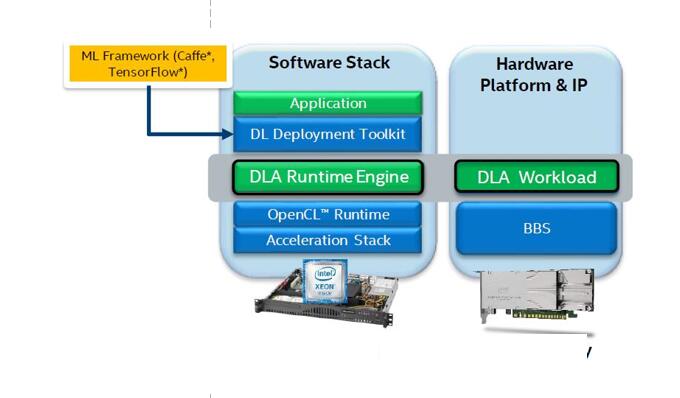
Figure 21. Software running architecture diagram
