 Other: SGP - Sustainable Agriculture
Other: SGP - Sustainable Agriculture
AP116 »
Our project aims to provide a smart, user-friendly, domestic mini-greenhouse management system to enable users to grow and efficiently monitor and tend to plants within their own homes. This encourages people to grow their own food plants by removing the difficulties related to gardening in the busy lifestyle.
 Health
Health
AP049 »
Mental and behavioural problems are increasing part of the health problems the world over. The burden of illness resulting from psychiatric and behavioural disorders is enormous. Although it remains grossly under-represented by conventional public health statistics, which focus on mortality rather than morbidity or dysfunction. The psychiatric disorders account for 5 of 10 leading causes of disability as measured by years lived with a disability. The overall DALYs burden for neuropsychiatric disorders increased to 15% in the year 2020. At the international level, mental health is receiving increasing importance as reflected by the WHO focus on mental health as the theme for the World Health Day (4th October 2001), World Health Assembly (15th May 2001) and the World Health Report 2001 with Mental Health as the focus.
Let’s consider Covid-19 pandemic situation, opportunities to monitor psychosocial needs and deliver support during direct patient encounters in clinical practice are greatly curtailed in this crisis by large-scale home confinement. Psychosocial services, which are increasingly delivered in primary care settings, are being offered by means of telemedicine. In the context of Covid 19, psychosocial assessment and monitoring should include queries about Covid-19 related stressors (such as exposures to infected sources, infected family members, loss of loved ones, and physical distancing), secondary adversities (economic loss, for example), psychosocial effects (such as depression, anxiety, psychosomatic preoccupations, insomnia, increased substance use, and domestic violence), and indicators of vulnerability (such as pre existing physical or psychological conditions). Some patients will need referral for formal mental health evaluation and care, while others may benefit from supportive interventions designed to promote wellness and enhance coping (such as psychoeducation or cognitive behavioral techniques). In light of the widening economic crisis and numerous uncertainties surrounding this pandemic, suicidal ideation may emerge and necessitate immediate consultation with a mental health professional or referral for possible emergency psychiatric hospitalization.
We believe that Big Problems have Simple Solutions. If someone is always monitoring you and giving you timely recommendations/suggestions it can help in a very positive way. In this project we are trying to solve this problem with a lot of positivity which is actually very important in anyone's life. Our project consists of a device connected to human body which consists of sensors which monitor different parameters from human body, gas sensor inside the living room to monitor the pollution/toxic gases in the environment, a recommender system which uses the captured images of human/video and uses ML algorithms uses Cloud and Cloud connectivity kit to monitor human behavior. Data from sensors and machine learning algorithms are put together and timely recommendation is given to the people.
 Other: SGP-Sustainable Agriculture
Other: SGP-Sustainable Agriculture
AP050 »
“Farm at ease” (Technology to farming):
To meet the growing population of the world, some serious reforms are required in the agricultural sector to ensure that our food system is ready to meet the upcoming challenges. This pushes us to shift from traditional/conservative agricultural practices to sustainable practices. Further, these sustainable practices are integrated with technological advancements, the major challenges of the agriculture/farming across the world can be resolved in an efficient and effective manner.
The following are some of the key challenges posed by the agricultural sector:
1. There is a considerable gap between the adoptions of technology in the agricultural sector when compared to the non-agricultural sectors especially in third world countries.
2. Mismanagement in crop planning without the proper analysis of soil.
3. Overutilization/underutilization of fertilizers.
4. Mismanagement in irrigation and thereby the water scarcity/wastage may occur.
5. Delay in identification of weeds/pests.
6. Unable to adopt the best practices of agriculture in the other regions.
Proposed solution:
To address above challenges, we are proposing for a design of a system (IOT based with Mobile/Web application development/Message alert system) which will aid the farmer in the following way:
1. Crop recommendation based on the soil condition, climate and water availability of that region.
2. Automatic irrigation system depending upon the crop requirement.
3. Recommendation of organic means of agriculture practice in place of fertilizers to the most possible extent.
4. Disease detection in crops using image processing.
5. Recommendation/alert system will be made in a simple manner and if possible, voice instructions will be given in regional languages.
