 Water Related
Water Related
project Green-Globe
AP062 »
Over-Watering and Under-Watering are the two concern-able scenarios actively addressing the water conservation which is one of the major global challenges. There are trained gardeners who can water the plants regularly and maintain the gardens and other landscape plants effectively. But how much we control the water wastage from human hands while watering plants, there is a considerable error happening always, and we can control it by autonomous systems. Project "Green-Globe" is our idea to create some momentum in addressing this issue. We're focusing to develop an authentic system with using which we can utilize the natural resources ( i.e., Water) properly to grow the plants effective and efficiently. So, the idea is to develop an autonomous irrigation system to water plants with which we can automatically water the plants by understands and calculating the primary parameters like plant genetic information, moisture in the soil, humidity in atmosphere and secondary parameters like temperature and electrical conductivity of soils. The realistic approach of our project comes in a long run, but it will create a benchmark for the initiation of connecting the edge technology of INDUSTRY 4.0 with global challenges of today. Project Green-Globe delivers the essential requirement i.e., growing the plants effectively and efficiently by regulating the Over-Watering and Under-Watering. The outcome also addresses to saving the water and conscious usage of the water while watering plants at houses and other areas.
The developed system is able to regulate the water wastage, and is able develop ML and AI models from understanding the plant's genetic information and the rate of it's growth, and also using climatic conditions which were collected via Internet APIs and cloud. The developed models helps to perform better autonomous irrigation methods, and could also be helpful at concepts of terraforming other planets.
 Water Related
Water Related
Water Quality Analyzer
AP086 »
Water is a vital factor in human life and for the existence of other habitats. Easy access to safe water for drinking, domestic use, food and production is a civic health requirement. Therefore, maintaining a water quality balance is very essential for us. Otherwise, it causes serious health problems to humans. Water contamination has been studied as one of the leading causes of death and illness in the world. Many people die from contaminated water every year. One reason is that public and government ignorance and the absence of water quality checking systems cause severe medical issues.Water contamination is also a serious issue in industries, irrigation and aquaculture.
Traditionally, water quality detection is done manually when water samples are taken and sent to the laboratory, but this process requires a lot of time, cost, and human resources. These techniques do not provide real-time data. By considering these challenges, we have come up with an idea to design a Water quality analyzer to check the quality of the water used for different purposes.
The Process starts from taking the real time data from the water bodies using sensors and type of water need to be checked must be selected from the mobile app. FPGA Board processes the collected data and compares it with the standard data in order to assess the water quality.The quality parameters of the water and the quality of the water will be sent to the mobile app using IoT Technology. If the quality of the water is below the desired levels, an alert will be sent to the user. In this way we can have continuous real time water monitoring.
