 Marine Related
Marine Related
A smart underwater microbial delivery system for coral reef habitat recovery
EM043 »
In this project, we propose the first underwater and deep-learning-enabled intelligent microbial delivery system for coral reef habitat recovery. The system will be able to deliver coral probiotics and monitor its efficacy. The delivery is precisely regulated by a deep learning network that monitors the color change of corals.
 Health
Health
CO2 gas sensor for air quality monitoring
EM034 »
CO2 gas sensors are rapidly gaining interest as a low-cost tool, not only for monitoring air quality inside buildings but also to assess the risk of infection by airborne diseases such as COVID-19.
We will develop a prototype system using the DE10-Nano development kit that will be based on a custom RISC-V microcontroller for the processing of the signals coming from the CO2 sensor. The system will be able to measure the CO2 concentration in the range of 400-5000 ppm.
 Food Related
Food Related
smart farm system
EM012 »
In this project, we will create an autonomous smart farm system by measuring the climatic conditions such as humidity temperature CO2 emissions then we will control the farm equipment such as water tank temperature inside greenhouse and Fire suppression system etc.
The system will be also controlled by the farmers using a website and a mobile app, the farmer can change the temperature, switch on and off the drip irrigation system etc. The website and the mobile app will provide a real time overview of the system so we can check the temperature, soil humidity… at any moment. In case of a failure in any part in the system the farmer will be informed by the website and mobile and an alarm is triggered.
The farm is also provided with a security system so when intruders try to enter the farm an alarm will be triggered and a SOS message will be sent to the farmer and the police
The energy to the system will be provided by a solar tracker panel
 Water Related
Water Related
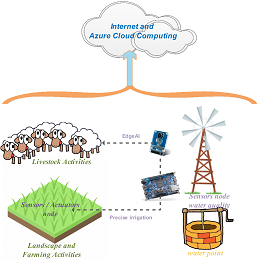
Smart water monitoring, protection of pastoral and agricultural areas on dry-lands
EM005 »
With climate change and water scarcity, arid countries' policies aim to conserve dams’ water for domestic and industrial use only. Due to a lack of budget, having no other alternative, Small-farms crop production turns to the use of innovative low-cost solutions for irrigation and livestock. The proposed project outlines a new approach supporting agricultural agencies and policies at all levels, livestock professionals, smallholding farmers, and local populations, to stabilize the ecologically unsustainable exploitation of the water on dry-lands. The proposed approaches aim to implement Edge Artificial Intelligence on Intel FPGA and Microsoft Azure cloud computing for the prediction of water quality and its evolution, manage an innovative irrigation process, livestock watering points, as well as artisan activities (pottery...).
 Other: Data collection and monitoring
Other: Data collection and monitoring
Sustainable Agriculture:Smart Farm For Biodiversity preservation in South-Cameroon
EM016 »
The project uses a FPGA kit and sensors to collect soil pH, soil moisture, soil temperature and soil NPK in smart farm to improve agriculture data collection and analysis
 Other: Ecological
Other: Ecological
Forest Environment Analysis to Detect and Predict Forest Fires
EM021 »
Recently, forest fires are on the agenda of a lot of countries. A significant portion of forests in tropical zones is facing a risk of burning down. To help to respond quickly to fires, a cloud-based IoT solution could be used. Current fires will be sensed with a camera and CO2 sensor which will use either NDIR or electrochemical technology. System alerts authorized personnel about risky and emergencies over Cloud. Additionally, notable environmental factors are oxygen, combustible gases, humidity, and temperature, so sensors for these factors will be used to collect environmental data to predict potential forest fires beforehand. This collected data will also be available in the Cloud. System alerts authorized personnel about risky and emergencies over Cloud.
Cover image by skeeze on Pixabay
 Marine Related
Marine Related
Mucilage Pre-detection System
EM023 »
Mucilage pre-detection system determines the possible locations where mucilage can appear using sensors to detect the amounts of nitrogen and phosphate in the water, a thermostat to determine water temperature and transmit this information to the authorities.
 Smart City
Smart City
Automated traffic control system
EM002 »
The aim of the project is to solve the problems of traffic jams on the city roads. In addition, this should solve the environmental situation in the city: excessive emissions of CO into the atmosphere.
 Other: Climate Change
Other: Climate Change
IOT Home-Alone Prayer Plant
EM003 »
According to the last UN report about Global Warming, we reached the “Code red for humanity”. Thus, we all should show serious steps toward solving such an enormous global issue starting from yesterday and not even from the current moment. The delay in solving this major global threat would cause many drastic circumstances that we might not be able to undo if we kept this “stand-still” manner of reducing CO2 emissions. The damaging effects of greenhouse gases are now clearer and tangible for every human nowadays.
Unfortunately, the main cause of such drastic consequences of global warming is due to the emerging of the technological era that we are both blessed and cursed by using it.
The usage of high-tech devices and their applications is extremely essential for every one of us nowadays. However, the number of emissions of carbon dioxide (CO2) and other greenhouse gases for producing these products is recording remarkable negative records to the point that oriented many scientists to think about how many years left for our existence on our lovely planet, The Earth.
Subsequently, the next generations will be in great danger as they will have to face many dramatic challenges that have been initiated by us, unfortunately.
Without a doubt, we believe that the rise of the technological era caused such a massive issue. However, we also have faith that the technology itself could play the “Hero role” to save our planet through positive and transparent initiatives.
Subsequently, we will shed the light on a special houseplant, the Prayer Plant, as it has a unique capability to remove the CO2 emission in an efficient manner in comparison with many similar indoor plants. Our initiative in this project is to convince everyone to plant such indoor plants at home, workplaces, etc.
The main goal of this project is to conserve the maximum lifetime of such plants without any human intervention. So, we will depend on INTEL’s DE10-Nano FPGA board to process many vital sensory readings and have all these records stored in the Microsoft Azure cloud for further processing.
 Health
Health
Phase dependent retina stimulation
EM006 »
We try to build a FPGA based solution to stimulate retinal tissue phase dependently of the overlaying local field potentials. By this we want to increase the stimulation efficiency and thus decrease the power consumption of the device.
 Water Related
Water Related
FPGA-based Irrigation System for Soft Fruit Farms
EM007 »
Prototype of an Intel FPGA-based automatic irrigation system for soft fruit farms in Perthshire, Angus and Fife, Scotland, UK
 Smart City
Smart City
SMART TRAFFIC MONITORING SYSTEM
EM009 »
Our project is a smart system to track traffic in city streets to track traffic densities, and it can also detect driving violations.