Design idea:
The above-proposed idea will be designed initially as a real-time prototype device where FPGA board will be integrated with sensors such as NPK sensor, humidity sensor, temperature sensor, water level monitoring sensor, etc., Further, a communication shall be established between the FPGA board and mobile phone using FPGA virtues, Azure cloud, etc., This prototype device will be tested in a real-time agricultural field and based on the feedback/recommendations of the user (farmers) a robust system may be developed in future.
 Food Related
Food Related
AP028 »
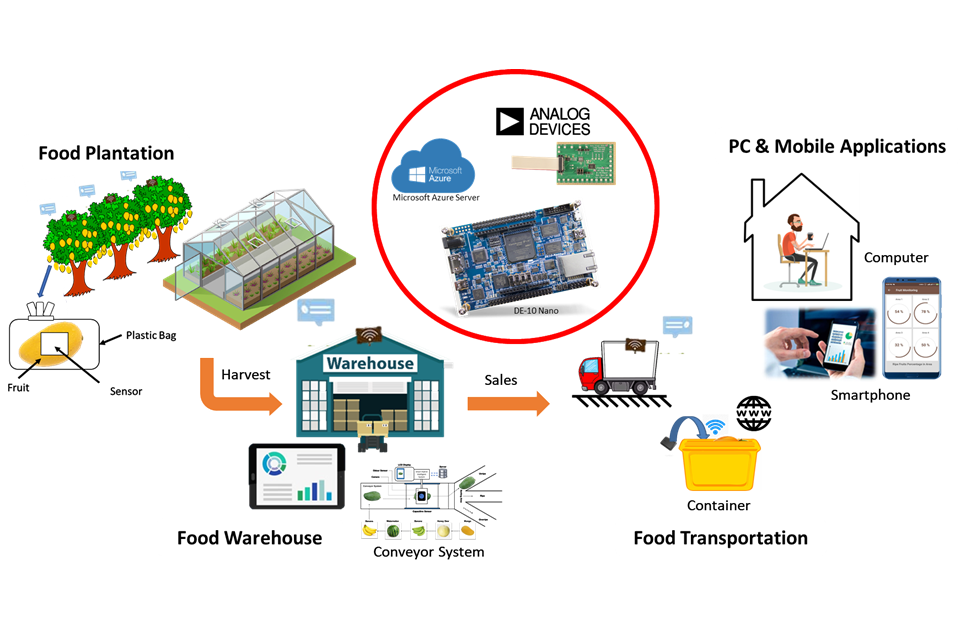
This project proposal presents an Intelligent Food Supply Chain Management System for covering from field to end-user. This project is based principally on THREE (3) different application areas such as Food Plantation, Food Warehouse, and Food Transportation using a smart intelligent system. This system seeks to support and to reduce food waste by improving the reliability of the technology from manual detection to automated detection system designed especially for real-time monitoring using IoT implementation on growth and maturity level of fruits in the Food Plantation, classification of fruits grading in the Food Warehouse and also fruits controlling and tracking during Food Transportation operation. The system is implemented on a FPGA-SoC Intel Cyclone V SoC available on DE10-Nano Kit, Microsoft Azure, and Analogue Devices module to acquire the sensors reading and control the actuators to maintain the suitable environment in three different application areas. The proposed system has high-performance requirements covered by FPGA-SoC since it has concurrency and low power consumption, making it suitable for this intelligent food supply chain management system in smart agriculture applications.
 Other: Agriculture
Other: Agriculture
AP040 »
Agriculture plays a vital role in Indian economy.India ranks second worldwide in farm outputs.Though crops are facing problem like pests, climate change, soil erosion, diseases water scarcity and this led to a great loss.Farmers who are able to diagnose these diseases are able to take actions on it.But for farmers who are not able to identity take improper actions.This destroys all the crops.At last we see there is huge loss of time, money and labour. Analysing the problem which farmers have been facing of years, we needed to come up with solution in which human interaction is minimal.Smart farming have already made its place in the society, to add to that we have come up with this improvised smart farming technique.Smart Farming Stick (SFS) by using these techniques our system will work as a guide, to assist the farmers by giving information.Farming is about risk calculation – But what if the risk can be calculated and cured beforehand.Analysis can help you with identifying the weakness and strength of the soil, resulting in more revenue generation and saving ample amount of time. Automated solutions and technology offer greater accuracy based on more efficient data collection and monitoring.