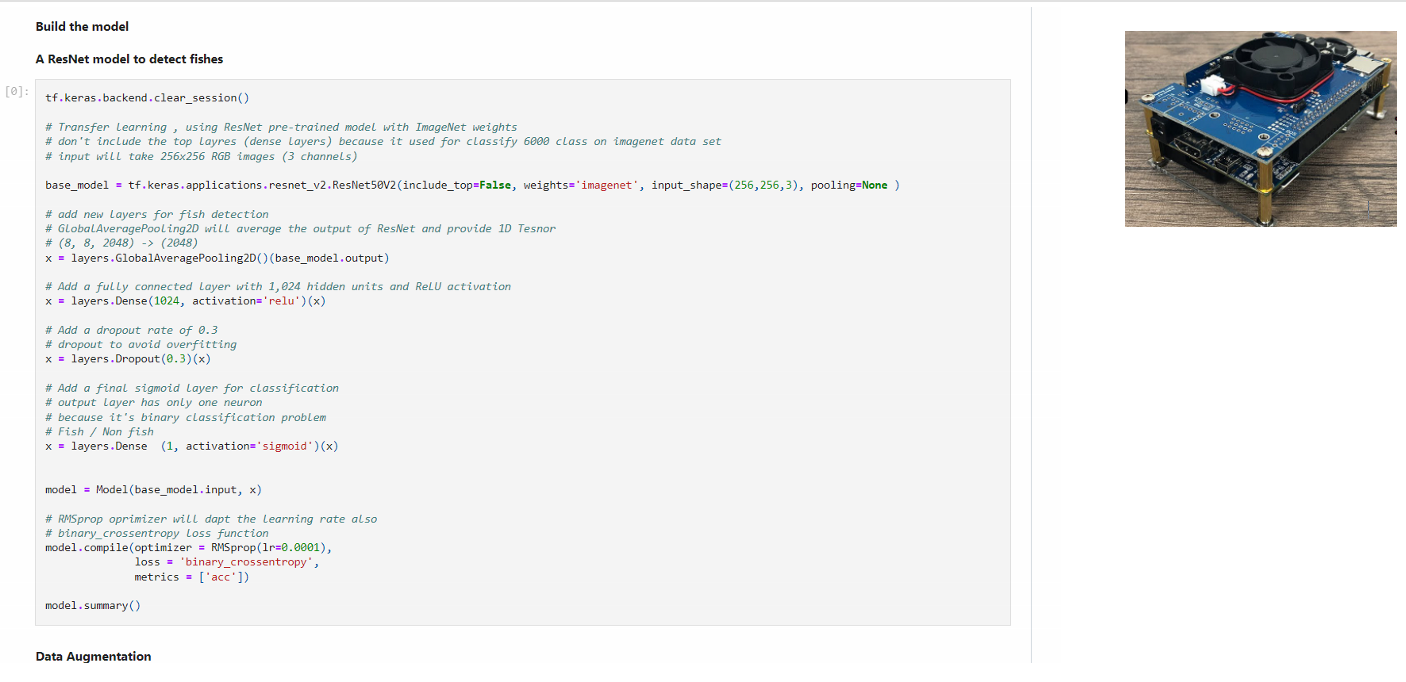 Water Related
Water Related
sustainable fishery
AP014 »
Our venture is coming up with the cutting edge End-to-End product which can help the marine species and over a 5-10 years course wild capture would be rejuvenated naturally with the ultimate solution what we offer with the existing Hardware/Software but integrating and applying it for a unique way.
Blind Fishing and overfishing has made the marine resources / wild capture as no longer a bottom less fishing.
This overfishing put a trouble to 1/3 of world population especially the under-developed and developing countries who rely ocean as their cheap protein.
 Water Related
Water Related
Sustainability and Productivity Enhancement IoT system for Agriculture
AP064 »
The project vision is to create a modulo IoT network that could be easily modified and applied onto various types of farms and greenhouses to help optimize water use, give insights, and impact the health of crops and the surrounding environment. Hence, increase the quality of the product going to the market and reduce the wastes that will contribute to long-term sustainability.
An IoT network will include a master node made of the FPGA Cloud Connectivity Kit, which will be responsible for collecting data from the sensor nodes, communicating with the cloud along with controlling the actuators that will affect a specific crop on the field.
Each Sensor Node will have its own MCU connected with a Soil Moisture and pH Measurement sensor (CN0398), a Volatile Organic Compound (VOC) Detector (CN0395), the Light Recognition System (CN0397), and potentially any other sensors that the customer requests. The data collected from these sensors will be transmitted to the Master node through wired RS485, wireless LoRa, LoRaWAN or other local transmitting methods (depends on specific setup). The moisture data collected will be used to control a watering pump through an isolated Contactor. pH or other soil qualities data can be statistically displayed to give the user insight into what should be adjusted to the fertilizer. Moreover, the VOC and Light data can be used to conditioning airflow in the greenhouse and changing lighting components to provide the best environment for the crops to thrive.
The cloud-based service will be in contact with the master node to connect the user from anywhere around the world to monitoring and controlling their farm. Besides, the cloud is also responsible for updating the system's firmware Over-The-Air (OTA) and store the processed data from the FPGA for further analysis and future improvement.
If time permits, edge computing Machine Learning will also be applied to the master node to automatically control the watering, lighting and air ventilating based on the crop that is being monitored, hence reduce the network bandwidth, contribute to the long-term energy efficiency compared to applications that do most calculating on the cloud. This network can be scaled up with many Master Nodes, each responsible for specific crops in a greenhouse or a farm, connected all together and monitored by the cloud or by a local Grant Master Node. We are expected to test the system on a greenhouse facility in Vietnam after finishing the prototype, which will give us a better insight into how the system operates.