 Other: Forest (Biodiversity) conservation
Other: Forest (Biodiversity) conservation
AP044 »
Background: From past decade, ecological imbalance is causing huge impact on biodiversity of the planet earth. To ensure sustainable future for our next generations, biodiversity conservation is an important task. According to the FAO's Global Forest Resources Assessment 2020, the world has a total forest area of 4.06 billion hectares (10.0 billion acres), which is 31% of the total land area. More than half (54%) of the world's forests is found in only five countries (Brazil, Canada, China, Russia and the USA). One among the major reasons of ecological imbalance is caused by wildfires. Human caused wildfires (Global warming, Electric line & Camp fire) and Natural wildfires (Lightning, Thunderstorms & Dead trees rubbing) are the types of wildfires. The wildfires in the above listed countries have greater impact globally. Uncontrolled wildfires cause huge threats. Fast spreading wildfires take lot of time to combat and result in huge loss of flora and fauna of the particular region and thus cause ecological imbalance. On average, more than 100,000 wildfires clear 9-10 million acres (3.6-4 million hectares) of land in the world every year. In recent years, wildfires have destroyed 12-13 million acres (4.8-5 million hectares) of land. Furthermore, there are ecological, economical & social impacts as well. Wildfires also causes rise in Global warming & respiratory disorders. There have been lot of concerns and discussions regarding this recently and the researchers are still in the process to find effective and ecofriendly, cost effective approaches to prevent and detect the occurrence of wildfire. At present there are systems that are practically implemented to detect the wildfire. These systems successfully detect forest fire but are inefficient to prevent them in advance. These systems are failing miserably to combat wildfires. Hence there is a need to raise a concern regarding the prevention of wildfire by observing the climate changes in the region and monitoring the forests. We believe our approach to this problem helps in addressing this global concern to help conserve the rich culture of wildlife.
 Water Related
Water Related
AP062 »
Over-Watering and Under-Watering are the two concern-able scenarios actively addressing the water conservation which is one of the major global challenges. There are trained gardeners who can water the plants regularly and maintain the gardens and other landscape plants effectively. But how much we control the water wastage from human hands while watering plants, there is a considerable error happening always, and we can control it by autonomous systems. Project "Green-Globe" is our idea to create some momentum in addressing this issue. We're focusing to develop an authentic system with using which we can utilize the natural resources ( i.e., Water) properly to grow the plants effective and efficiently. So, the idea is to develop an autonomous irrigation system to water plants with which we can automatically water the plants by understands and calculating the primary parameters like plant genetic information, moisture in the soil, humidity in atmosphere and secondary parameters like temperature and electrical conductivity of soils. The realistic approach of our project comes in a long run, but it will create a benchmark for the initiation of connecting the edge technology of INDUSTRY 4.0 with global challenges of today. Project Green-Globe delivers the essential requirement i.e., growing the plants effectively and efficiently by regulating the Over-Watering and Under-Watering. The outcome also addresses to saving the water and conscious usage of the water while watering plants at houses and other areas.
The developed system is able to regulate the water wastage, and is able develop ML and AI models from understanding the plant's genetic information and the rate of it's growth, and also using climatic conditions which were collected via Internet APIs and cloud. The developed models helps to perform better autonomous irrigation methods, and could also be helpful at concepts of terraforming other planets.
 Smart City
Smart City
AP080 »
Plastic pollution has become one of the most pressing environmental issues, as rapidly increasing production of disposable plastic products overwhelms the world’s ability to deal with them. Plastic pollution is most visible in developing Asian and African nations, where garbage collection systems are often inefficient or nonexistent. But the developed world, especially in countries with low recycling rates, also has trouble properly collecting discarded plastics. Plastic trash has become so ubiquitous it has prompted efforts to write a global treaty negotiated by the United Nations.
Did you know that every plastic that is being produced in the world still exists today? Half of all plastics ever manufactured have been made in the last 15 years.Millions of animals are killed by plastics every year, from birds to fish to other marine organisms. Nearly 700 species, including endangered ones, are known to have been affected by plastics. Nearly every species of seabird eats plastics.There is no natural process to degrade plastic but we can recycle them.so, we wanted to design our bot to collect and dump them into the trash.
 Health
Health
AP085 »
Every citizen has their basic rights to live a healthy and independent life likewise the blind and partially sighted people should lead their lives independently.