Through the project, besides expecting to learn a heap of new useful knowledge, our team hopes to create a foundation for improving the efficiency of watering and energy usage in agriculture, especially in developing countries such as our hometown Vietnam.
 Water Related
Water Related
Smart Water Conservation System
AP046 »
The project is aimed to improve water distributor's capacity so everyone can use water even during dry and drought season.
 Water Related
Water Related
Sustainable Aquaphonics
AP048 »
Singapore is a highly industrialized country which is one of the top countries with high population density. Trees and vegetation can be found in every block but is limited in every multi-storey residential building like HDBs and Condominiums. The projects aims to promote local hdb/condo residents to implement and improve their existing aquariums into a sustainable aquaponics which helps to reduce the carbon footprint and reduce the water usage.
Water Related
Smart irrigation system for dense crops using FPGA
AP081 »
The main focus is on a smart irrigation system which is a vital need in today’s world. The twenty-first century deals with technology and automation, making our lives easier, adaptable, and cost-effective. In our country, India is divided into two groups of people, the agro-based farmers whose livelihood depends on food production and on the other side the consumers who depend solely on the consumption of food produced by the farmers. Both have an interdependent link. India an agriculture-based country, it is very important that the methods used for agriculture are efficient to satisfy the increasing demand. This led to the origination of smart irrigation system which is one of the smartest methods used in agriculture. It provides an automatic irrigation of crop fields and does not require human involvement. It keeps the track of the water level as well as soil moisture content. This ensures the proper and healthy growth of plants. The major factor involving agriculture is the depletion of water which keeps on increasing day by day. The smart irrigation system also resolves this issue as the water is conserved by the automated water system consisting of a sensor that senses the climatic data such as humidity, soil moisture, and water level. The agriculture field is irrigated based on this data and water flow.
Water Related
IOT based Smart Agriculture
AP122 »
The Continuously increasing demand of the food necessitates the rapid improvement in food production technology. In most of the developing countries, the national economy mainly depends on the Agriculture. But these countries do not able to make proper use of agricultural resources due to the high dependency on rain. Nowadays different irrigation systems are used to reduce the dependency of the rain and mostly the existing irrigation systems are driven by electrical power and manually ON or OFF scheduling controlled. The proposed system is usually designed for ensuring the proper level of water for growing up the plants all through the season. In addition, it provides maximum water usage efficiency by monitoring soil moistures at optimum level and it saves the electrical energy by turning off the motor when there is no water in the pump. The traditional methods are not efficient in controlling the illegal entry and it requires more labour work and time etc.
Water Related
Monitoring and Predicting Urban Water Reservoirs
AP135 »
Water scarcity is a global crisis which is faced by many countries across the world. It is one of the most serious risk faced by the world at different sector(social, economic, political and environmental). Around 1.2 billion people, or almost one-fifth of the world's population, live in areas of water scarcity, and 500 million people are approaching this situation. Another 1.6 billion people, or almost one quarter of the world's population, face economic water shortage (where countries lack the necessary infrastructure to take water from rivers and aquifers).
Water Related
sustainable fishing
AP005 »
Our project is coming up with the cutting edge End-to-End product which can help the marine species and over a 5-10 years course wild capture would be rejuvenated naturally with the ultimate solution what we offer with the existing Hardware/Software but integrating and applying it for a unique way.
Water Related
Design and Development of FPGA based Smart Sensors for Water Quality Analysis
AP025 »
Water is indispensable for the survival of every life. It needs to be protected and preserved for generations to come. Water harvesting and inadequate management of this natural resource will also contribute to its contamination. The prevention of fluorosis, a chronic illness resulting from excessive fluoride consumption, requires monitoring of all water sources in underground chloride tanneries in endemic areas. The deployable field color analyzer based on design low cost, smart sensors based on portable devices for determining chloride and lead in water. DE10-Nano Cyclone V SoC FPGA Board based set-up has been built for access through mobile apps and display the concentration of the measured sample. It has the advantages of the Internet of Things (IoT) for real-time deployment and continuous monitoring. The smart sensors developed can be integrated with it for continuous tracking of chloride, lead measurement and water quality.
Water Related
Water contamination detection
AP100 »
Water purity identificationand detection