Through our project we aim to help the blind and visually impaired people which makes them independent to a certain extent. The aim is to use the FPGA and Microsoft cloud to build a prototype of the device. The idea is to guide the individual by giving the necessary instructions to reach their location and also by using image processing techniques, the device will be able to convert the text to speech which makes him/her independent to the most extent. Earlier there are projects which are aimed at obstacle avoidance using Ultrasonic sensors whose range is not good enough to roam on the roads. There are also projects which need implantation of electronic chips in the visual cortex to make the blind people see but the implantation is expensive which needs highly skilled surgeons. Our Prototype plan includes the glasses , blue tooth pen-cam and headphones.
So we want to design a cost effective and portable device which performs the 3 tasks:
1.OBSTACLE AVOIDING
2. READING THE TEXT THE DEVICE HAS CAPTURED WITH PERMISSION OF THE USER.
3. NAVIGATION SYSTEM AND SAVE DATA ABOUT THE FREQUENTLY VISITED LOCATIONS AND GUIDE THEM IN FUTURE.{ i.e the device has to be trained to save the frequently visited locations such as workplace, hospital etc.,.}
 Water Related
Water Related
AP086 »
Water is a vital factor in human life and for the existence of other habitats. Easy access to safe water for drinking, domestic use, food and production is a civic health requirement. Therefore, maintaining a water quality balance is very essential for us. Otherwise, it causes serious health problems to humans. Water contamination has been studied as one of the leading causes of death and illness in the world. Many people die from contaminated water every year. One reason is that public and government ignorance and the absence of water quality checking systems cause severe medical issues.Water contamination is also a serious issue in industries, irrigation and aquaculture.
Traditionally, water quality detection is done manually when water samples are taken and sent to the laboratory, but this process requires a lot of time, cost, and human resources. These techniques do not provide real-time data. By considering these challenges, we have come up with an idea to design a Water quality analyzer to check the quality of the water used for different purposes.
The Process starts from taking the real time data from the water bodies using sensors and type of water need to be checked must be selected from the mobile app. FPGA Board processes the collected data and compares it with the standard data in order to assess the water quality.The quality parameters of the water and the quality of the water will be sent to the mobile app using IoT Technology. If the quality of the water is below the desired levels, an alert will be sent to the user. In this way we can have continuous real time water monitoring.
 Autonomous Vehicles
Autonomous Vehicles
AP087 »
In recent years, international socioeconomic development and medical reforms have permitted the medical industry to move toward true "intelligence". The outstanding developments in medical technology have helped people overcome many challenges in life. Especially, during the global pandemic of COVID-19, besides the development of vaccines, the application of advanced technical technologies also helps people slow down the increase of the disease. The incorporation of greater artificial intelligence, internet of things in to develop robots that automatically disinfect the air and surfaces of hospital environments can help reduce the human resources spent on environmental cleaning and disinfection and minimize the risk of occupational exposure for staff. These robots also facilitate informatized management of environmental disinfection, reduce costs, and increase the efficiency of disinfection efforts.
In this study, we propose to deploy a type of autonomous disinfection robot with the ability to automate tasks such as: Automatic scene recognition and disinfection; Automatic movement and avoids obstacles; Collect patient's body temperature and blood oxygen to assist in building a chart to monitor the patient's health automatically.
The autonomous disinfection robot applies AI algorithms and robotic technology to the field of hospital disinfection. In essence, the model is a disinfection robot with a high level of independent self-sensing AI. The robot model uses intelligent scene recognition, independent sensing in the disinfection process, real-time disinfection process monitoring, intelligent planning, independent execution, and evaluation of the results. An intelligent disinfection robot can compensate for the shortcomings of existing disinfection methods, improve the quality of disinfection, and reduce the probability of infection.
 Food Related
Food Related
AP089 »
According to the Food and Agriculture Organization (FAO) of the United Nations, one third of the food produced is wasted and the financial costs of food waste in the world could total to USD 1 trillion each year. According to United Nations Environment Programme (UNEP), approximately 1.3 billion tonnes of food is wasted annually. Besides, Asia produces 50% of global food waste with China, Japan and South Korea alone contributed to 28% of the global disposed food. According to the Future Directions International (FDI), South and Southeast Asia on the other hand contributed to 25% of global food waste. In Malaysia, the food waste produced is 2,921,577 tonnes per year from households alone. This is equivalent to 91 kg of food waste per capita per year generated in Malaysia. This is concerning since Malaysia is the highest country to produce the amount of food waste among Southeast Asia countries.
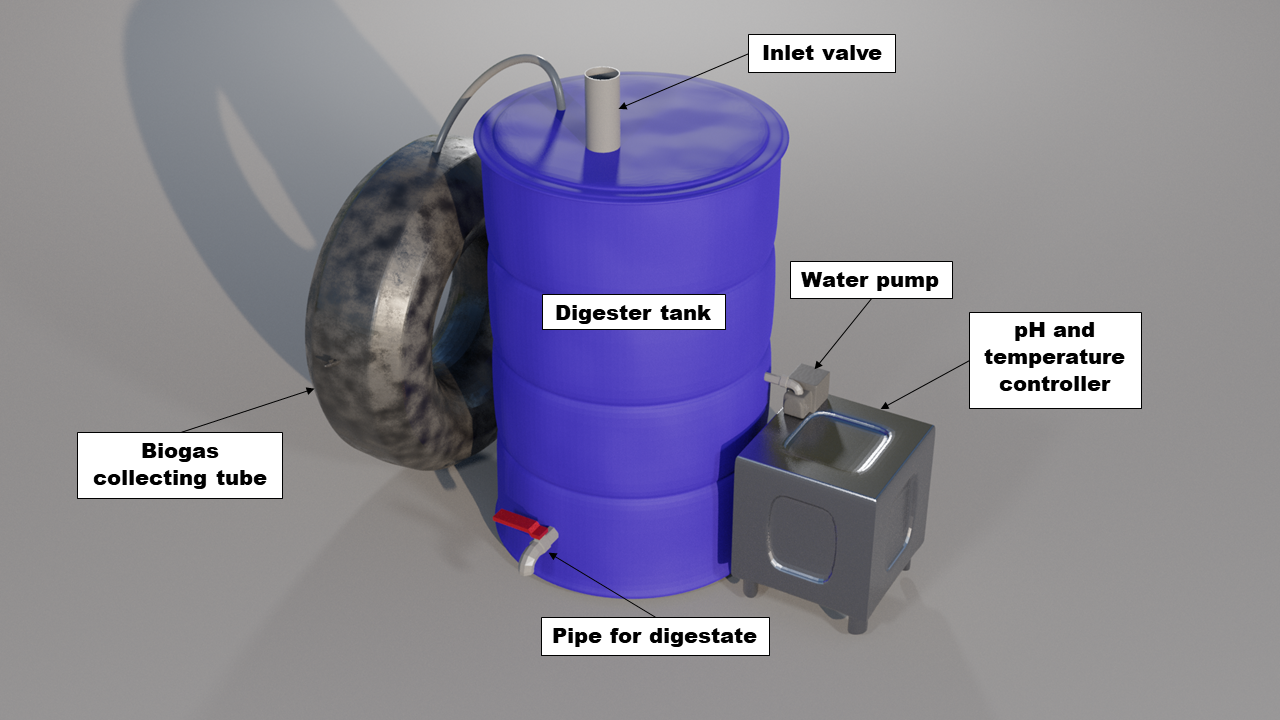
To address the problem of excessive food waste in Malaysia, biogas could be a solution. Biogas is a renewable energy source produced by the breakdown of organic matter such as food waste to produce mainly methane and carbon dioxide gases which are environmentally friendly. Another end product which is the digestate can also be used as fertilizers since it is rich in nutrients. Globally, coal and natural gases are mainly used to generate electricity – even cooking. With the used of biogas to occasionally replace these two resources is seemed to be more sustainable since biogas is renewable energy – more resources could be saved.
In line with the aim of this year's InnovateFPGA competition, which is "Enabling the Edge for a Sustainable Future", a mini biogas plant with AI monitoring features capable of producing methane gas from food waste through Anaerobic Digestion (AD) is proposed under the food waste category to help address the problem of excessive food waste particularly in Malaysia. This mini biogas plant will be smaller compared to the other biogas powerplant in industry which means it is also portable and just can be put in the backyard. All the food waste generated daily in the household could be ‘reused’ for two main purposes: heating (for cooking) and electricity. Several key parameters are affecting the AD process: pH, temperature, C/N ratio, Volatile Fatty Acids etc. The use of FPGA in this project is to provide an Artificial Intelligence (AI) implementation to the system to optimize the biogas yield from the food waste by controlling the pH and the temperature.